Linux-scheduler之负载均衡(二)
四、调度域
SDTL结构
linux内核使用SDTL结构体来组织CPU的层次关系
struct sched_domain_topology_level {sched_domain_mask_f mask; //函数指针,用于指定某个SDTL的cpumask位图sched_domain_flags_f sd_flags; //函数指针,用于指定某个SDTL的标志位int flags; int numa_level;struct sd_data data;
#ifdef CONFIG_SCHED_DEBUGchar *name;
#endif
};
标志位
#define SD_BALANCE_NEWIDLE 0x0001 /* Balance when about to become idle */
#define SD_BALANCE_EXEC 0x0002 /* Balance on exec */
#define SD_BALANCE_FORK 0x0004 /* Balance on fork, clone */
#define SD_BALANCE_WAKE 0x0008 /* Balance on wakeup */
#define SD_WAKE_AFFINE 0x0010 /* Wake task to waking CPU */
#define SD_ASYM_CPUCAPACITY 0x0020 /* Domain members have different CPU capacities */
#define SD_SHARE_CPUCAPACITY 0x0040 /* Domain members share CPU capacity */
#define SD_SHARE_POWERDOMAIN 0x0080 /* Domain members share power domain */
#define SD_SHARE_PKG_RESOURCES 0x0100 /* Domain members share CPU pkg resources */
#define SD_SERIALIZE 0x0200 /* Only a single load balancing instance */
#define SD_ASYM_PACKING 0x0400 /* Place busy groups earlier in the domain */
#define SD_PREFER_SIBLING 0x0800 /* Prefer to place tasks in a sibling domain */
#define SD_OVERLAP 0x1000 /* sched_domains of this level overlap */
#define SD_NUMA 0x2000 /* cross-node balancing */
| SD_BALANCE_NEWIDLE | 当CPU变为空闲后做负载均衡调度 |
| SD_BALANCE_EXEC | 进程调用exec是会重新选择一个最优的CPU的来执行,参考sched_exec()函数 |
| SD_BALANCE_FORK | fork出新进程后会选择最优CPU,参考wake_up_new_task()函数 |
| SD_BALANCE_WAKE | 唤醒时负载均衡,参考wake_up_process()函数 |
| SD_WAKE_AFFINE | 支持wake affine特性 |
| SD_ASYM_CPUCAPACITY | 该调度域有不同架构的CPU,如大/小核cpu |
| SD_SHARE_CPUCAPACITY | 调度域中的CPU都是可以共享CPU资源的,描述SMT调度层级 |
| SD_SHARE_POWERDOMAIN | 该调度域中的CPU可以共享电源域 |
| SD_SHARE_PKG_RESOURCES | 该调度域中的CPU可以共享高速缓存 |
| SD_ASYM_PACKING | 描述SMT调度层级相关的一些例外 |
| SD_NUMA | 描述NUMA调度层级 |
| SD_SERIALIZE | |
| SD_OVERLAP | |
| SD_PREFER_SIBLING |
调度组是负载均衡的最小单位。
五、CPU调度域拓扑
CPU的调度域拓扑结构可以参考以下三张图(图来自互联网)
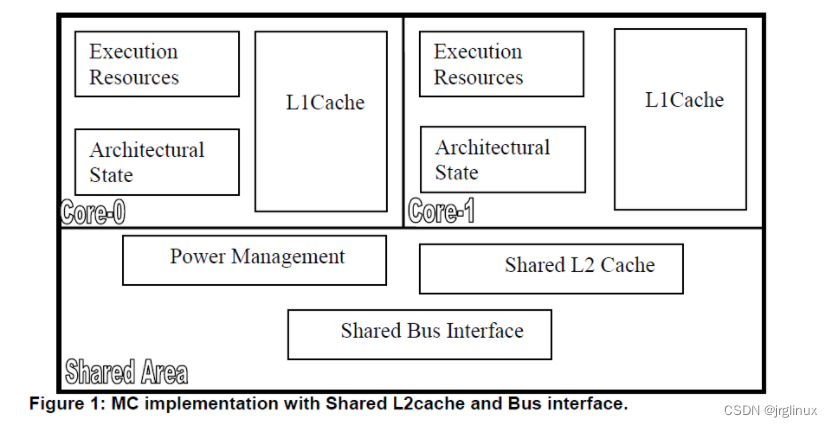
