基于XGBoost的用户流失预测
基于XGBoost的用户流失预测
小P:小H,我怎么能知道哪些用户有可能会流失呢?我这里有一份数据,你帮忙看看哪些字段更有助于寻找流失用户
小H:我只需要告诉你哪些特征更重要是吗?
小P:对对~
小H:这个可以用机器学习的算法进行训练,最常见的就是Kaggle大杀器XGBoost
在日常业务挖掘中,XGBoost具有准确性高、数据友好等优点,可以快速地对历史数据进行训练,数据分析师也往往是基于业务角度去进行数据挖掘,因此特征都是具有业务意义的统计数据,数据质量较高。当然这种逻辑思维也会有一定的缺陷,那就是考虑的特征不全面。
本文主要介绍在日常数据挖掘过程中的一些流程化的东西,例如从数据探索->特征工程->数据建模->结果展示。
相关函数
在开始之前,介绍下自定义模块
keyIndicatorMapping。这个是数据挖掘中常用的函数集合,例如变量的处理、指标评估、评估图表等。大致如下图~
可以通过
%load命令加载查看这个模块内的所有函数。这里函数有点多,因为这里的部分函数会在后面的数据挖掘案例中用到。每个函数的用途和定义都有明确注释,相信大伙肯定能看懂,限于篇幅这里就不再额外讲解了。%load '/Users/heinrich/Desktop/Heinrich-blog/数据分析使用手册/keyIndicatorMapping.py'
上述自定义模块
keyIndicatorMapping如果有需要的同学可关注公众号HsuHeinrich,回复【数据挖掘-自定义函数】自动获取~
数据探索
市面上封装好的EDA库很多,这里介绍个人比较喜欢的一款
sweetviz。只需简单的一句analyze即可得到所有变量的信息,以及和y的关系图。!pip install git+https://github.com/fbdesignpro/sweetviz.git # 安装(常规安装有点问题)# 通过sweetviz生成EDA报告 建议低特征使用 import sweetviz as sv # 自动eda sv.analyze(raw_data, y_col).show_notebook()
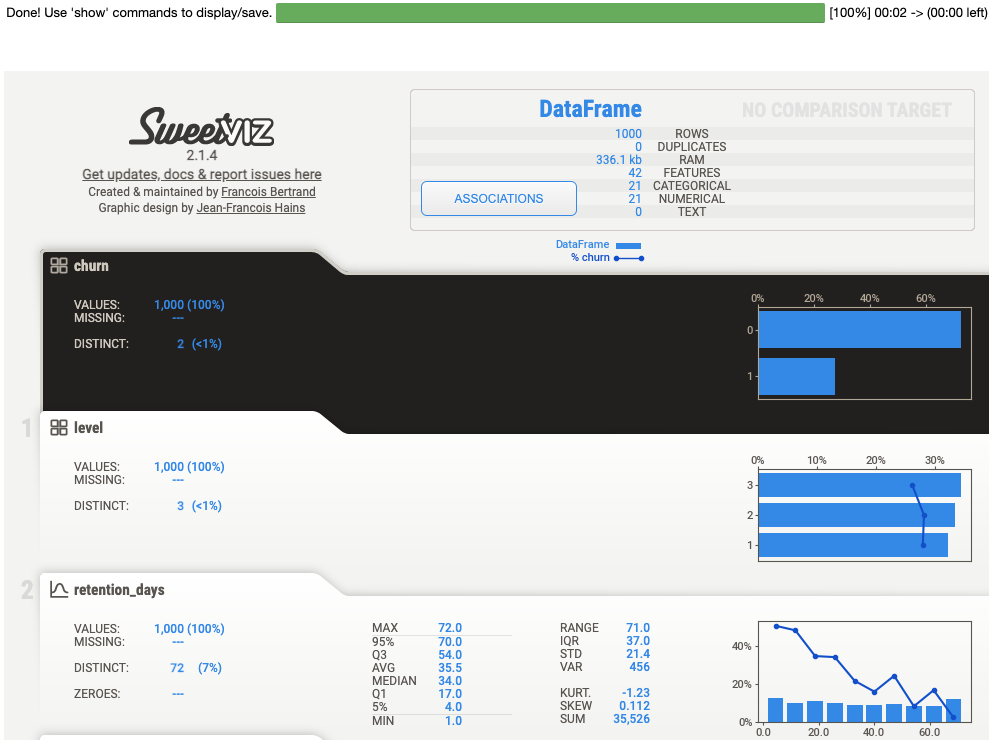
不过我更喜欢自己查看数据,sweetviz辅助探索。
导入相关库
import pandas as pd
import numpy as np
import math
from sklearn.model_selection import train_test_split # 数据分区库
import xgboost as xgb
from sklearn.metrics import accuracy_score, auc, confusion_matrix, f1_score, \precision_score, recall_score, roc_curve # 导入指标库
from imblearn.over_sampling import SMOTE # 过抽样处理库SMOTE
