系列文章 之 一文纵览【机器学习】必备步骤,祝(助)你(我们) 科研/实验 不再踌躇
金风玉露一相逢,便胜却、人间无数
平岗上,长巷里,人至不去,只愿为君转轴拨弦三两声
只愿见君素衣文扇倾依旧
青青子衿,悠悠我心,唯梦闲人,却不梦君。
虽千万人,吾往矣.
🎯作者主页:追光者♂🔥
🌸个人简介:计算机专业硕士研究生💖、2022年CSDN博客之星人工智能领域TOP4🌟、阿里云社区特邀专家博主🏅、CSDN-人工智能领域新星创作者🏆、预期2023年10月份 · 准CSDN博客专家📝
【无限进步,一起追光!】
🍎欢迎大家 点赞👍 收藏⭐ 留言📝
🌿机器学习具体要做哪些事情呢?本系列文章是使读者了解机器学习的大致步骤。通过阅读本系列文章,读者将对机器学习算法基础的处理流程有所理解,并学习到机器学习的基本概念。
一文纵览——机器学习步骤
- 🍄一、数据的重要性
- 🍑1.0 先导知识
- 💦1.0.1 收集数据、数据预处理的重要性
- 💦1.0.2 scikit-learn 包说明
- 🍑1.1 数据和学习的种类
- 🍑1.2 了解示例数据
- 🍄二、有监督学习(分类)的例子
- 🍑2.1 导入数据
- 🍑2.2 变量赋值、查看变量信息
- 🍑2.3 方法的实现
- 🍑2.4 评估方法
- 🍑2.5 本小节完整code(1)查看数据信息
- 🍑2.6 本小节完整code(2)使用逻辑回归来预测
- 🍄三、无监督学习(聚类)的例子
- 🍑3.1 导入数据、查看数据
- 🍑3.2 用k-means聚类算法实现聚类
- 🍑3.3 可视化,查看聚类结果
- 🍑3.4 本小节完整code(截止到上述)
- 🍄四、 附:图形的种类和画法:使用Matplotlib显示图形的方法
- 🍑4.1 “魔法命令” %matplotlib inline
- 🍑4.2 较为严密的做法
- 🍑4.3 绘制各种图形
- 🥝4.3.1 绘制 散点图
- 🥝4.3.2 绘制 直方图
- 🥝4.3.3 绘制柱状图
- 🥝4.3.4 绘制 折线图
- 🥝4.3.5 绘制 箱形图
- 🍑4.4 对于该红酒数据集的处理(查看)
- 🍄五、使用pandas 理解和处理数据
🍄一、数据的重要性
众所周知,在使用机器学习算法时,必须要有汇总并整理到一定程度的数据。以数据为基础,按照规定的法则进行学习,最终才能较好地完成预测任务。
倘若没有数据,就不能进行机器学习。换句话说,收集数据是首先要做的事情。
这一小节将细致说明机器学习训练过程的一系列流程。为了便于大家的理解,本小节基于示例数据进行讲解,使用的是主流机器学习库 scikit-learn 包内置的数据。这个数据便于入手,大家可以自由使用!
🍑1.0 先导知识
💦1.0.1 收集数据、数据预处理的重要性
在实际用机器学习解决问题之前,要先
收集数据,有的时候还需要进行问卷调查,甚至说购买数据!紧接着,需要为收集到的数据 人工标注答案标签,或者将其加工为机器学习算法易于处理的形式,删除无用的数据,加入从别的数据源获取到的数据等。
此外,基于平均值和数据分布等统计观点查看数据,或者使用各种图表对数据进行可视化,把握数据的整体情况也很重要。有的时候,还需要对数据进行正则化处理。
以上的这些描述,被称作 数据预处理,想必大家都曾听说过:机器学习工作80%以上的时间都花在了数据预处理上。
💦1.0.2 scikit-learn 包说明
scikit-learn是一个机器学习库,它里面包含了各种用于机器学习的工具,且可以免费使用。
scikit-learn实现了很多有监督学习和无监督学习的算法,是一套包含了用于评估的工具、方便的函数、示例数据集等的工具套件。在机器学习领域,scikit-learn已成为事实上的标准库,它具有两大特点:一个是操作方法统一,其二是易于在Python中使用。
🍑1.1 数据和学习的种类
我们在上面曾提到,没有数据,就无法正常进行机器学习。那么具体地,机器学习需要怎样的数据呢?
