多项式回归初探及实践
多项式回归初探及实践
起因
学弟这学期在上数模课,这次的作业是 根据 2000~2021年的人口数量,估计22年的人口数。换言之,就是给你一部分的训练数据,需要拟合出一个曲线,以此来测试另外的数据。
这不是机器学习入门的回归嘛,就来了劲了 玩一玩~
准备工作
emm,因为某些原因,学弟选择了六次多项式,那我也就训练一只六次多项式;
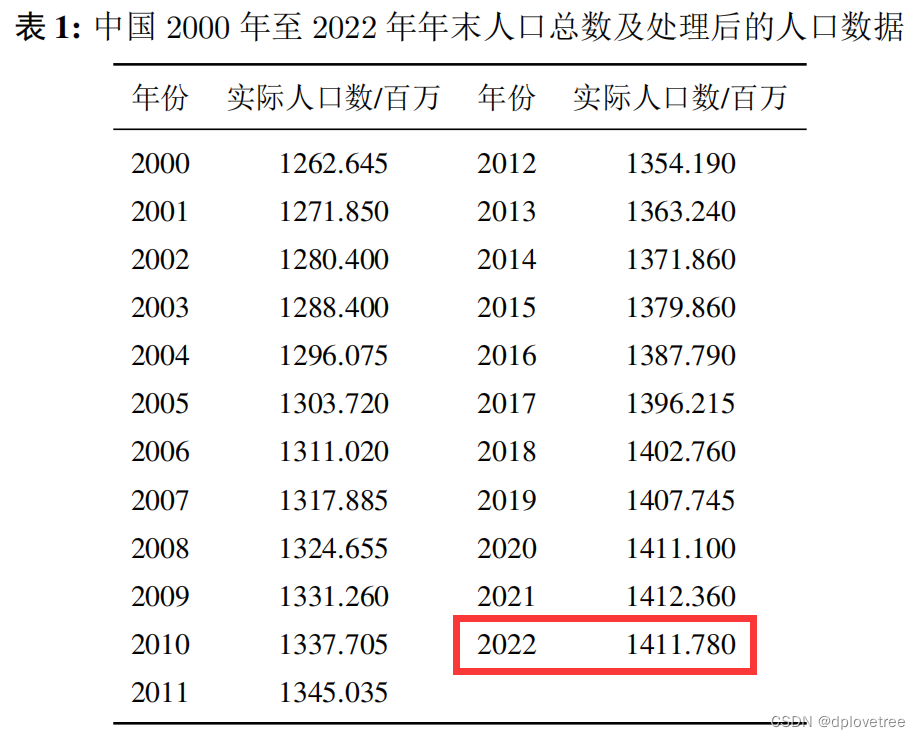
首先,数据如下,其中红色框框为测试数据,其余部分为训练数据:
首先,训练一元多项式,如下:y=f(x)=θ0+θ1x+θ2x2+...+θnxny=f(x)=\theta_0+\theta_1x+\theta_2x^2+...+\theta_nx^ny=f(x)=θ0+θ1x+θ2x2+...+θnxn
采用的损失函数是均方误差MSE:J(θ)=1m∑i=1m(f(x(i))−y(i))2J(\theta)=\frac{1}{m}\sum_{i=1}^{m}{(f(x^{(i)})-y^{(i)})^2}J(θ)=m1∑i=1m(f(x(i))−y(i))2
并使用梯度下降的方法,对于参数 θ\thetaθ 的梯度为:
∂J∂θj=1m∑i=1m(f(x(i))−y(i))xj(i)\frac{\partial J}{\partial \theta_j}=\frac{1}{m}\sum_{i=1}^{m}{(f(x^{(i)})-y^{(i)})x_j^{(i)}} ∂θj∂J=m1i=1∑m(f(x(i))−y(i))xj(i)
所以,参数更新方程为:
θj=θj−η∂J∂θj=θj−ηm∑i=1m(f(x(i))−y(i))xj(i)\theta_j=\theta_j-\eta\frac{\partial J}{\partial \theta_j}=\theta_j-\frac{\eta}{m}\sum_{i=1}^{m}{(f(x^{(i)})-y^{(i)})x_j^{(i)}} θj=θj−η∂θj∂J=θj−mηi=1∑m(f(x(i))−y(i))xj(i)
我使用了随机梯度下降法,参数更新如下:
θj=θj−η∂J∂θj=θj−η(f(x(k))−y(k))xj(k)\theta_j=\theta_j-\eta\frac{\partial J}{\partial \theta_j}=\theta_j-\eta(f(x^{(k)})-y^{(k)})x_j^{(k)} θj=θj−η∂θj∂J=θj−η(f(x(k))−y(k))xj(k)
同时,还把数据进行了标准化,加速参数的迭代:z(i)=x(i)−μσz^{(i)}=\frac{x^{(i)}-\mu}{\sigma}z(i)=σx(i)−μ,其中 μ\muμ为训练样本的均值,σ\sigmaσ为训练样本的标准差;
训练!
