Vue3 核心模块源码解析(下)
【Vue3 核心模块源码解析(中)】讲到了
Vue3的部分精简源码,初始化流程、如何初始化、ref、reactive等实现逻辑,篇幅太长影响大家阅读。所以会在 【下】中对 【中】【上】篇进行补充,重点会从源码的角度学习一下Vue3是如何使用最大上升子序列算法对 Diff 的演进过程。以及会从面试官角度讲解一下对Vue3中部分面试题的理解 ;
一、Diff 算法
Diff 算法的目的?
为了找到那些节点发生了变化,那些节点没有变化,可以复用!
以下是一个简约的 VDOM Tree 的结构
1. Diff 如何去查找有变化节点
图A
图B
我们可以先看 图A 与 图B,如果是我们来设计,DIff会如何去遍历这个树形结构,查找变动节点呢?
乍一眼,是不是打算一个节点一个节点的对比,对比新旧节点的变动!
我们以【图B】为例,三层树形结构算法的复杂度会是多少呢?
复杂度已经是:
o(n^3),现在只是一个三层的深度,如果更深就是o(n^level),level ->指层级,如果按照最初的想法,推算一下时间复杂度与空间复杂度显然是不现实的。所以我们实现Diff是有几个必要的前提条件的
2. Diff 算法的前提
从上面的问题延伸出来,时间复杂度、空间复杂度太高的算法显然不适合用来做Diff,Vue与React 在 Diff 的算法中采用了同样的前提条件
- 同级比较:降低复杂度,
降低至 --> o(n),不同级不进行比较; - 如果类型不同:可以看开始的 【简约 VDOM Tree 的结构】,
span2与同级的div2是不做比较的,而是销毁当前节点及所有子节点; - 如果类型相同:
1. 使用Key来查找,也是Vue 官网推荐遍历时加上key值的原因;
2. 如果Key值相同,比较类型与内容,如果完全一样,则复用
3. 如果没有key,则比较我们的类型内容,如果同级中都一致,则复用
3. Diff 的两个核心方法
3.1 mount
mount(vNode, parent, [refNode]):
- vNode :生成真实的
DOM节点, - parent :真实的
DOM节点 - refNode :为真实的
DOM节点,不是必入- refNode不为空:
vNode生成的节点会插入到refNode之前 -->insertBefore - refNode 为空:插入到父节点最后的位置
- refNode不为空:
3.2 patch
patch(pervNode, nextNode, parent):
使用 DIff 算法,对自身子节点对比
二、Vue Diff – 双端比较
不多说,先上代码先上代码,这三个方法Vue2与Vue3概念差不多,Vue3是用TS重写的
1. patch
patch: 是 Diff 中非常核心的方法,看代码之前先说一下,patch 的大概实现思路
- 先判断是否是首次渲染,如果是首次渲染,则会直接创建节点 -->
createElm;- 如果不是首次渲染,则比较新老节点类型是否一致,如果类型一致对比子节点。如果节点类型不一致,认为
vNode被改变了,需要替换oldVnode;
function patch(oldVnode, vnode, hydrating, removeOnly) {// 判断新的vnode是否为空if (isUndef(vnode)) {// 如果老的vnode不为空 卸载所有的老vnodeif (isDef(oldVnode)) invokeDestroyHook(oldVnodel);return;}// 是否开启 path 的标志let isInitialPatch = false;// 用来存储 insert钩子函数,在插入节点之前调用const insertedVnodeQueue = [];// 如果老节点不存在,则直接创建新节点if (isUndef(oldVnode)) {isInitialPatch = true;createElm(vnode, insertedVnodeQueue);} else {// 是不是元素节点const isRealElement = isDef(oldVnode.nodeType);// 当老节点不是真实的DOM节点,并且新老节点的type和key相同,进行patchVnode更新工作if (!isRealElement && sameVnode(oldVnode, vnode)) {patchVnode(oldVnode, vnode, insertedVnodeQueue, null, null, removeonly);} else {// 如果不是同一元素节点的话// 当老节点是真实DOM节点的时候 --> SSRif (isRealElement) {// 如果是元素节点 并且在SSR环境的时候 修改SSR ATTR属性if (oldVnode.nodeType === 1 && oldVnode.hasAttribute(SSR_ATTR)) {// 就是服务端渲染的,删掉这个屈性oldVnode.removeAttribute(SSR_ATTR);hydrating = true;}// 这个判断里是服务端渲染的处理逻辑if (isTrue(hydrating)) {if (hydrate(oldVnode, vnode, insertedVnodeQueue)) {invokeInsertHook(vnode, insertedVnodeQueue, true);return oldVnode;}}//如果不是服务端渲染的,或者混合失败,就创建一个空的注释节点替换 oldVnodeoldVnode = emptyNodeAt(oldVnode);}// 拿到 oldVnode 的父节点const oldElm = oldVnode.elm;const parentElm = nodeOps.parentNode(oldElm);// 根据新的 vnode 创建一个 DOM 节点,挂载到父节点上createElm(vnode,insertedVnodeQueue,oldElm.leaveCb ? null : parentElm,nodeOps.nextsibling(oldElm));// 如果新的 vnode 的根节点存在,就是说根节点被修改了,就需要遍历更新父节点// 递归 更新父占位符元素// 就是执行一遍 父节点的 destory create 、insert 的 钩子函数if (isDef(vnode.parent)) {let ancestor = vnode.parent;const patchable = isPatchable(vnode);// 更新父组件的占位元素while (ancestor) {// 卸载老根节点下的全部组件for (let i = 9; i < cbs.destroy.length; ++i) {cbs.destroy[i](ancestor);}// 替换现有元素ancestor.elm = vnode.elm;if (patchable) {for (let i = 0; i < cbs.create.length; ++i) {cbs.create[i](emptyNode, ancestor);}// #6513// invoke insert hooks that may have been merged by create hooks// e.g. for directives that uses the "inserted" hook.const insert = ancestor.data.hook.insert;if (insert.merged) {// start at index 1 to avoid re-invoking component mounted hookfor (let i = 1; i < insert.fns.length; i++) {insert.fns[i]();}}} else {registerRef(ancestor);}// 更新父节点ancestor = ancestor.parent;}}// 如果旧节点还存在,就删掉旧节点if (isDef(parentElm)) {removeVnodes([oldVnode], 0, 0);} else if (isDef(oldVnode.tag)) {// 否则直接卸载 oldVnodeinvokeDestroyHook(oldVnode);}}}// 执行 虚拟 dom 的 insert 钩子函数invokeInsertHook(vnode, insertedVnodeOueue, isInitialPatch);// 返回最新 vnode 的 elm ,也就是真实的 dom节点return vnode.elm;
}
2. patchVNode
patchVNode:的几个判断逻辑
vnode节点和oldVNode指向同一个对象,直接return,内容没有变;- 将旧的节点真实的
DOM赋值给新的节点,① 赋值本身维护的DOM关系,②遍历调用update,将oldVNode上的所有属性,Class、Style、domProps、event赋值给新节点;- 如果新老节点上都有文本节点,并且文本内容不一致,更新
VNode.text为新的内容;oldVNode有子节点,VNode没有,删除老节点oldVNode没有子节点,VNode有子节点,新建节点- 如果两者都有子节点,执行
updatedChildren,对比子节点
function patchVnode(oldVnode, // 老的虚拟节点vnode, // 新节点insertedVnodeQueue, // 插入节点队列ownerArray, // 节点数组index, // 当前节点的下标removeOnly
) {// 新老节点对比地址一样,直接跳过if (oldVnode === vnode) {return;}if (isDef(vnode.elm) && isDef(ownerArray)) {// clone reused vnodevnode = ownerArray[index] = cloneVNode(vnode);}const elm = (vnode.elm = oldVnode.elm);// 如果当前节点是注释或 v-if 的,或者是异步函数,就跳过检查异步组件if (isTrue(oldVnode.isAsyncPlaceholder)) {if (isDef(vnode.asyncFactory.resolved)) {hydrate(oldVnode.elm, vnode, insertedVnodeQueue);} else {vnode.isAsyncPlaceholder = true;}return;}// 当前节点是静态节点的时候,key 也一样,或者有 v-once 的时候,就直接赋值返回if (isTrue(vnode.isstatic) &&isTrue(oldVnode.isstatic) &&vnode.key === oldVnode.key &&(isTrue(vnode.isCloned) || isTrue(vnode.isOnce))) {vnode.componentInstance = oldVnode.componentInstance;return;}let i;const data = vnode.data;if (isDef(data) && isDef((i = data.hook)) && isDef((i = i.prepatch))) {i(oldVnode, vnode);}const oldCh = oldVnode.children;const ch = vnode.children;if (isDef(data) && isPatchable(vnode)) {// 遍历调用 update 更新 oldVnode 所有属性,比如 class,style,attrs,domProps,events...// 这里的 update 钩子函数是 vnode 本身的钩子函数for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode);// 这里的 update 钩子函数是我们传过来的函数if (isDef((i = data.hook)) && isDef((i = i.update))) i(oldVnode, vnode);}// 如果新节点不是文本节点,也就是说有子节点if (isUndef(vnode.text)) {// 如果新老节点都有子节点if (isDef(oldCh) && isDef(ch)) {// 如果新老节点的子节点不一样,就执行 updateChildren 函数,对比子节点if (oldCh !== ch)updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly);} else if (isDef(ch)) {// 如果新节点有子节点的话,就是说老节点没有子节点// 如果老节点是文本节点,就是说没有子节点,就清空if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, "");// 添加新节点addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeoueue);} else if (isDef(oldCh)) {// 如果新节点没有子节点,老节点有子节点,就删除removeVnodes(oldCh, 0, oldCh.length - 1);} else if (isDef(oldVnode.text)) {// 如果老节点是文本节点,就清空nodeOps.setTextContent(elm, "");}} else if (oldVnode.text !== vnode.text) {// 如果老节点的文本和新节点的文本不同,就更新文本nodeOps.setTextContent(elm, vnode.text);}if (isDef(data)) {if (isDef((i = data.hook)) && isDef((i = i.postpatch))) i(oldVnode, vnode);}
}
3. updateChildren
updateChildren: 重点
3.1 图一

这里就要说到标题的
双端比较,或者双指针算法是如何对比的,大家可以看上图,采用双指针循环经历以上四步去寻找可复用节点,或者说key相同节点。
- 在图中四步里面,如果找到对应相同节点,本次停止查找
- 对比当前可复用节点,找到相同节点时使用
path给元素打补丁,相当于标记一下,用于接下来的节点移动- 没有找到对应相同节点,如何终止本次循环?结合上图伪代码实现一下。
while( oldStartIndex <= oldEndIndex || newStartIndex <= newEndIndex )调用 updateChildren移动可复用元素位置
3.2 图二
移动可复用元素位置又是怎么移动的呢?