一般来说,机器学习需要的是二维的表格形式的数据,在表格的每一列中含有表示数据本身特征的多种信息,每一行则是有多个信息构成的数据集。例如,在一周中,统计了七天的天气状况,例如每天的平均温度,最高温度,最低温度,天气晴朗与否等数据。
| 周 | 最低气温 | 最高气温 | 日出 | 日落 | 天气晴朗与否(晴朗:1;不晴朗:0) |
|---|---|---|---|---|---|
| 周一 | -2° | 8° | 05:47 | 17:41 | 1 |
| 周二 | -5° | 7° | 05:50 | 17:42 | 1 |
| 周三 | 0° | 13° | 05:45 | 17:52 | 1 |
| 周四 | -1° | 9° | 05:52 | 17:53 | 0 |
| 周五 | -6° | 2° | 05:52 | 17:50 | 0 |
| 周六 | -8° | 6° | 05:47 | 17:45 | 1 |
| 周日 | -7° | 5° | 05:44 | 17:51 | 0 |
这里,我们可以思考一下进行天气晴朗与否预测的问题。显然,每天的天气数据(状况)是特征值,有时也依据场景的不同,也将其称之为特征变量或输入变量,即 feature。
那么天气是否晴朗,就是这里的预测对象,也可成为目标变量,有时也称之为标签或者类别标签数据,即 target。
🍑1.2 了解示例数据
在本小节中,我们来看一下scikit-learn包中内置的示例数据。以鸢尾花(iris)数据为例。这里提一下,在Python中 用于处理数据的工具有 pandas,它常与scikit-learn搭配使用~
请看示例code:
# 昵 称:XieXu
# 时 间: 2023/3/17/0017 9:48import pandas as pd
from sklearn.datasets import load_irisdata = load_iris()X = pd.DataFrame(data.data, columns=data.feature_names)
Y = pd.DataFrame(data.target, columns=["Species"])df = pd.concat([X, Y], axis=1)
print(df.head())
运行上述代码,在PyCharm的Console控制台中可以看到:

如果是在Jupyter Notebook中运行上述code,则也可以看到:
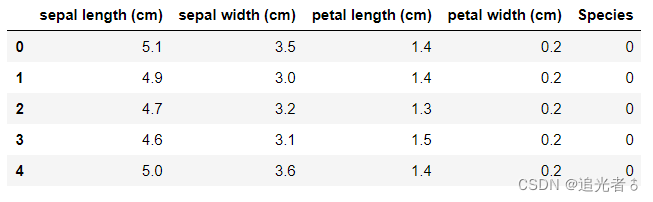
显然,在列的方向上,有 sepal length(cm),sepal width(cm),petal length(cm),petal width(cm),Species这五种信息,它们分别代码鸢尾花的萼片长度、萼片宽度、花瓣长度、花瓣宽度、品种。
其中,前4列是表示特征的特征值,最后1列是目标变量。在该数据集中,目标变量的值为0、1、2这三个值之一。
🍄二、有监督学习(分类)的例子
下面来介绍基于有监督学习解决分类问题的实现方法。
以美国威斯康星州乳腺癌数据集为例。该
数据集包含30个特征值,目标变量的值为“良性”或者“恶性”。数据数量共569条,其中“恶性”数据占212条,“良性数据”占357条。很显然,这是通过30个特征值来判断结果是恶性还是良性的二元分类问题。
🍑2.1 导入数据
和上面示例一样,这个数据集也是可以通过scikit-learn包读取。
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer() # 记得需要自己主动加(),否则下边无法正常调用!
上述两行代码用于导入scikit-learn内置的数据集,并将所读取的数据保存在变量data中。
🍑2.2 变量赋值、查看变量信息
然后我们从该数据集中取出特征值赋给X,取出目标变量赋给y。
X = data.data
y = data.target
-
X是由多个特征值向量所构成的,我们将其转为矩阵形式来处理,故而在上面用大写英文字母作为变量值。
-
y 是目标变量的向量,其中元素值含义是:0表示恶性(M),1表示良性(B)。
print("X.shape:", X.shape) # X.shape: (569, 30)
print("y.shape:", y.shape) # y.shape: (569,)
X是大小(形状)为569 x 30的数据,可以将其看做569行,30列的矩阵。在这里,虽然y是向量,但将其当做569行,1列的矩阵之后,X和y的行就能够一一对应了。
指的指出的是,如果读者想要较为详细地了解这个数据集,那么应当具备相应地医学知识。但是在这里我们仅仅将其作为数据集来使用,即对其进行有监督学习的二元分类。其特征值共有30个,分为平均值,误差值,最差值三类,每一类又包含十项,即半径、伦理、面积等等。本次示例中,我们着眼于平均值、误差值、最差值这三类数据中的平均值。
X = X[:, :10]
上一行操作,使得只有平均值被重新赋值给了变量X,用作特征值的数据现在缩减到了10项。
🍑2.3 方法的实现
这里使用的分类算法是“逻辑回归”,有过机器学习基础知识的朋友应该了解,虽然其名字中带有“回归”,但是它其实可用于分类。
from sklearn.linear_model import LogisticRegressionmodel = LogisticRegression()
补充说明:在使用scikit-learn进行模型的初始化和训练时,读者有可能看到
输出警告信息,即FutureWarning,指的是对将来有可能会变更的功能的通知,在训练不收敛时可能会出现该情况。
上述code中,通过导入scikit-learn的LogisticRegression类,并创建LogisticRegression的实例,将已经初始化的模型赋给model。
model.fit(X,y)
上述code,使用model(即LogisticRegression的实例)的fit()方法训练模型,该方法的参数是特征值X和目标变量y。在调用fit方法后,model成为学习后的模型。
y_pred = model.predict(X)
上述code,即使用学习后的模型model的predict方法对学习时用到的特征值X进行预测,并且将预测结果赋给变量y_pred。
🍑2.4 评估方法
在本小节中,我们使用scikit-learn中的accuracy_score函数来查看正确率。(关于评估方法,在之前曾经记录过:2023.1.29,周日【图神经网络 学习记录12】图 注意力机制网络HAN模型:详细断点调试(Debug)过程;模型的几个常见评价指标:TP,TN,FP,FN;查准率,查全率;macro-F1),后面还会继续抽时间记录的~ 可以期待一下哈~!