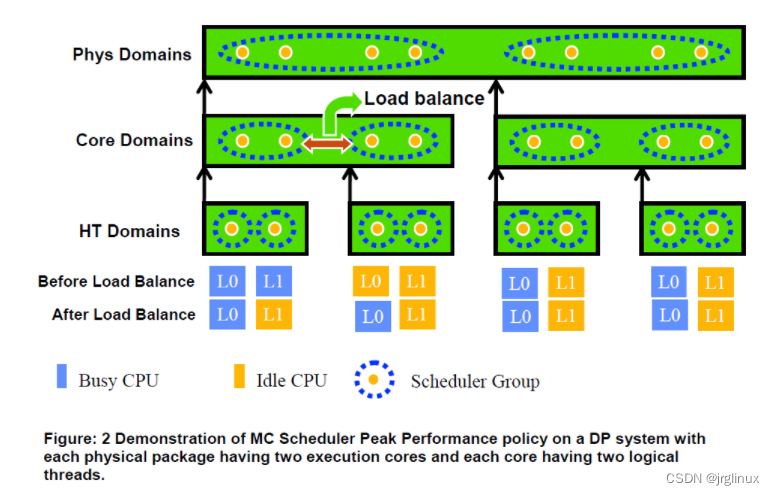
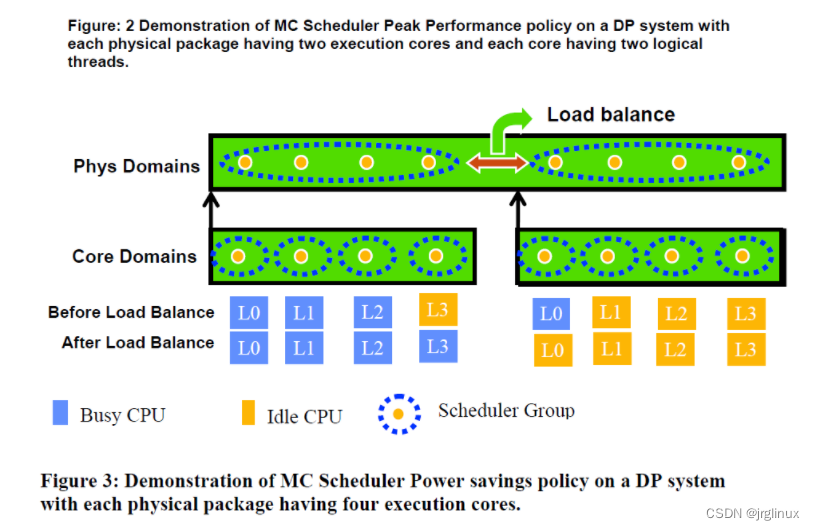
六、负载均衡
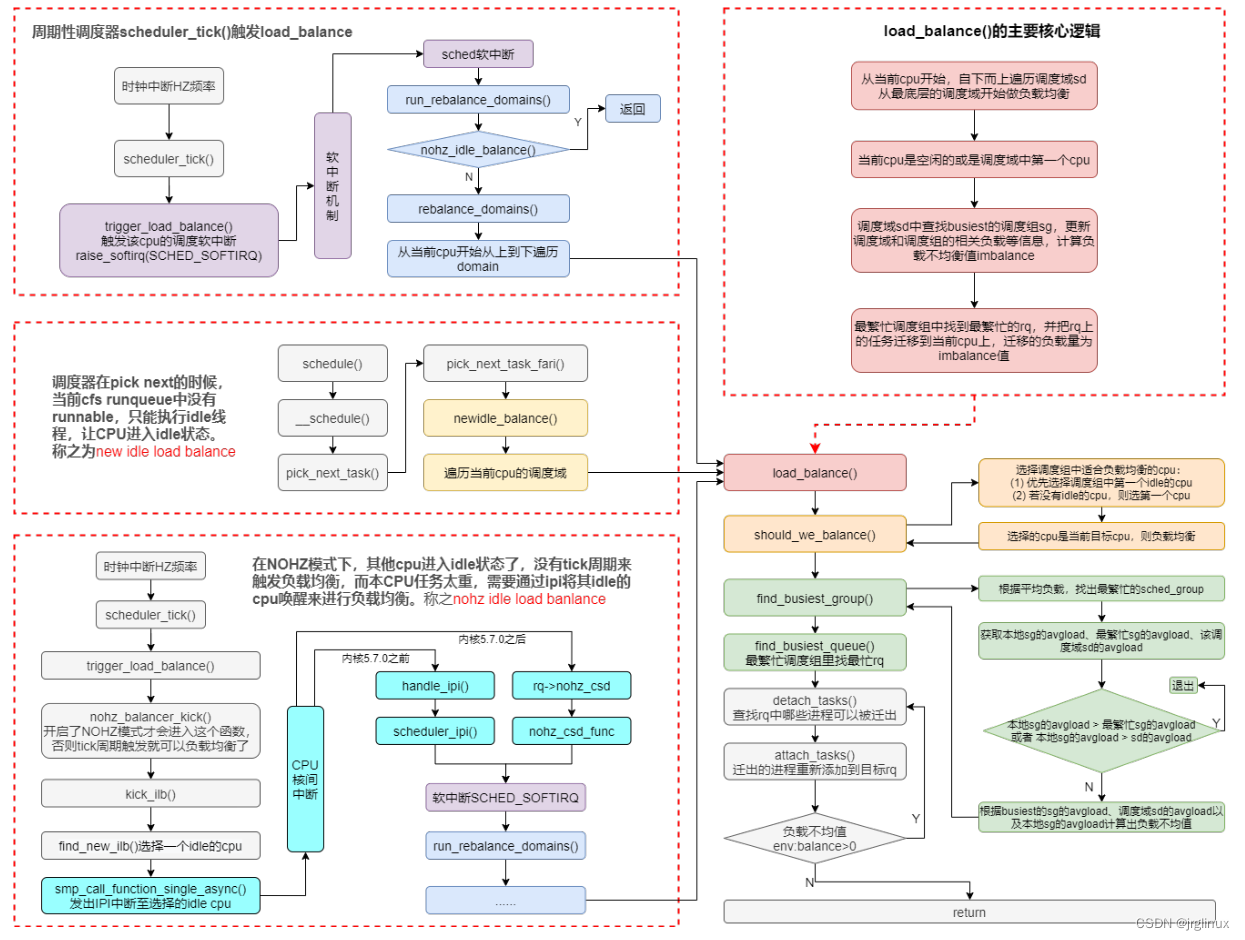
load-balance的逻辑比较复杂,可以参考我整理的如下图的整体逻辑框架:
lb_env()结构体
struct lb_env {struct sched_domain *sd;struct rq *src_rq;int src_cpu;int dst_cpu;struct rq *dst_rq;struct cpumask *dst_grpmask;int new_dst_cpu;enum cpu_idle_type idle;long imbalance;/* The set of CPUs under consideration for load-balancing */struct cpumask *cpus;unsigned int flags;unsigned int loop;unsigned int loop_break;unsigned int loop_max;enum fbq_type fbq_type;enum migration_type migration_type;struct list_head tasks;
};
| 类型 | 成员 | 作用 | |
|---|---|---|---|
| struct sched_domain * | sd | 指向当前调度域 | |
| int | dst_cpu | 当前CPU(后续可能要把任务迁移到该CPU上) | |
| struct rq* | dst_rq | 当前CPU对应的就绪度列 | |
| struct cpumask * | dst_grpmask | 当前调度域里的第一个调度组的CPU位图 | |
| unsigned int | loop_break | 表示本地最多迁移32个进程(sched_nr_migrate_break默认值是32) | |
| struct cpumask * | cpus | load_balance_mask位图 |
find_busiest_group()函数
首先是两个数据结构:
sd_lb_stats 用于描述调度域里的相关信息,以及sg_lb_stats用于描述调度组里的相关信息
/** sd_lb_stats - Structure to store the statistics of a sched_domain* during load balancing.*/
struct sd_lb_stats {struct sched_group *busiest; /* Busiest group in this sd */struct sched_group *local; /* Local group in this sd */unsigned long total_load; /* Total load of all groups in sd */unsigned long total_capacity; /* Total capacity of all groups in sd */unsigned long avg_load; /* Average load across all groups in sd */unsigned int prefer_sibling; /* tasks should go to sibling first */struct sg_lb_stats busiest_stat;/* Statistics of the busiest group */struct sg_lb_stats local_stat; /* Statistics of the local group */
};/** sg_lb_stats - stats of a sched_group required for load_balancing*/