import matplotlib.pyplot as plt
import prettytable # 导入表格库
from pandas_profiling import ProfileReport # 自动eda
import sweetviz as sv # 自动eda
import matplotlib as mpl
import matplotlib.pyplot as plt
from matplotlib import ticker
import seaborn as sns
import os
import shutil
import toad
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
import itertools
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm# 绘图初始化
%matplotlib inline
pd.set_option('display.max_columns', None) # 显示所有列
sns.set(style="ticks")
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 导入自定义模块
import sys
sys.path.append("/Users/heinrich/Desktop/Heinrich-blog/数据分析使用手册")
from keyIndicatorMapping import *
数据准备
以下数据如果有需要的同学可关注公众号HsuHeinrich,回复【数据挖掘-XGB】自动获取~
# 读取数据
raw_data = pd.read_csv('classification.csv', delimiter=',', dtype=str) # 读取数据文件
raw_data.head()

# 变量分类# 通过var_class_dic函数将原始数据的特征分为不同的类【指标、日期、数值、字符串】
var_class_dic = var_class(raw_data, 'churn')
# 通过get_key函数获取相对应的列名
y_col = get_key(var_class_dic, 'y')[0]
date_col = get_key(var_class_dic, 'date')
number_col = get_key(var_class_dic, 'number')
object_col = get_key(var_class_dic, 'object')
# 更改数据类型
raw_data = raw_data.apply(pd.to_numeric, errors='ignore') # 把能转换成数字的都转换成数字,不能转化的由error=True参数控制忽略掉。
raw_data[date_col] = raw_data[date_col].apply(pd.to_datetime) # 转时间列