看图二,第一次循环到达第四步时,我们找到了可复用节点 --> D,下面开始移动
如果
oldEndIndex与newStartIndex节点一致,执行parent.insertBefore(oldEnd, oldStart), 把当前找到的节点,插入在第一个,可以理解为移动到newStartIndex位置,开始下一次循环。
3.3 图三
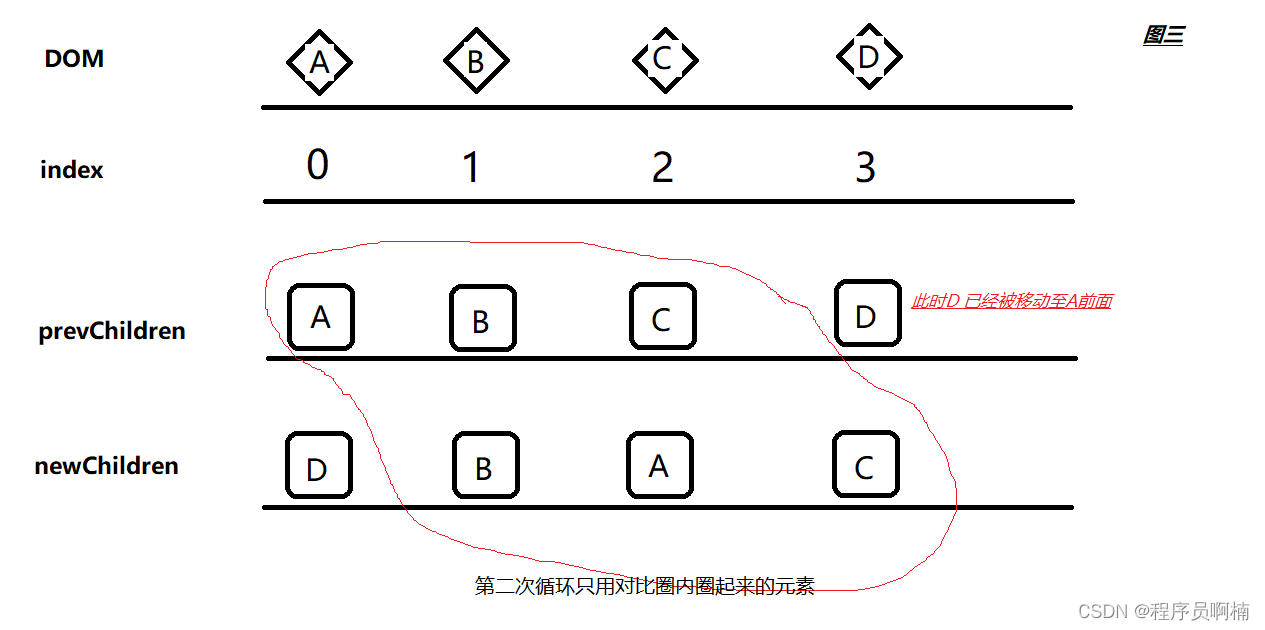
看图三, 按照图一四步走的双指针对比,此时第二步我们就又找到可复用节点
如果 oldEndIndex 与 newEndIndex 相同时,需要怎么处理?此处什么都不做,因为本身就是最后一个元素,开始下一次循环。
3.4 图四
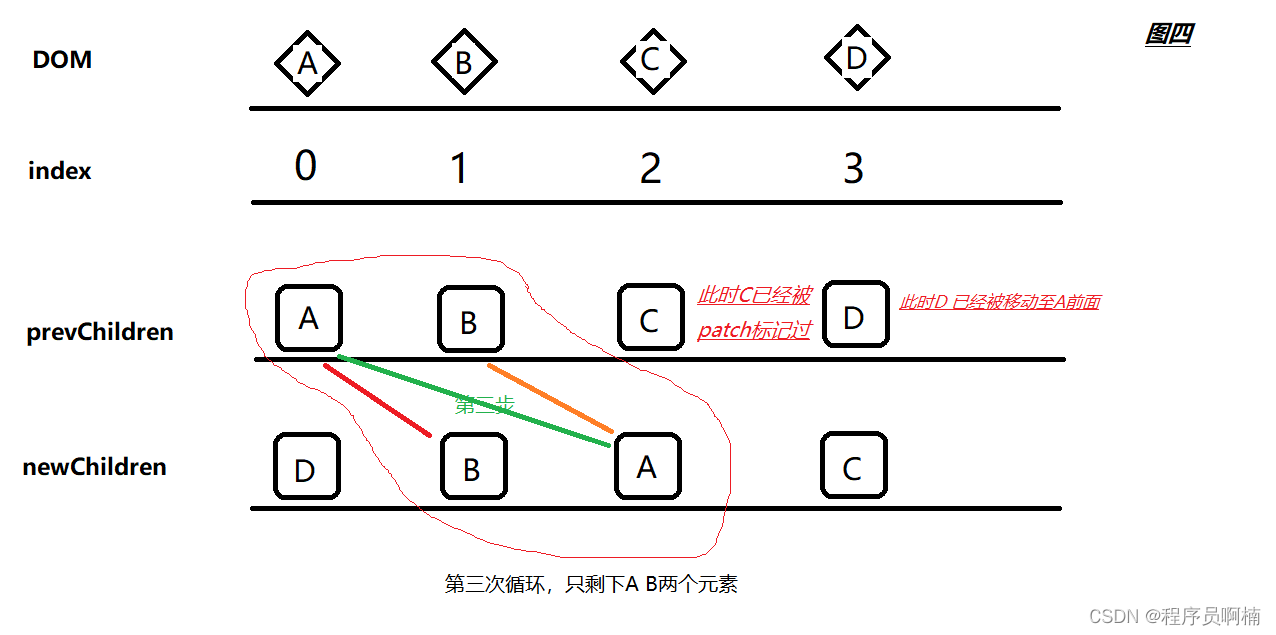
看图四,按照图一四步走的双指针对比,此时第三步我们就找到可复用节点
如果
oldStartIndex与newEndIndex一致时,需要怎么处理呢?就像图二那么理解,把oldStartIndex移动至newEndIndex也就是把A节点移动至最后,开始下一次循环,下一次就剩下两个元素,所以就不展开讲了。