因为是六次函数,学习率太高会导致很容易跳出去,这里我采用的是1e−51e^{-5}1e−5,误差较小的同时,训练速度也不是很慢;
import numpy as np
import matplotlib.pyplot as plttrain=np.loadtxt('1.csv', delimiter=',', skiprows=1)
train_x=train[:,0]
train_y=train[:,1]theta=np.random.rand(7)def to_matrix(x):return np.vstack([np.ones(x.shape[0]),x,x**2,x**3,x**4,x**5,x**6]).Tdef f(x):return np.dot(x,theta)mu=train_x.mean() #获取平均值
sigma=train_x.std() #获取标准差def standardize(x):return (x-mu)/sigmadef MSE(x,y): #均方误差return (1/x.shape[0])*np.sum((y-f(x))**2)train_x=standardize(train_x)X=to_matrix(train_x) #矩阵化plt.plot(train_x,train_y,'o')
plt.show()ETA=1e-5 #学习率
diff=1 #误差的差值
count=0 #更新次数errors=[] #均方误差的历史记录
errors.append(MSE(X,train_y))while diff>1e-5:p=np.random.permutation(X.shape[0])for x,y in zip(X[p,:],train_y[p]):theta=theta-ETA*(f(x)-y)*xerrors.append(MSE(X,train_y))diff=errors[-2]-errors[-1]count+=1log='第{}次: theta={}, 差值={:.4f}'print(log.format(count, theta, diff))x=np.linspace(-2,2,100)
plt.plot(train_x,train_y,'o')
plt.plot(x,f(to_matrix(x)))
plt.show()
print(MSE(X, train_y))
p=[22]
print(f(to_matrix(standardize(p))))
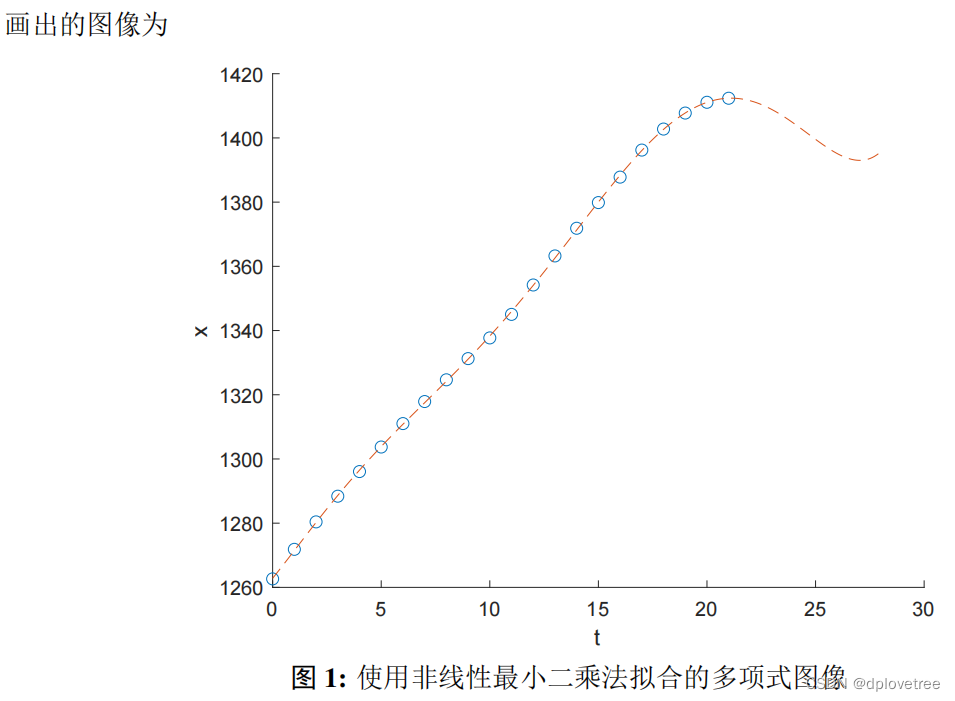
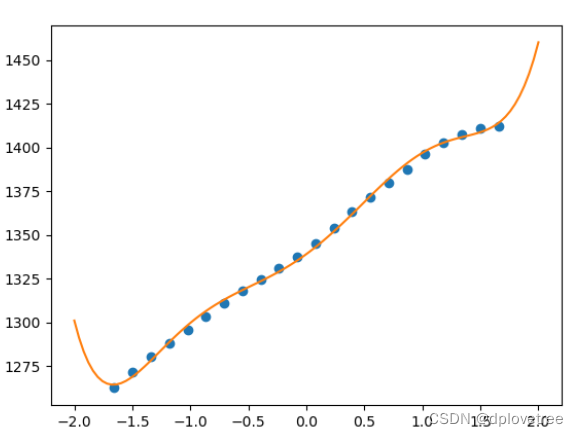
最后拟合出来的图形,如下:
最后的 θ\thetaθ参数,以及MSE和2022年的预测人口如下:
第1337659次: theta=[ 1.33911935e+03 4.85124258e+01 2.69310404e+01 8.74366182e-01-2.21498077e+01 -7.65711382e-01 4.50309967e+00], 差值=0.0000