struct sg_lb_stats {unsigned long avg_load; /*Avg load across the CPUs of the group */unsigned long group_load; /* Total load over the CPUs of the group */unsigned long group_capacity;unsigned long group_util; /* Total utilization over the CPUs of the group */unsigned long group_runnable; /* Total runnable time over the CPUs of the group */unsigned int sum_nr_running; /* Nr of tasks running in the group */unsigned int sum_h_nr_running; /* Nr of CFS tasks running in the group */unsigned int idle_cpus;unsigned int group_weight;enum group_type group_type;unsigned int group_asym_packing; /* Tasks should be moved to preferred CPU */unsigned long group_misfit_task_load; /* A CPU has a task too big for its capacity */
#ifdef CONFIG_NUMA_BALANCINGunsigned int nr_numa_running;unsigned int nr_preferred_running;
#endif
};
6.1 负载均衡机制的触发
负载均衡机制是从注册软中断开始的
6.1.1 软中断注册
__init void init_sched_fair_class(void)
{
#ifdef CONFIG_SMPopen_softirq(SCHED_SOFTIRQ, run_rebalance_domains);#ifdef CONFIG_NO_HZ_COMMONnohz.next_balance = jiffies;nohz.next_blocked = jiffies;zalloc_cpumask_var(&nohz.idle_cpus_mask, GFP_NOWAIT);
#endif
#endif /* SMP */
}void open_softirq(int nr, void (*action)(struct softirq_action *))
{softirq_vec[nr].action = action;
}
注册了SCHED_SOFTIRQ的软中断,中断处理函数是run_rebalance_domains。
6.1.2 软中断触发
由scheduler_tick()在每个时钟节拍中会去检查是否需要load balance。
/** Trigger the SCHED_SOFTIRQ if it is time to do periodic load balancing.*/
void trigger_load_balance(struct rq *rq)
{/* Don't need to rebalance while attached to NULL domain */if (unlikely(on_null_domain(rq)))return;if (time_after_eq(jiffies, rq->next_balance)) //需要判断是否到了负载均衡的时间点raise_softirq(SCHED_SOFTIRQ);nohz_balancer_kick(rq); //该函数作用是什么?
}
nohz_balancer_kick用来触发nohz idle balance的,这是后面两个章节要仔细描述的内容。这里看起似乎注释不对,因为这个函数不但触发的周期性均衡,也触发了nohz idle balance。然而,其实nohz idle balance本质上也是另外一种意义上的周期性负载均衡,只是因为CPU进入idle,无法产生tick,因此让能产生tick的busy CPU来帮忙触发tick balance。而实际上tick balance和nohz idle balance都是通过SCHED_SOFTIRQ的软中断来处理,最后都是执run_rebalance_domains这个函数。
七、exec进程
/** sched_exec - execve() is a valuable balancing opportunity, because at* this point the task has the smallest effective memory and cache footprint.*/