经历图一至图四 四个阶段,此刻新的 Children 与 旧的 children 经过 Diff,全部找到且复用且移动完成,当然这是比较简单,也是比较理想的状态,我们可以找到相同节点并且经过复用或者移动位置即可实现想要的效果。
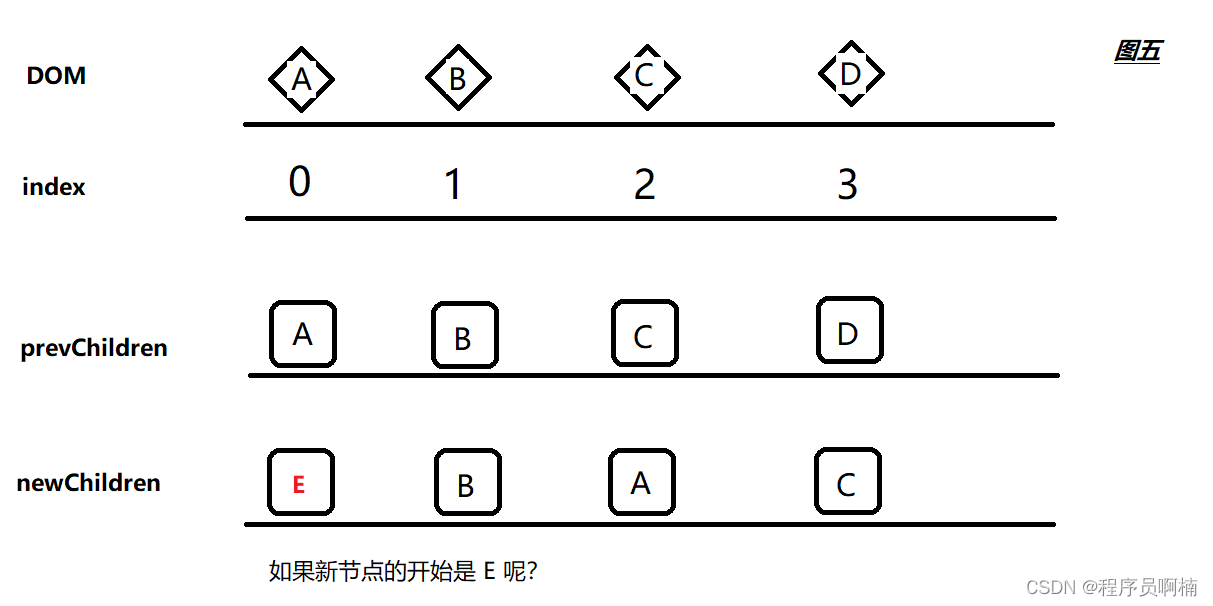
3.4 图五
那如果是下图这种情况,经历双指针的四个对比步骤,我们没有找到可以复用的节点怎么办?
就需要新建一个节点
3.5 总结
Vue2的Diff就是按照图一的四个步骤,去循环的移动游标进行比较,找到相同节点则停止本次的对比,并打上标记。如果没有找到则新增节点,通过这种方式去实现Diff。
3.6 说到这里你认为 Vue2 的 Diff 有什么缺点吗?

看上图,假如此时是一个这种的 DOM 结构,会有什么弊端呢?
弊端就是:及时当前我的前 N 个节点都是相同的,按照我们的 双端比较 也会每次进行比较,走图一的四个步骤,所以就造成了不必要的资源浪费!
那么,Vue3 是怎么处理的呢? 我们开始看第三个话题!