MSE=3.8565485574153895
2022=[1426.37429178]
2022年的人口预测误差为:0.01033751135446032667979430222839
正则化
考虑到误差还是在1%左右,并且图形只在训练数据邻域内拟合的不错,猜测大概率出现了过拟合的情况;
所以采用正则化的方式,降低过拟合度:
向上面所使用的目标函数加入下面的正则化项:R(θ)=λ2∑j=1mθj2R(\theta)=\frac{\lambda}{2}\sum_{j=1}^{m}\theta_j^2R(θ)=2λ∑j=1mθj2
即:
J(θ)=1m∑i=1m(f(x(i))−y(i))2+λ2∑j=1mθj2J(\theta)=\frac{1}{m}\sum_{i=1}^{m}{(f(x^{(i)})-y^{(i)})^2}+\frac{\lambda}{2}\sum_{j=1}^{m}\theta_j^2 J(θ)=m1i=1∑m(f(x(i))−y(i))2+2λj=1∑mθj2
因为θ0\theta_0θ0只有参数,被称为偏置项,故不对他进行正则化,λ\lambdaλ是决定正则化影响程度的正的常数,这个值需要自己定。
正则化项的微分如下:
∂R(θ)∂θj=λθj\frac{\partial R(\theta)}{\partial \theta_j}=\lambda\theta_j ∂θj∂R(θ)=λθj
因此,当前的参数更新方程为:
θj=θj−η(∂J∂θj+λθj)=θj−η(1m∑i=1m(f(x(i))−y(i))xj(i)+λθj)\theta_j=\theta_j-\eta(\frac{\partial J}{\partial \theta_j}+\lambda\theta_j)=\theta_j-\eta(\frac{1}{m}\sum_{i=1}^{m}{(f(x^{(i)})-y^{(i)})x_j^{(i)}}+\lambda\theta_j) θj=θj−η(∂θj∂J+λθj)=θj−η(m1i=1∑m(f(x(i))−y(i))xj(i)+λθj)
import numpy as np
import matplotlib.pyplot as plttrain=np.loadtxt('1.csv', delimiter=',', skiprows=1)
train_x=train[:,0]
train_y=train[:,1]theta=np.random.rand(7)def to_matrix(x):return np.vstack([np.ones(x.shape[0]),x,x**2,x**3,x**4,x**5,x**6]).Tdef f(x):return np.dot(x,theta)mu=train_x.mean() #获取平均值