# 查看数据基本信息
toad.detector.detect(raw_data)
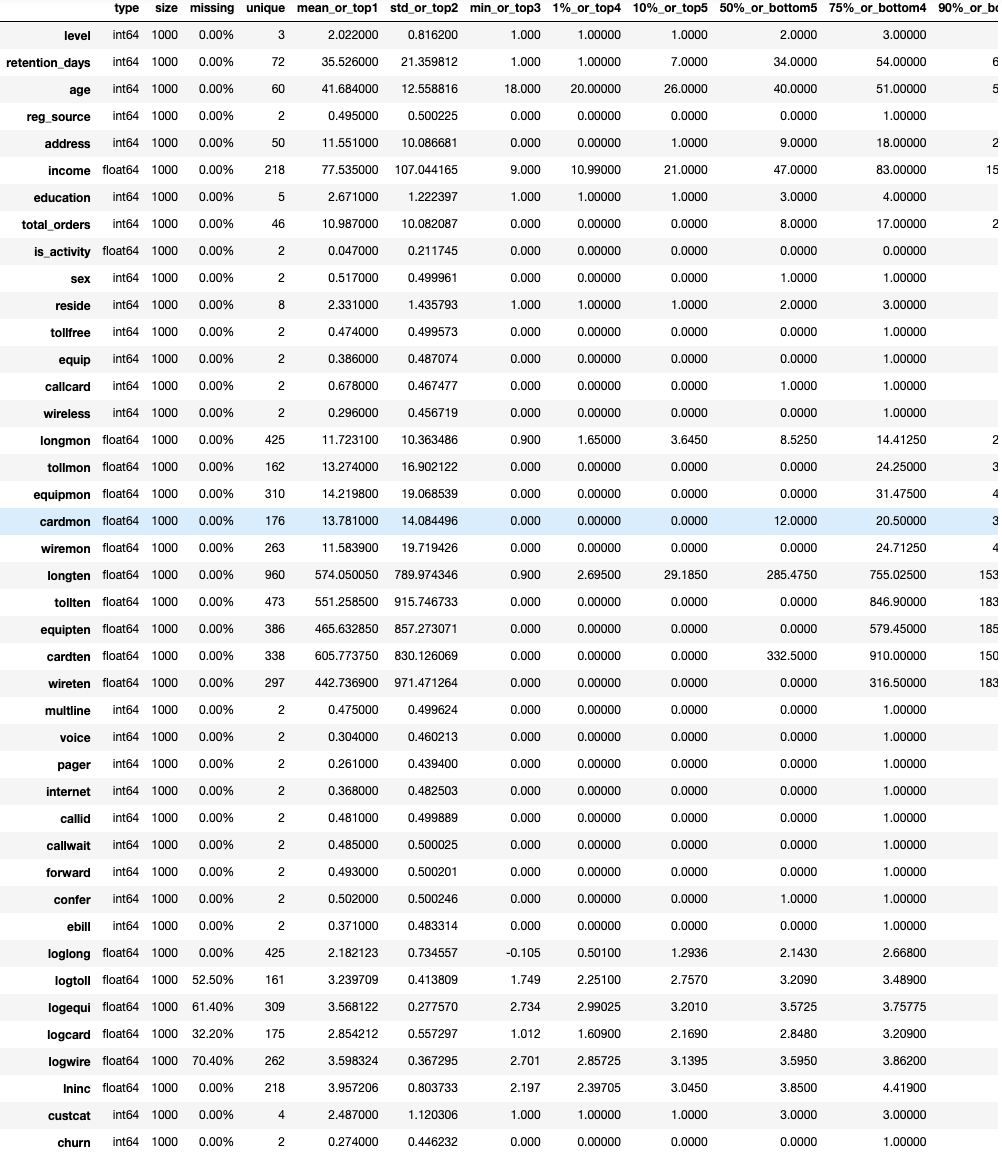
# 数据审查
na_count = raw_data.isnull().any().sum() # 缺失值样本量
n_samples, n_features = raw_data.shape # 总样本量 总特征数
print('samples: {0}| features: {1} | na count: {2}'.format(n_samples, n_features, na_count))
samples: 1000| features: 42 | na count: 4
单变量描述
- 分类变量查看
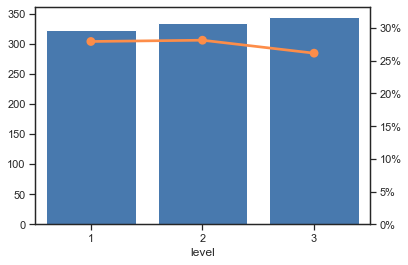
# 分类单变量查看
var_eda(raw_data, 'level', y_col)
plt.show()
# 分类变量批量查看# 定义最优组合
num_plots = len(object_col)
num_cols = math.ceil(np.sqrt(num_plots))
num_rows = math.ceil(num_plots/num_cols)# 设置图片大小
fig= plt.figure(figsize = (24, 18))
# 绘制分类变量eda
for i,x in enumerate(object_col):plt.subplot(num_rows, num_cols, i+1)var_eda(raw_data, x, y_col, fonts=20)
# 设置网格图格式
matplotlib.rcParams.update({'font.size': 25})
fig.suptitle(f'distribution by {y_col}')
fig.text(-0.01, 0.5, 'count', va='center', rotation='vertical')
fig.text(1.01, 0.5, y_col, va='center', rotation='vertical')
plt.tight_layout()
plt.subplots_adjust(wspace =0.25, hspace =0.25) # 调整子图间距
plt.show()
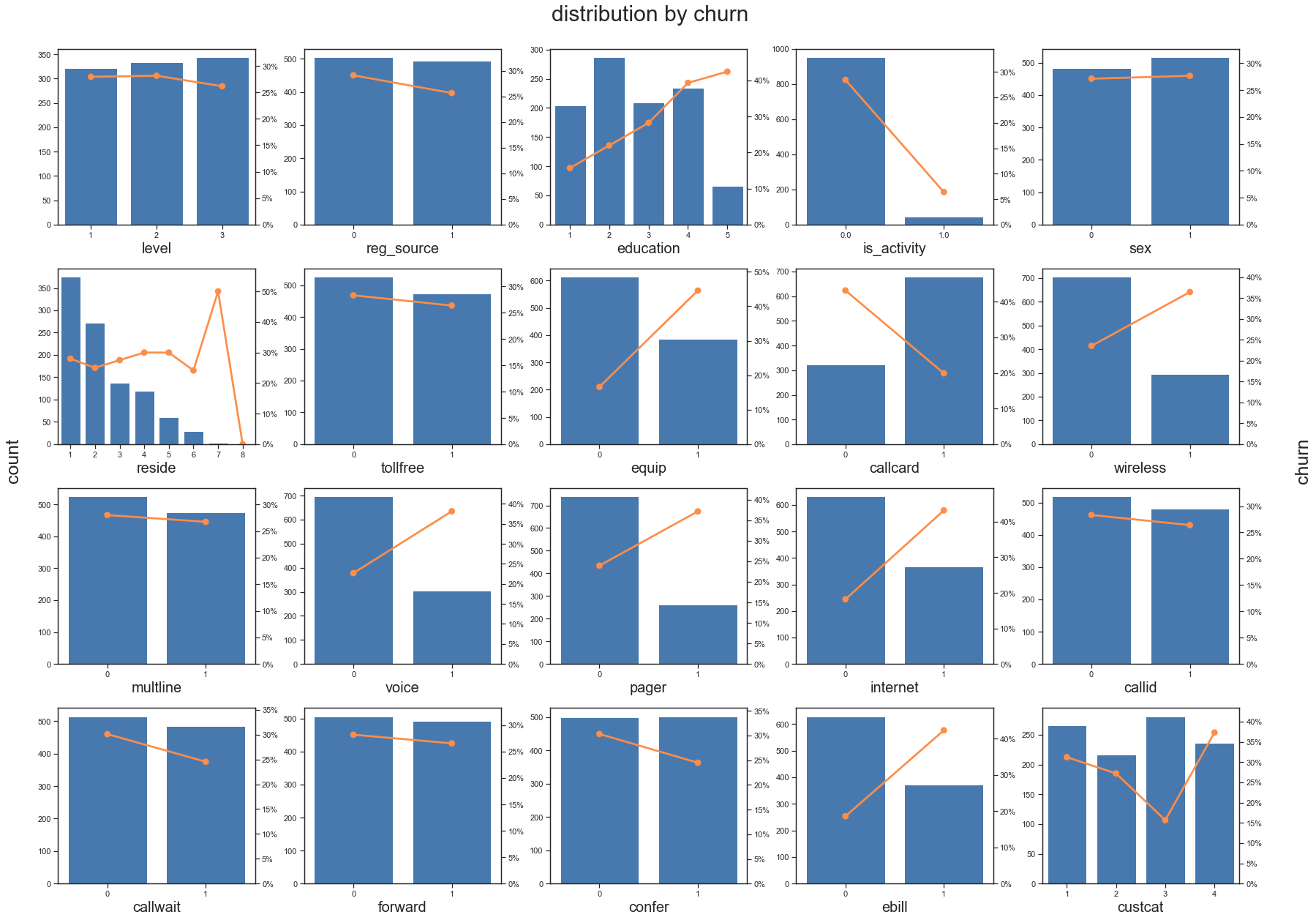
- 连续变量查看
# 连续变量分箱
raw_data_nums=number_col_bins(raw_data, number_col, y_col)
# 连续单变量查看
var_eda(raw_data_nums, 'retention_days', y_col)
plt.show()
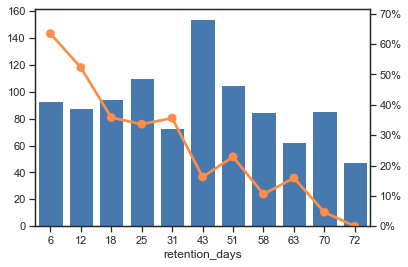
# 连续变量批量查看# 定义最优组合
num_plots = len(number_col)
num_cols = math.ceil(np.sqrt(num_plots))