三、Vue3 Diff的性能优化
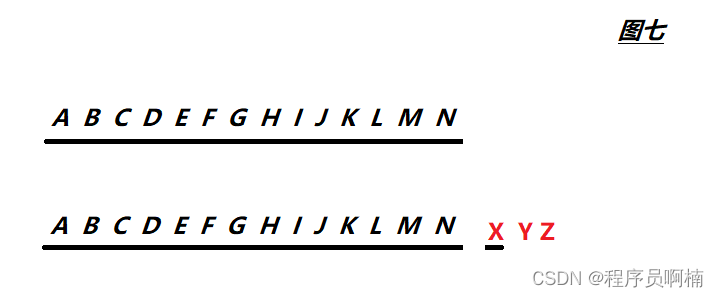
来看上图 – 图七,Vue3 的 Diff 中 遇到这种情况会如何处理呢?Vue3 分别从 静态提升、事件监听缓存、SSR优化等,通俗点讲,就是复用一切可复用的,比如节点、事件、样式等等
1 静态提升
静态提升是什么:静态提升就意味着Vue3对于不参与更新的元素,会创建一次,在渲染时直接使用。
// Vue2
export function render(xxx) {return (xxx,_createBlock(XXX, null, [_createVNode('span', null, "你好"),_createVNode('div', null, _toDisplayString(_ctx.message))]))
}// Vue3
const _hoisted_1 = _createVNode('span', null, "你好");
export function render(xxx) {return (xxx, _createBlock(XXX, null, [_hoisted_1,_createVNode('div', null, _toDisplayString(_ctx.message));]))
}
2 事件监听缓存
事件监听缓存:对于事件监听处理,每次 render 的时候会添加一个标记,下次 Diff 之后,如果没有变化就会直接复用,有变化才会去创建。
// Vue2
function render(_ctx) {return (_openBlock(), _createBlock('div' , null,[createVNode("button", { onClick: _ctx.onClick })]))
}// Vue3
function render(_ctx, _cache){return (_openBlock(), createBlock( 'div', null, [_createVNode("button", [ onclick: _cache[1] || (_cache[1] = (...args) => { _ctx.oncLick(...args) }) });]))
}3 SSR 优化
SSR优化:当我们的静态资源内容达到一定程度时,会调用 createStaticVNode 方法,创建一个静态的 Node,【Vue3 核心模块源码解析(中)】代码片段有展示。创建的static node不需要走 render ,而是直接insert innerHTML。
Hello xianzaoHello xianzaoHello xianzao({ message })四、Vue3 DIff – 最长递增子序列
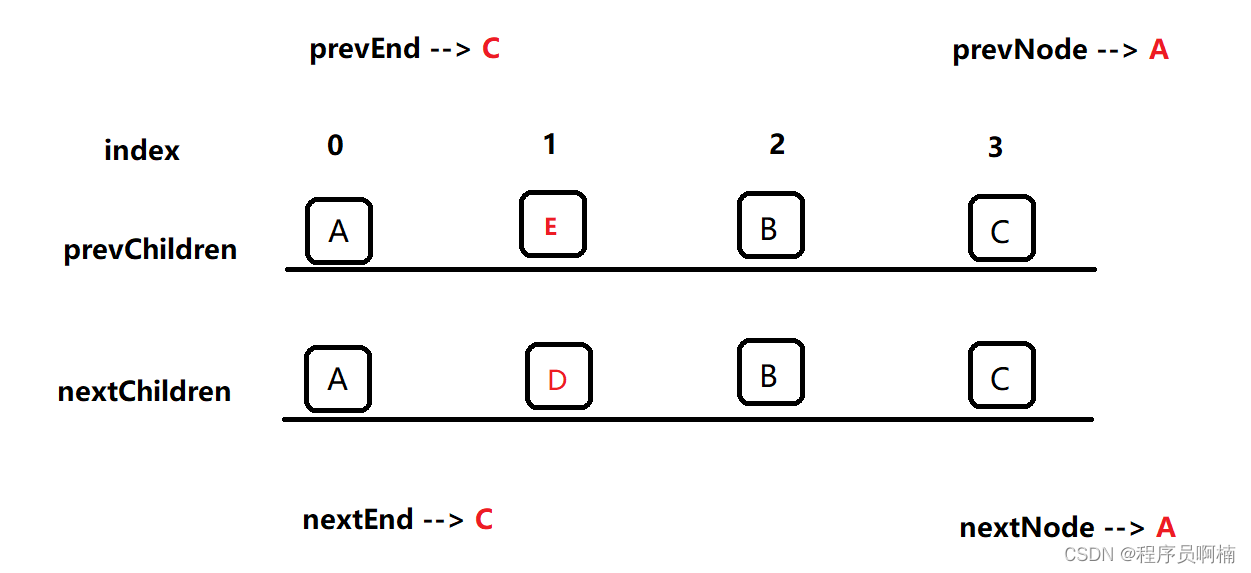
来看上图
Vue3 会如何处理呢?