void sched_exec(void)
{struct task_struct *p = current;unsigned long flags;int dest_cpu;raw_spin_lock_irqsave(&p->pi_lock, flags); //这里获取了p->pi_lock,后面migration_cpu_stop中会涉及该锁dest_cpu = p->sched_class->select_task_rq(p, task_cpu(p), SD_BALANCE_EXEC, 0); //这里选择目的cpuif (dest_cpu == smp_processor_id()) //如果dest_cpu就是当前cpu,可以释放锁并返回goto unlock;if (likely(cpu_active(dest_cpu))) {struct migration_arg arg = { p, dest_cpu };raw_spin_unlock_irqrestore(&p->pi_lock, flags);stop_one_cpu(task_cpu(p), migration_cpu_stop, &arg); //这里进行目的cpu的进程迁移return;}
unlock:raw_spin_unlock_irqrestore(&p->pi_lock, flags);
}
stop_one_cpu(task_cpu(p), migration_cpu_stop, &arg);这句函数的作用是什么。
stop_one_cpu是停止某个cpu的运行,非SMP和SMP下实现不一样。非SMP下,stop_one_cpu的实现其实就是关抢占、执行函数、开抢占。
SMP架构下,stop_one_cpu实现:
该函数是在执行完函数fn之后再返回,但是不能保证执行fn的时候cpu还一直在线。
int stop_one_cpu(unsigned int cpu, cpu_stop_fn_t fn, void *arg)
{struct cpu_stop_done done;struct cpu_stop_work work = { .fn = fn, .arg = arg, .done = &done };cpu_stop_init_done(&done, 1);if (!cpu_stop_queue_work(cpu, &work))return -ENOENT;/** In case @cpu == smp_proccessor_id() we can avoid a sleep+wakeup* cycle by doing a preemption:*/cond_resched();wait_for_completion(&done.completion);return done.ret;
}
migration_cpu_stop函数
主要是两个拿锁的地方,未能理解为何需要那样的判断,rq->lock以及p->pi_lock
/** migration_cpu_stop - this will be executed by a highprio stopper thread* and performs thread migration by bumping thread off CPU then* 'pushing' onto another runqueue.*/
static int migration_cpu_stop(void *data)
{struct migration_arg *arg = data;struct task_struct *p = arg->task;struct rq *rq = this_rq();struct rq_flags rf;/** The original target CPU might have gone down and we might* be on another CPU but it doesn't matter.*/local_irq_disable();/** We need to explicitly wake pending tasks before running* __migrate_task() such that we will not miss enforcing cpus_ptr* during wakeups, see set_cpus_allowed_ptr()'s TASK_WAKING test.