num_rows = math.ceil(num_plots/num_cols)# 设置图片大小
fig= plt.figure(figsize = (24, 18))
# 绘制分类变量eda
for i,x in enumerate(number_col):plt.subplot(num_rows, num_cols, i+1)var_eda(raw_data_nums, x, y_col, fonts=20)
# 设置网格图格式
matplotlib.rcParams.update({'font.size': 25})
fig.suptitle(f'distribution by {y_col}')
fig.text(-0.01, 0.5, 'count', va='center', rotation='vertical')
fig.text(1.01, 0.5, y_col, va='center', rotation='vertical')
plt.tight_layout()
plt.subplots_adjust(wspace =0.25, hspace =0.25) # 调整子图间距
plt.show()
多变量分析
- 维度交叉
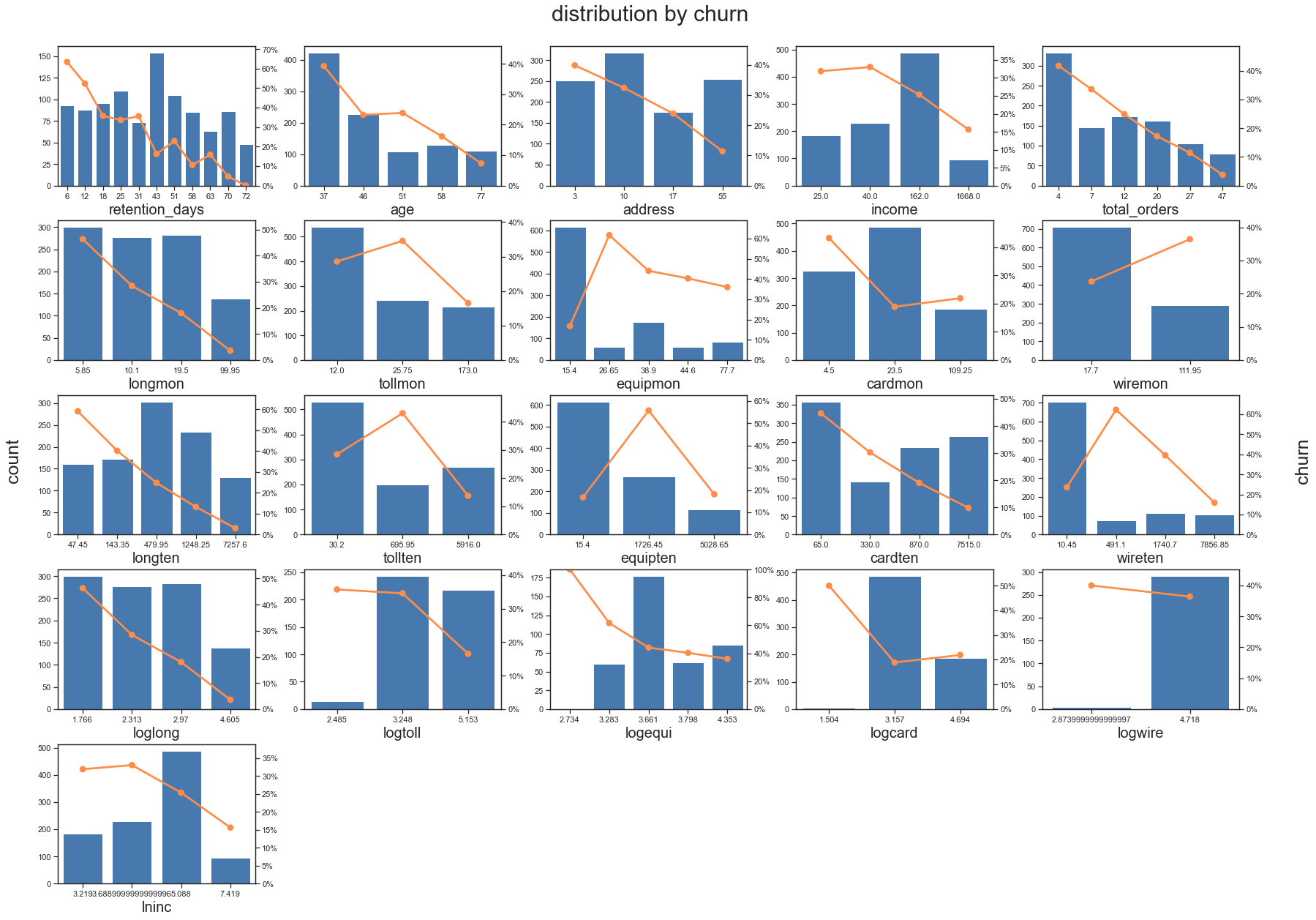
#查看变量交互情况
var_cross_eda(x='level', y='churn', df=raw_data, col='sex', row='voice', hue='reg_source')
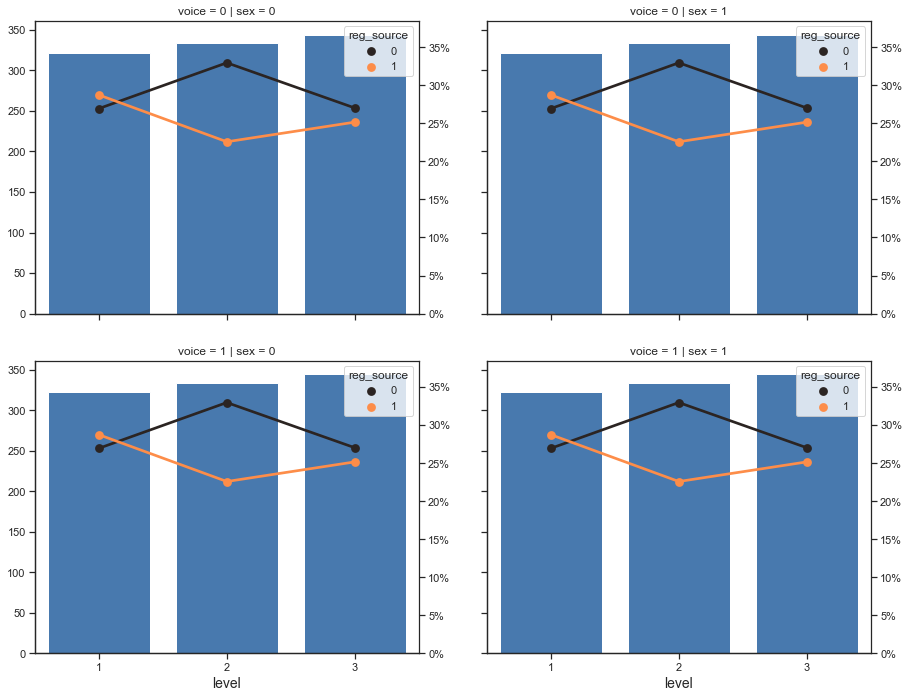
- 相关性热力图
# 特征初筛 特征较多的热图不好看,这里做个初筛降低下维度
# 缺失率>0.7,IV<0.1,相关系数>0.7
ex_lis = ['churn'] # 定义不筛选变量,例如目标变量
df_s1, drop_lst= toad.selection.select(raw_data, raw_data['churn'], empty=0.7, iv=0.1, corr=0.7, return_drop=True, exclude=ex_lis)
print("keep:", df_s1.shape[1], "drop empty:", len(drop_lst['empty']), "drop iv:", len(drop_lst['iv']), "drop corr:", len(drop_lst['corr']))
keep: 18 drop empty: 1 drop iv: 13 drop corr: 10
# 相关性热力图
plt.figure(figsize=(18, 12))
sns.set(font_scale=1.5)
sns.heatmap(df_s1.corr(), cmap='YlGnBu', annot=True, annot_kws = {'size':11})
plt.show()
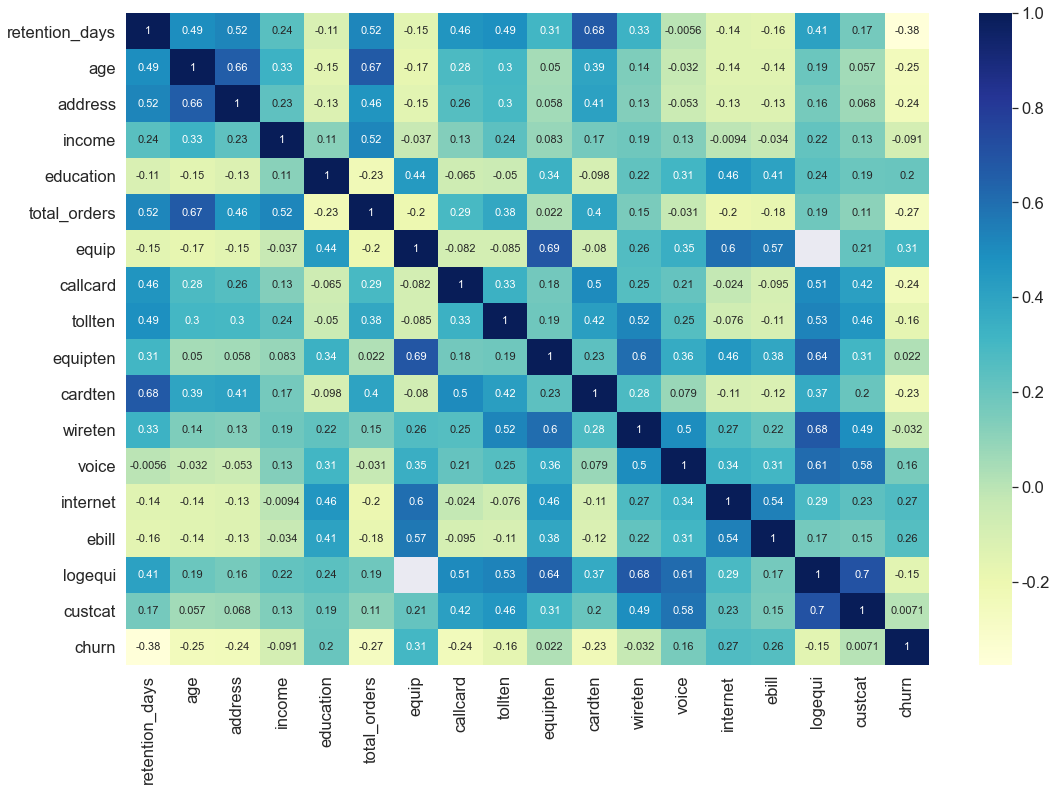