from sklearn.metrics import accuracy_scoreprint("accuracy_score(y,y_pred):", accuracy_score(y, y_pred))
# accuracy_score(y,y_pred): 0.9121265377855887
此处,代码的输出结果是 学习后的模型预测的结果 y_pred 相对于作为正确答案的目标变量y的正确率。
事实上,这里的验证通常应当使用另外准备的一些不用于学习的数据来进行,否则易容易产生
过拟合现象。过拟合是有监督学习很严重的一个问题。我们知道,有监督学习追求的是正确预测未知的数据,但其实现在输出的正确率是使用之前学习时用过的数据计算出来的。这就意味着,我们不知道模型对于未用于学习的未知数据的预测性能的好坏。也就是 我们不知道得到的学习后的模型是不是真正的优秀。
除此之外,对于评估方法,只看争取率就能判断结果是否正确吗?这是一个值得思考的问题。根据实际数据的特性不同,在有些情况下不能保证分类是正确的。就比如说本次使用的数据中有“恶性”数据212条,有“良性”数据357条,这可以说是在一定程度上均衡的数据集。
其实,对于“良性”、“恶性”等极不均衡的数据,光看正确率是无法判断结果是否正确的。例如,这里有另外一组数据,是在30岁~39岁人群的癌症检测数据。通常来说,诊断为恶性的数据只会占整体的百分之几,因为大多数人是没有肿瘤或者说肿瘤是良性的,这是符合大众认知的。那么对于这样的数据,如果模型将所有的样本都判断为良性的,尽管其正确率很高,但光看正确率,也无法正确评估这个模型。
🍑2.5 本小节完整code(1)查看数据信息