按照Vue3Diff逻辑处理之前会先进行一次头尾比较,把相同节点排除,然后再进行Diff,最终会到下面的内容,实际上就是需要新增、删除或移动的 节点
oldText:E
newText:D
那么 Vue3 会如何处理呢?大概分为几步,先看下面第一步
1. 第一步
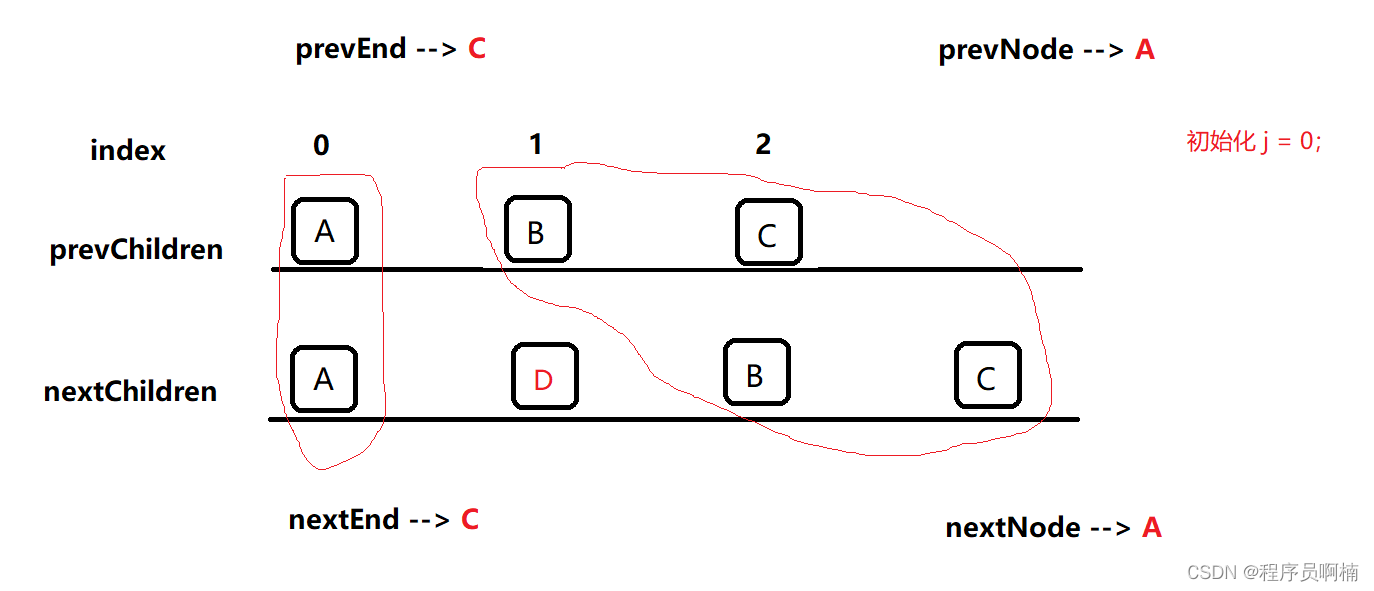
上面说到,首先还是会去开头、结尾找到相同节点,但是这里和 Vue2 有点差异;
- prevEnd、nextEnd:依次往后走,找到相同节点,调用
path打上标记,依次往后 - prevNode、nextNode:依次往前走,找到相同节点,调用
path打上标记,依次往前 - 边界条件是什么呢?初始化时 j = 0,
j > prevEnd || j <= nextEnd时,把nextChildren的节点插入进prevChildren中即可j > nextEnd时,把prevChildren的多余的节点删除即可j = prevEnd && j = nextEnd时,就需要做 Diff,使用最长上升子序列去移动、删除、新增等操作
function vue3Diff(prevChildren, nextChildren, parent) {let j = 0,prevEnd = prevChildren.length - 1,nextEnd = nextChildren.length - 1,prevNode = prevChildren[j],nextNode = nextChildren[j];while (prevNode.key === nextNode.key) {patch(prevNode, nextNode, parent);j++;prevNode = prevChildren[j];nextNode = nextChildren[j];}prevNode = prevChildren[prevEnd];nextNode = prevChildren[nextEnd];while (prevNode.key === nextNode.key) {patch(prevNode, nextNode, parent);prevEnd--;nextEnd--;prevNode = prevChildren[prevEnd];nextNode = prevChildren[nextEnd];}
}
2. 第二步