特征工程
特征工程应在训练集上操作,避免加入测试集或验证集信息(主要是标签信息)。基于业务角度的特征工程较少(因为在通过sql提取数据时基本已经处理过了),这也是数据分析与算法工程师的区别之一,算法工程师在清洗数据和特征工程的工作量往往是最大的。
我们常做的特征工程就是缺失值处理、分箱(连续变量离散化)、标签转化(get_dummies、LabelEncoder、OneHotEncoder)、标准化(MinMaxScaler、StandardScaler)。下期会针对常见的不常见的特征工程做个大汇总,敬请期待吧~
# XGBoost无需过多的数据处理
X,y = raw_data.drop(y_col, axis=1),raw_data[y_col] # 分割X,y
# 填充缺失值 因为SMOTE处理时不允许缺失值,XGBoost本身是接受空值的
X = X.fillna(X.mean())
# 样本均衡处理
model_smote = SMOTE(random_state=0) # 建立SMOTE模型对象 设置随机种子,保持采样样本一致
X, y = model_smote.fit_resample(X,y) # 输入数据并作过抽样处理
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3, random_state=0) # 将数据分为训练集和测试集
数据建模
模型训练
# XGB分类模型训练
param_dist = {'n_estimators': 10, 'subsample': 0.8, 'learning_rate':0.1,'max_depth': 10, 'n_jobs': -1, 'eval_metric':'logloss', 'use_label_encoder':False}
model_xgb = xgb.XGBClassifier(**param_dist)
model_xgb.fit(X_train, y_train)
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,colsample_bynode=1, colsample_bytree=1, eval_metric='logloss',gamma=0, gpu_id=-1, importance_type='gain',interaction_constraints='', learning_rate=0.1, max_delta_step=0,max_depth=10, min_child_weight=1, missing=nan,monotone_constraints='()', n_estimators=10, n_jobs=-1,num_parallel_tree=1, random_state=0, reg_alpha=0, reg_lambda=1,scale_pos_weight=1, subsample=0.8, tree_method='exact',use_label_encoder=False, validate_parameters=1, verbosity=None)
模型评估
- 模型初评
model_confusion_metrics(model_xgb, X_test, y_test, 'test')
model_core_metrics(model_xgb, X_test, y_test, 'test')
confusion matrix for test+----------+--------------+--------------+
| | prediction-0 | prediction-1 |
+----------+--------------+--------------+
| actual-0 | 192 | 22 |
| actual-1 | 63 | 159 |
+----------+--------------+--------------+
core metrics for test+------+----------+-----------+--------+-------+------+
| auc | accuracy | precision | recall | f1 | ks |
+------+----------+-----------+--------+-------+------+
| 0.87 | 0.805 | 0.753 | 0.897 | 0.819 | 0.64 |
+------+----------+-----------+--------+-------+------+
- 模型参数调优
# 参数值搜索
adj_parameters = {'max_depth': [1, 3, 5, 10], 'n_estimators': [5, 10, 50, 100], 'learning_rate': [0.01, 0.05, 0.1, 0.2]} # 指定模型中参数的范围# 网格搜索+交叉验证
clf = xgb.XGBClassifier(**param_dist)
model_gs = GridSearchCV(clf, adj_parameters, scoring='roc_auc', cv=5)
model_gs.fit(X_train, y_train) # 训练交叉检验模型
print('Best score is:', model_gs.best_score_) # 获得交叉检验模型得出的最优得分
print('Best parameter is:', model_gs.best_params_) # 获得交叉检验模型得出的最优参数# 获取最佳训练模型
model_xgb = model_gs.best_estimator_ # 获得交叉检验模型得出的最优模型对象
Best score is: 0.8827344902394294
Best parameter is: {'learning_rate': 0.05, 'max_depth': 10, 'n_estimators': 100}
- 核心指标整体评估
model_confusion_metrics(model_xgb, X_test, y_test, 'test')
model_core_metrics(model_xgb, X_test, y_test, 'test')
confusion matrix for test+----------+--------------+--------------+
| | prediction-0 | prediction-1 |
+----------+--------------+--------------+
| actual-0 | 195 | 19 |
| actual-1 | 50 | 172 |
+----------+--------------+--------------+
core metrics for test+-------+----------+-----------+--------+------+-------+
| auc | accuracy | precision | recall | f1 | ks |
+-------+----------+-----------+--------+------+-------+
| 0.915 | 0.842 | 0.796 | 0.911 | 0.85 | 0.691 |
+-------+----------+-----------+--------+------+-------+
- 模型区分能力与排序能力评估
fig = plt.figure(figsize=(18,12))
plt.subplot(221)
plot_roc(model_xgb, X_test, y_test, name='test')
plt.subplot(222)
plot_ks(model_xgb, X_test, y_test, name='test')
plt.subplot(223)
plot_pr(model_xgb, X_test, y_test, name='test')
plt.subplot(224)
plot_lift(model_xgb, X_test, y_test, name='test')
plt.tight_layout()
plt.show()
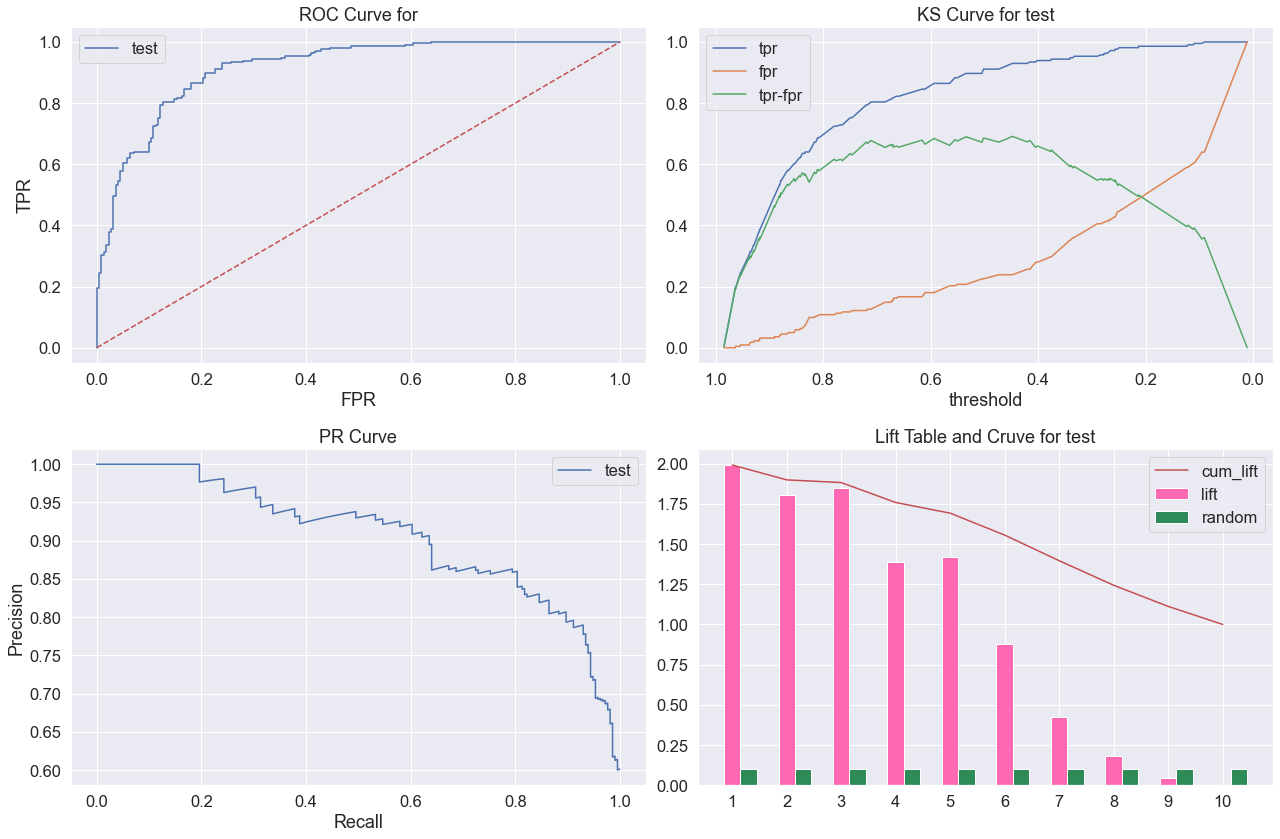
- 模型泛化能力评估
fig = plt.figure(figsize=(18,12))
plt.subplot(221)
plot_cv_box(model_xgb, X_test, y_test, name='test')
plt.subplot(222)
plot_learning_curve(model_xgb, X_test, y_test, name='test')
plt.tight_layout()
plt.show()
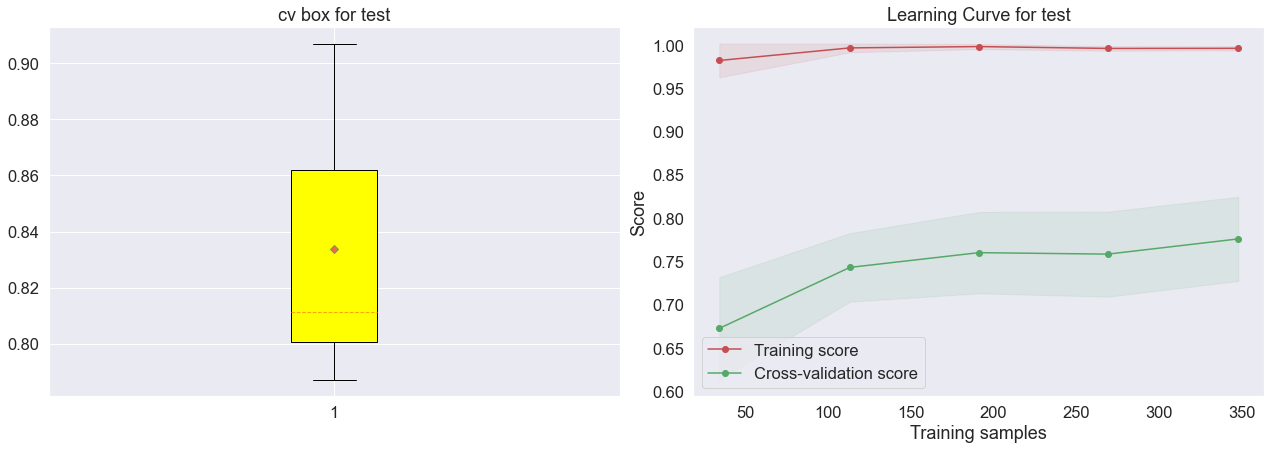
结果展示
- 特征重要性
# 特征重要性排序
fig = plt.figure(figsize=(8,5))
feature_topN(model_xgb, X_test)
plt.show()# 方法2
# xgb.plot_importance(model_xgb, max_num_features=10, importance_type='gain')
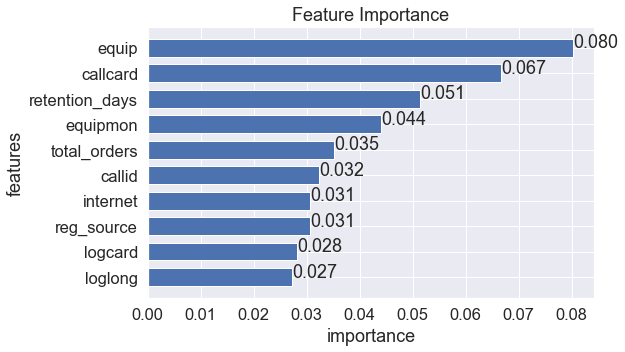
- 预测结果
# 输出预测结果
pre_labels = pd.DataFrame(model_xgb.predict(X_test), columns=['labels']) # 获得预测标签
pre_pro = pd.DataFrame(model_xgb.predict_proba(X_test), columns=['pro1', 'pro2']) # 获得预测概率
predict_pd = pd.concat((pre_labels, pre_pro), axis=1) # 合并数据
predict_pd.head()
| labels | pro1 | pro2 | |
|---|---|---|---|
| 0 | 1 | 0.118373 | 0.881627 |
| 1 | 1 | 0.258572 | 0.741428 |
| 2 | 1 | 0.106693 | 0.893307 |
| 3 | 0 | 0.690167 | 0.309833 |
| 4 | 0 | 0.911336 | 0.088664 |
- 树形规则输出
# 输出树形规则图
xgb.to_graphviz(model_xgb, num_trees=0, yes_color='#638e5e', no_color='#a40000') # 保存图片
image = xgb.to_graphviz(model_xgb, num_trees=1, yes_color='#638e5e', no_color='#a40000')
#Set a different dpi (work only if format == 'png')
image.graph_attr = {'dpi':'400'}
image.render('xgb', directory='xgbPic', format = 'pdf') # 设置参数为png、svg、dot、pdf等
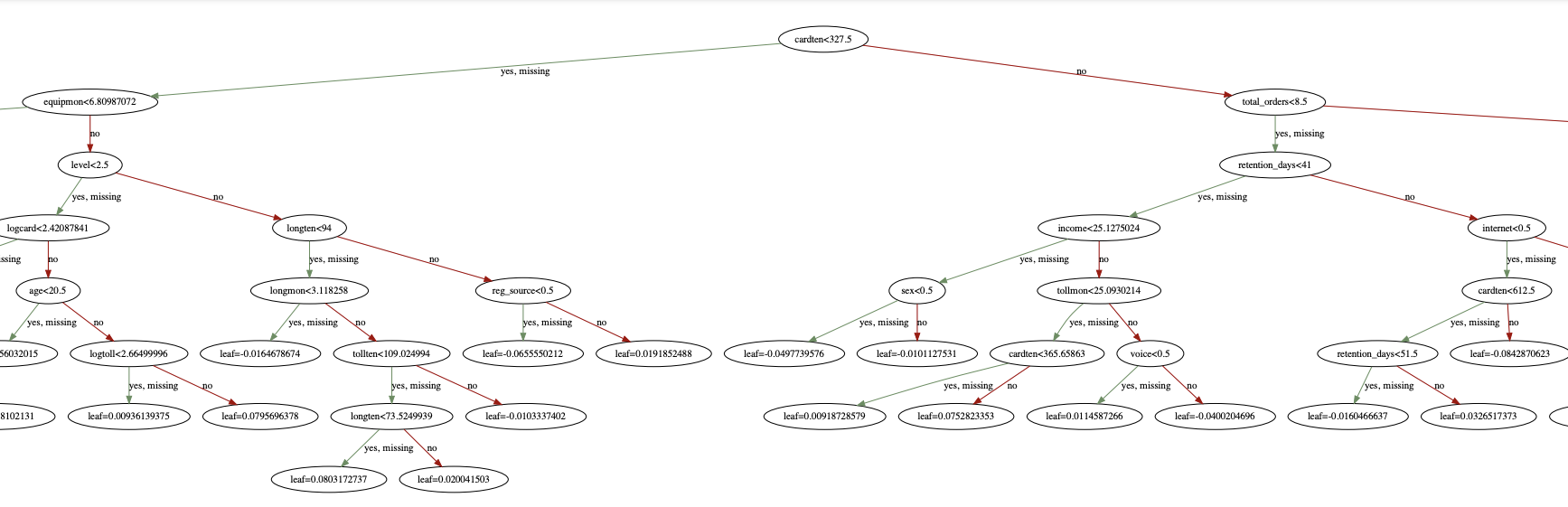
上图就是xgb.pdf文件的部分截图,to_graphviz会展示一颗树的具体规则,例如这里展示的是num_trees=0(第0颗)。
总结
日常在做数据挖掘的时候需要依场景而定,但整体步骤基本一致。读者也可自行尝试构建自己的建模风格~
机器学习算法很多,不过应重点掌握逻辑回归(弱模型质检员)、随机森林(通用模型质检员)和XGBoost(强模型质检员),当然并不是因为它们的质检员身份,而是因为这三类算法的思想很有代表性。
其它类型算法可在工作之余继续学习~
共勉~