*/flush_smp_call_function_from_idle();raw_spin_lock(&p->pi_lock);rq_lock(rq, &rf);/* 这个地方为何一定要task_rq == rq才能去迁移呢?rq是当前正在执行任务的cpu的rq,其rq->lock拿着,与task_rq(p) != rq有何冲突?没能理解。会不会是迁移操作时需要获取p所在rq的lock,以及目标rq的lock,那样的话假设task_rq(p)不等于rq,拿两个rq->lock不就好了?* If task_rq(p) != rq, it cannot be migrated here, because we're* holding rq->lock, if p->on_rq == 0 it cannot get enqueued because* we're holding p->pi_lock.*/if (task_rq(p) == rq) { //必须是p所在的rq与当前cpu的rq是同一个才能迁移if (task_on_rq_queued(p)) //必须p是on rq才能迁移rq = __migrate_task(rq, &rf, p, arg->dest_cpu);elsep->wake_cpu = arg->dest_cpu;}rq_unlock(rq, &rf);raw_spin_unlock(&p->pi_lock);local_irq_enable();return 0;
}
八、fork进程
/** wake_up_new_task - wake up a newly created task for the first time.** This function will do some initial scheduler statistics housekeeping* that must be done for every newly created context, then puts the task* on the runqueue and wakes it.*/
void wake_up_new_task(struct task_struct *p)
{struct rq_flags rf;struct rq *rq;raw_spin_lock_irqsave(&p->pi_lock, rf.flags);p->state = TASK_RUNNING;
#ifdef CONFIG_SMP/** Fork balancing, do it here and not earlier because:* - cpus_ptr can change in the fork path* - any previously selected CPU might disappear through hotplug** Use __set_task_cpu() to avoid calling sched_class::migrate_task_rq,* as we're not fully set-up yet.*/p->recent_used_cpu = task_cpu(p);rseq_migrate(p);__set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0));
#endifrq = __task_rq_lock(p, &rf);update_rq_clock(rq);post_init_entity_util_avg(p);activate_task(rq, p, ENQUEUE_NOCLOCK);trace_sched_wakeup_new(p);check_preempt_curr(rq, p, WF_FORK);
#ifdef CONFIG_SMPif (p->sched_class->task_woken) {/** Nothing relies on rq->lock after this, so its fine to* drop it.*/rq_unpin_lock(rq, &rf);p->sched_class->task_woken(rq, p);rq_repin_lock(rq, &rf);}
#endiftask_rq_unlock(rq, p, &rf);
}