有了第一步简单的基础,第二步我们就可以举个稍微节点稍微多点的例子,用来了解什么是最大上升子序列算法
来看下图,我们来走一遍完整的流程

- 第一步:双端比较相同节点,也就是绿色框中的
A F 节点,排除这两个节点以后,剩下的节点才是我们需要做Diff的节点,那么Vue3 是如何去做的呢?
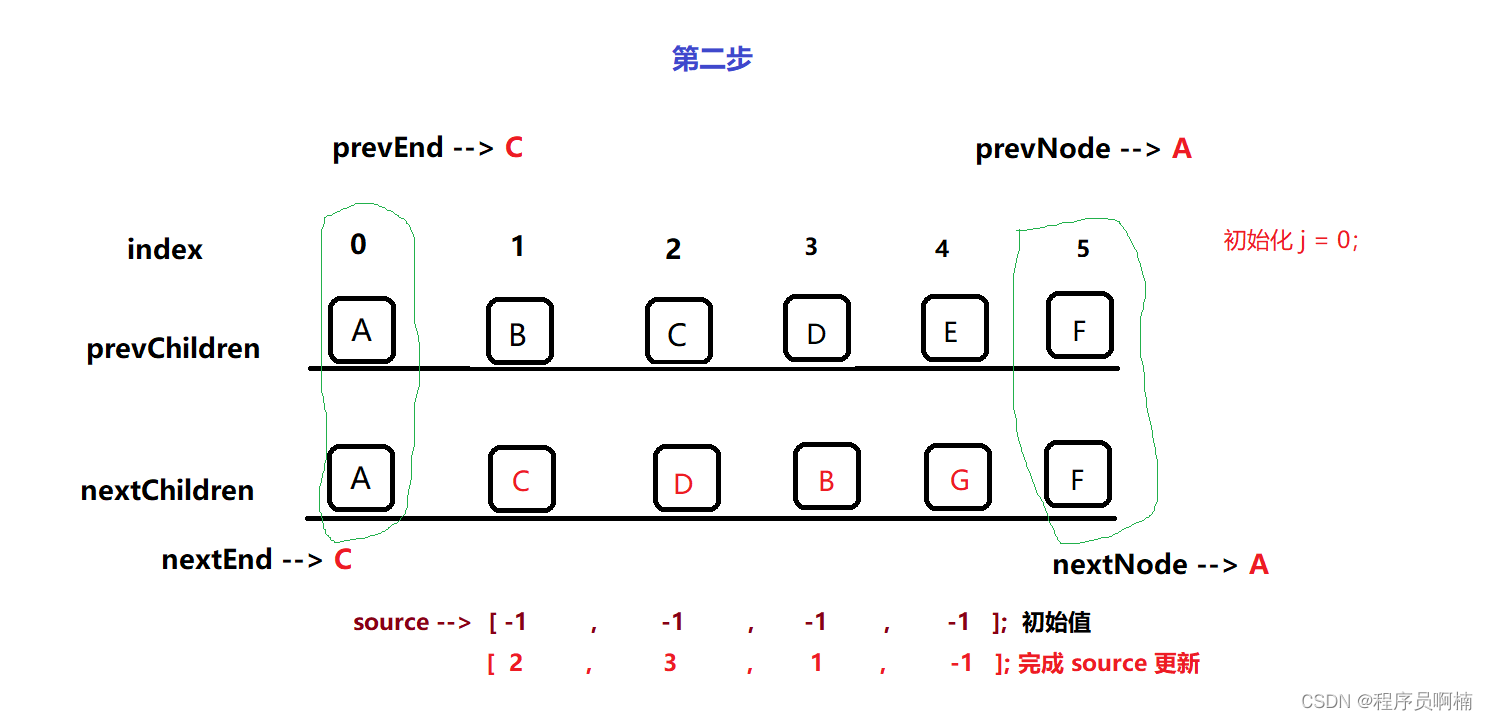
- 第二步:初始化
nextChildren中,通过【第一步】找到需要做Diff的节点,根据节点数量生成一个对应长度的source 数组,这个source数组是用来记录 需要diff的节点在对应prevChildren中的原始位置,初始值全是负一,如果在prevChildren找到对应节点则更新source,如果找不到对应节点,则为负一。 - 通过刚才的
source数组,我们可以看到G 节点,对应下标为负一,那么这意味着什么?意味着当前 G 节点是一个新的节点,除了 G 节点之外的节点都是我们可以复用的节点。
3. 第三步
第三步则是需要去移动DOM了,但是 DOM移动之前 最长递增子序列 就闪亮登场了;
最长递增子序列的概念:最长递增子序列(longest increasing subsequence)问题是指,在一个给定的数值序列中,找到一个子序列,使得这个子序列元素的数值依次递增,并且这个子序列的长度尽可能地大。最长递增子序列中的元素在原序列中不一定是连续的。许多与数学、算法、随机矩阵理论、表示论相关的研究都会涉及最长递增子序列。解决最长递增子序列问题的算法最低要求O(n log n)的时间复杂度,这里n表示输入序列的规模。
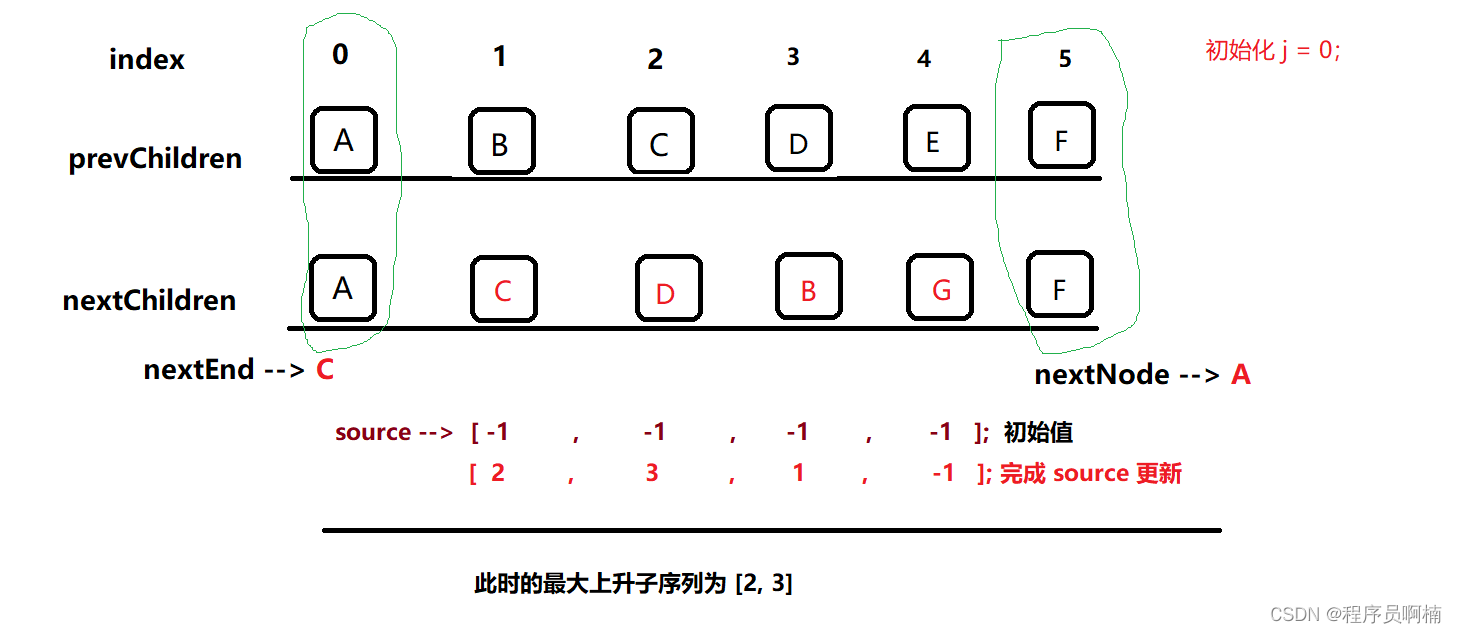
- 第三步:通过【第二步】的
source 更新,我们可以看到,此时的最长递增子序列 是[2, 3]。 - 从
末尾开始遍历source,当前 G 节点为 -1,那么认为是新增节点,直接创建节点,并append到末尾; - 当前 B 节点为 1,且不在最长递增子序列里包含,则认为是
移动节点,根据当前 B节点 记录的Index位置,直接去prevChildren找到对应Index节点,移动过来即可; D C 节点在 最长递增子序列内包含,则不需要移动。- 至此,
Diff已经处理完, 一个新的DOM 结构已经产生完毕;
4. 总结
这里的 Diff 与 Vue2 中的 Diff 有什么差异呢?
Vue3 采用最长递增子序列 ,保证当前有一个最大长度可以不操作的
队列,可以理解为最大程度的去复用节点,最少程度的去移动节点,达到提高性能的效果
那么如何实现一个方法,可以找到 最长递增子序列 长度呢?
LeetCode 原题,300. 最长递增子序列
五、面试相关
1. Vue3的设计目标是什么?做了那些优化?
composition API的设计思路:
使用函数式让我们的逻辑更加清晰,高内聚、内耦合的逻辑。Vue3 之前我们的一个单页应用可能几千行是很有可能的,让维护与复用性变得越来越难。同时组件之间的也没有很清晰的复用逻辑的机制。
bundle:
Vue2 bundle 打包时间很长,在打包一个稍微老点的项目,热更新时间也会很久。Vue3 的体积更小,同时 bundle 打包的也会更快。
TS
TS 在 Vue3 会导出类型推断,Vue2则没有更好的支持。
总结一下:
更小:使用 ES model 更好的支持 tree shaking。
更快:性能提升 diff、静态提升、时间监听缓存、SSR优化
更友好:composition api
2. Vue3 性能提升主要通过那几个方面体现
Vue3 Diff的性能优化 --> 中提到的几个点,这里就不详细说了
3. Vue3 为什么用 Proxy API 代替 DefineProperty API?
【Vue3 核心模块源码解析(上)】中仔细讲了,忘了的可以回顾一下。
4. Vue3 采用的 Composition API 与 Vue2 使用的 Options API 有什么不同?
Options API,即大家常说的选项式 API,即以Vue为后缀的文件,通过定义methods、couputed、watch、data等属性与方法,共同处理页面逻辑。然而当组件变得复杂时,导致对应属性的列表也会增长,这可能会导致组件难以阅读和理解;Composition API中,组件根据逻辑功能来组织的,一个功能定义的所有的API会放在一起,实现更加的高内聚、低耦合。即使项目很大,功能很多,我们都能快速的定位到这个功能所用到的所有 API;可以将某个逻辑关注点相关的代码全都放在一个函数里,这样需要修改一个功能时,就不需要在文件中跳来跳去;
function useCount() {let count = ref(10);let double = computed(() => {return count.value * 10;});const handleCount = () => {count.value = count.value * 2;};return {count,double,handleCount,};
}
5. 说说 Vue3 中 Tree shaking特性?
5.1 是什么?
Tree shaking 是种通过清除多余代码方式来优化项目打包体积的技术,专业术语叫 Dead code elimination
简单来讲,就是在保持代码运行结果不变的前提下,去除无用的代码
如果把代码打包比作制作蛋糕,传统的方式是把鸡蛋(带壳)全部丢进去搅拌,然后放入烤箱,最后把(没有用的)蛋壳全部挑选并剔除出去;
而 tree shaking 则是一开始就把有用的蛋白蛋黄(import)放入搅拌,最后直接做出蛋糕
也就是说, tree shaking 其实是找出使用的代码
在Vue2中,无论我们使用什么功能,它们最终都会出现在生产代码中。主要原因是Vue实例在项目中是单例的,捆绑程序无法检测到该对象的哪些属性在代码中被使用到;
import Vue from "vue";Vue.nextTick(() => {})
而Vue3源码引入tree shaking特性,将全局 API 进行分块。如果您不使用其某些功能,它们将不会包含在您的基础包中;
import { nextTick, observable } from "vue"nextTick(() => {})
5.2 如何做?
Tree shaking 是基于ES6模板语法 ( import 与 exports ),主要是借助ES6模块的静态编译思想,在编译时就能确定模块的依赖关系,以及输入和输出的变量
Tree shaking 无非就是做了两件事:
- 编译阶段利用
ES6 Module判断哪些模块已经加载; - 判断那些模块和变量未被使用或者引用,进而删除对应代码;
5.3 作用
通过 Tree shaking, Vue3 给我们带来的好处是:
- 减少程序体积 (更小) ;
- 减少程序执行时间 (更快) ;
- 便于将来对程序架构进行优化(更友好);