sigma=train_x.std() #获取标准差def standardize(x):return (x-mu)/sigmadef MSE(x,y): #均方误差return (1/x.shape[0])*np.sum((y-f(x))**2)train_x=standardize(train_x)X=to_matrix(train_x) #矩阵化plt.plot(train_x,train_y,'o')
plt.show()# ETA=0.00011 #学习率
ETA=0.00004 #学习率
diff=1 #误差的差值
count=0 #更新次数
LAMBDA=0.00661 #正则化常量errors=[] #均方误差的历史记录
errors.append(MSE(X,train_y))while diff>1e-5:#正则化项,偏置项不用正则化,所以用常量reg_term=LAMBDA*np.hstack([0,theta[1:]])p=np.random.permutation(X.shape[0])for x,y in zip(X[p,:],train_y[p]):theta=theta-ETA*((f(x)-y)*x+reg_term)errors.append(MSE(X,train_y))diff=errors[-2]-errors[-1]count+=1log='第{}次: theta={}, 差值={:.4f}'print(log.format(count, theta, diff))x=np.linspace(-2,2,100)
plt.plot(train_x,train_y,'o')
plt.plot(x,f(to_matrix(x)))
plt.show()
print(MSE(X, train_y))
p=[22]
print(f(to_matrix(standardize(p))))
通过调整λ\lambdaλ和学习率η\etaη,当前得到的结果如下:
第232154次: theta=[1341.30275915 43.84239659 13.91964783 6.33130563 -10.04948196-2.18130811 1.65564268], 差值=0.0000
MSE=1.5442272555955348
2022=[1411.76770428]
拟合出的图像如下:
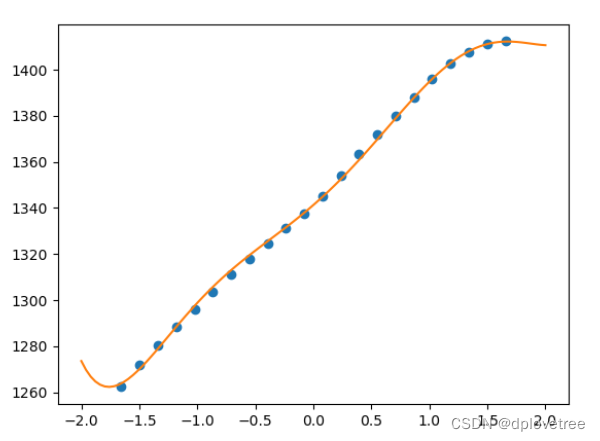
2022年的人口预测误差为:-0.00087093739817818640298063437646092%
我采用了L2正则化法,通过抑制参数的影响,从而减少过拟合;也可以通过L1正则化法,把多次函数,去掉没用的高次项,变为更简单的函数来减少过拟合。
完结撒花~
也算是顺利完成了叭 真棒
附
学弟用的最小二乘法,通过解方程来获得参数,精度比我的好,他的MSE很小(没办法,迭代只能近似,毕竟后面的梯度太小了,再多次的迭代作用也不大)
这里附上他的推导过程吧,有兴趣可以学习一下: