Java实习生------Redis常见面试题汇总(数据类型、过期删除策略、缓存雪崩、布隆过滤器)⭐⭐⭐
迪丽瓦拉
2025-05-31 19:38:18
0次
“我不会让我的梦想成为像天上的月亮一样遥不可及的遗憾,我不希望人生有太多这样的遗憾”🌹
目录
Redis五种常见的数据类型的特点以及应用场景?
谈谈你对跳表的理解?
Redis的过期删除策略是什么?
Redis的内存淘汰策略是什么?(注意与过期删除策略进行区分)
什么是缓存雪崩、缓存击穿、缓存穿透?各自的解决方案是什么?
布隆过滤器的原理是什么?缺点与优点?
参考资料:跳表 、图解redis
Redis五种常见的数据类型的特点以及应用场景?
string:
- 介绍:常见的key-value型数据类型
- 内部实现:int和SDS(简单动态字符串,可保存文本数据和二进制数据)
- 应用场景:缓存对象、常规计数、分布式锁、共享session
list:
- 介绍:有序列表,按照插入顺序排序
- 内部实现:双向链表或压缩列表
- 应用场景:消息队列。使用LPUSH+RPOP实现消息保序;使用BRPOP实现消息的阻塞式读取(队列中有消息时并不会通知消费者,消费者会不断调用RPOP);使用BRPOPLPUSH实现了消息的可靠性(消费者在读取消息时可能会发生宕机,所以在读取时先插入另一个list作为备份)
- 缺点:无法支持多个消费者读取同一条消息
hash:
- 介绍:key-value型,但是不同于string,hash的value又分为两部分:filed和value
- 内部实现:压缩列表或哈希表
- 应用场景:缓存对象、购物车
set:
- 介绍:无序列表,不会按照插入顺序进行排序,且会对列表内重复元素进行去重
- 内部实现:哈希表或整数集合
- 应用场景:用户点赞(一个用户只能点一个赞)、共同关注(交集)、抽奖活动(一个用户只能被抽中一次)
zset:
- 介绍:有序集合,不能有重复成员
- 内部实现:压缩列表或跳表
- 应用场景:排行榜、电话或姓名排序
谈谈你对跳表的理解?
定义:跳表是一种类似于链表的数据结构,其插入、查找、删除的时间复杂度都是O(logN),实际上基于一种事件换空间的思想
特点:
- 由许多层组成
- 每一层都是一个有序的链表
- 每一个节点不仅指向同层的下一个节点,还指向下层的节点
- 最下层的链表包含了所有的元素

Redis的过期删除策略是什么?
惰性删除和定期删除
惰性删除:
- 定义:每次从数据库中访问key,才会判断这个key有没有过期;如果过期则进行删除
- 优点:在访问时才会进行删除,所以对CPU友好
- 缺点:如果某个过期key没有被访问到,那么在被访问之前会一直占用内存
定期删除:
- 定义:每次从数据库中抽取一定数量的key进行检查,并删除过期key
- 检查频率:默认每秒十次
- 执行过程:先从数据库中抽取一定数量的key进行检查,如果过期key数量与抽取数量的比值大于四分之一,那么就继续抽取;否则就等待下一轮检查
Redis的内存淘汰策略是什么?(注意与过期删除策略进行区分)
内存淘汰策略可以分为不进行数据淘汰和进行数据淘汰两种策略
不进行数据淘汰:
- noeviction,当内存已经被占满时,redis抛出OOM异常,停止工作
进行数据淘汰:又分为在已经设置过期时间的键中进行淘汰和在所有键中进行淘汰
在设置过期时间的键中进行淘汰:
- volatile-random:在已设置过期时间的键中进行淘汰
- volatile-ttl:淘汰最早过期的键值
- volatile-lru:在已设置过期时间的键中,淘汰最近最久未使用的
- volatile-lfu:在已设置过期时间的键中,淘汰最少使用的
在所有键中进行淘汰:
- allkeys-random:在所有键中随机淘汰
- allkeys-lru:在所有键中,淘汰最近最久未使用的
- allkeys-lfu:在所有键中,淘汰最少使用的
什么是缓存雪崩、缓存击穿、缓存穿透?各自的解决方案是什么?
缓存雪崩:
- 大量数据在同一时间过期或者redis发生故障宕机,此时有大量请求到达,由于无法在redis层进行处理,于是所有的请求都会到达数据库,从而导致数据库压力骤增,严重的话可能导致数据库宕机从而产生连锁反应,导致整个系统崩溃
解决方案:
- 针对数据在同一时间过期:1、均匀设置过期时间,在设置过期时间时给过期时间添加一个随机数。2、使用双key策略,双key分为主key和备key,给主key设置过期时间,但是不给备key设置过期时间,当主key过期时,直接返回备key
- 针对redis故障宕机:1、使用服务熔断机制或请求限流,当有大量请求到达redis时,redis无法处理,可以直接返回错误,使请求不再访问数据库,redis恢复正常之后,再允许业务访问;只将少部分请求进行处理,再多的请求就直接在入口处拒绝。2、构建redis集群,当主节点故障之后,使用从节点替代
缓存击穿:
- 某个热点数据过期,此时有大量请求访问该热点数据,无法从缓存中读取,所有请求就会到达数据库,导致数据库压力骤增
解决方案:
- 互斥锁:保证同一个时间只能有一个业务更新缓存
- 不给热点数据设置过期时间,如果热点数据被淘汰,使用消息队列通知后台线程
缓存穿透:
- 用户所访问的数据既不在缓存中,也不在数据库中,大量的请求出现时,会穿过缓存层去访问数据库,导致数据库被击垮
解决方案:
- 对非法请求进行限制,在API入口处判断是否有非法参数,如果有则进行拦截
- 缓存空值或默认值,如果发现缓存穿透现象,则直接在缓存层中缓存一个空值或默认值,后续请求到达时,直接返回
- 使用布隆过滤器来快速判断数据是否存在,避免请求直接查询数据库
布隆过滤器的原理是什么?缺点与优点?
布隆过滤器由初始值都为0的位图数组和N个哈希函数组成,当写入数据库时,先在布隆过滤器中做一个标记,等查询这个数据时,先到过滤器中进行查询
执行过程:
- 先由N个哈希函数对数据做哈希计算,得到N个哈希值
- 用这个N个哈希值对位图数组的长度进行取模运算,得到N个值
- 将这N个值在位图数组中对应的的位置设置为1
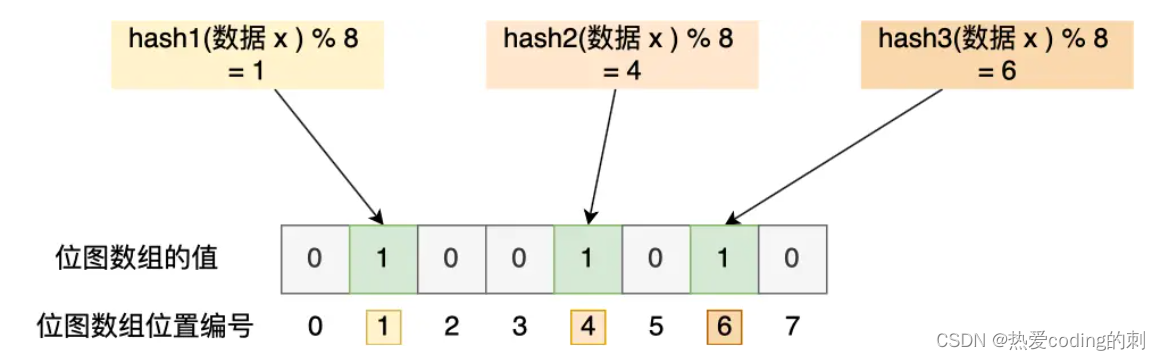
因为布隆过滤器使用到了哈希函数,所以存在哈希冲突;但是,使用布隆过滤器进行查找比较高效,如果布隆过滤器说数据存在,那么数据库中可能不存在这个数据;但是如果说不存在,那么数据库中就一定不存在这个数据

整理面经不易,觉得有帮助的小伙伴点个赞吧~感谢观看~
相关内容
热门资讯
Linux-scheduler...
四、调度域 SDTL结构 linux内核使用SDTL结构体来组织CPU的层次关系 struct sc...
leetcode - 2379...
Description You are given a 0-indexed string block...
Retinanet网络与foc...
参考代码:https://github.com/yhenon/pytorch-reti...