部分内容可以合理添加注释,请合理打开就可看到预测结果以及数据集的部分信息。
# 昵 称:XieXu
# 时 间: 2023/3/18/0018 10:06from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_splitdata = load_breast_cancer()cancers = load_breast_cancer()
X = cancers.data # 获取特征值
Y = cancers.target # 获取标签
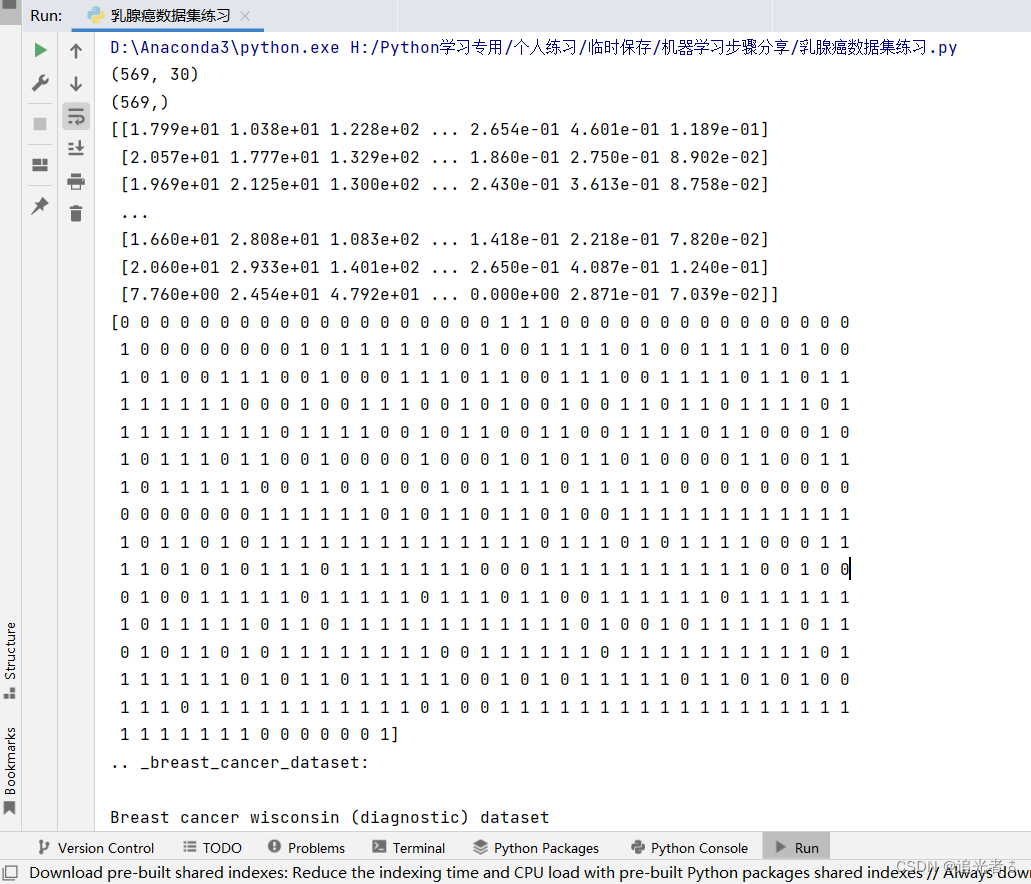
print(X.shape) # 查看特征形状 (569, 30)
print(Y.shape) # 查看标签形状 (569,)
print(X)
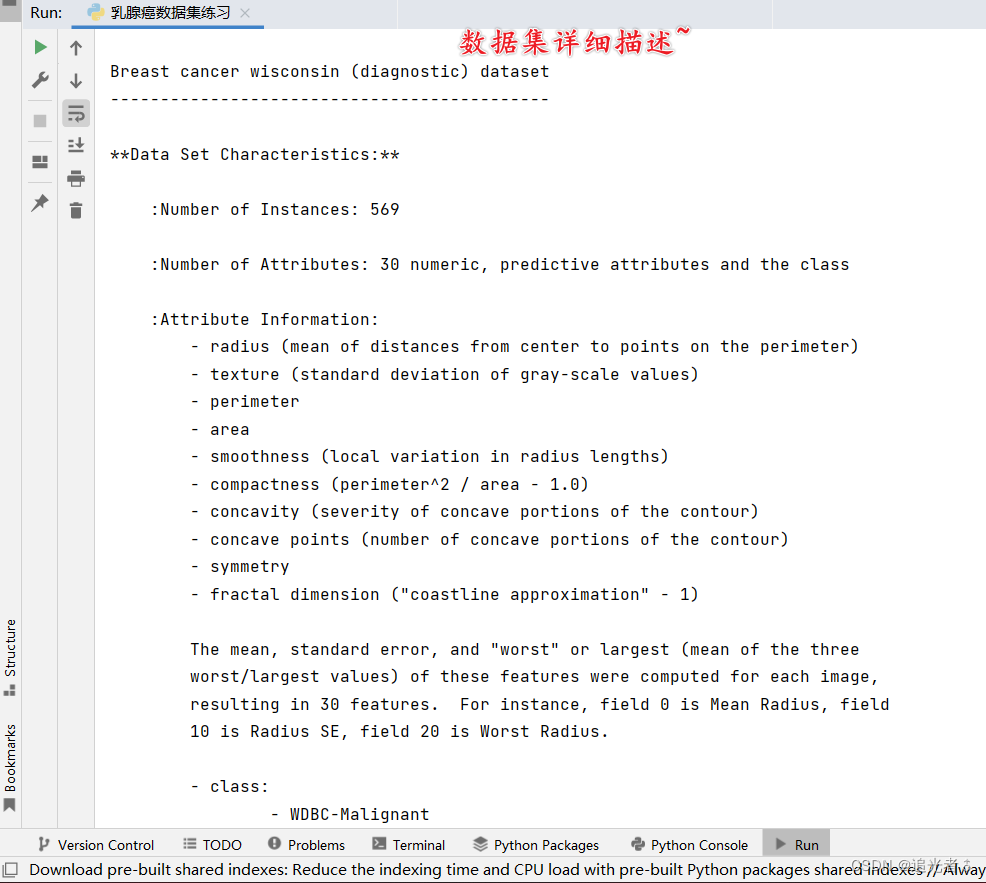
print(Y)print(data.DESCR) # 查看数据集描述 Breast cancer wisconsin (diagnostic) datasetprint('特征名称')
print(data.feature_names) # 特征名
print('分类名称')
print(data.target_names) # 标签类别名# 注意返回值: 训练集train,x_train,y_train,测试集test,x_test,y_test
# x_train为训练集的特征值,y_train为训练集的目标值,x_test为测试集的特征值,y_test为测试集的目标值
# 注意,接收参数的顺序固定
# 训练集占80%,测试集占20%
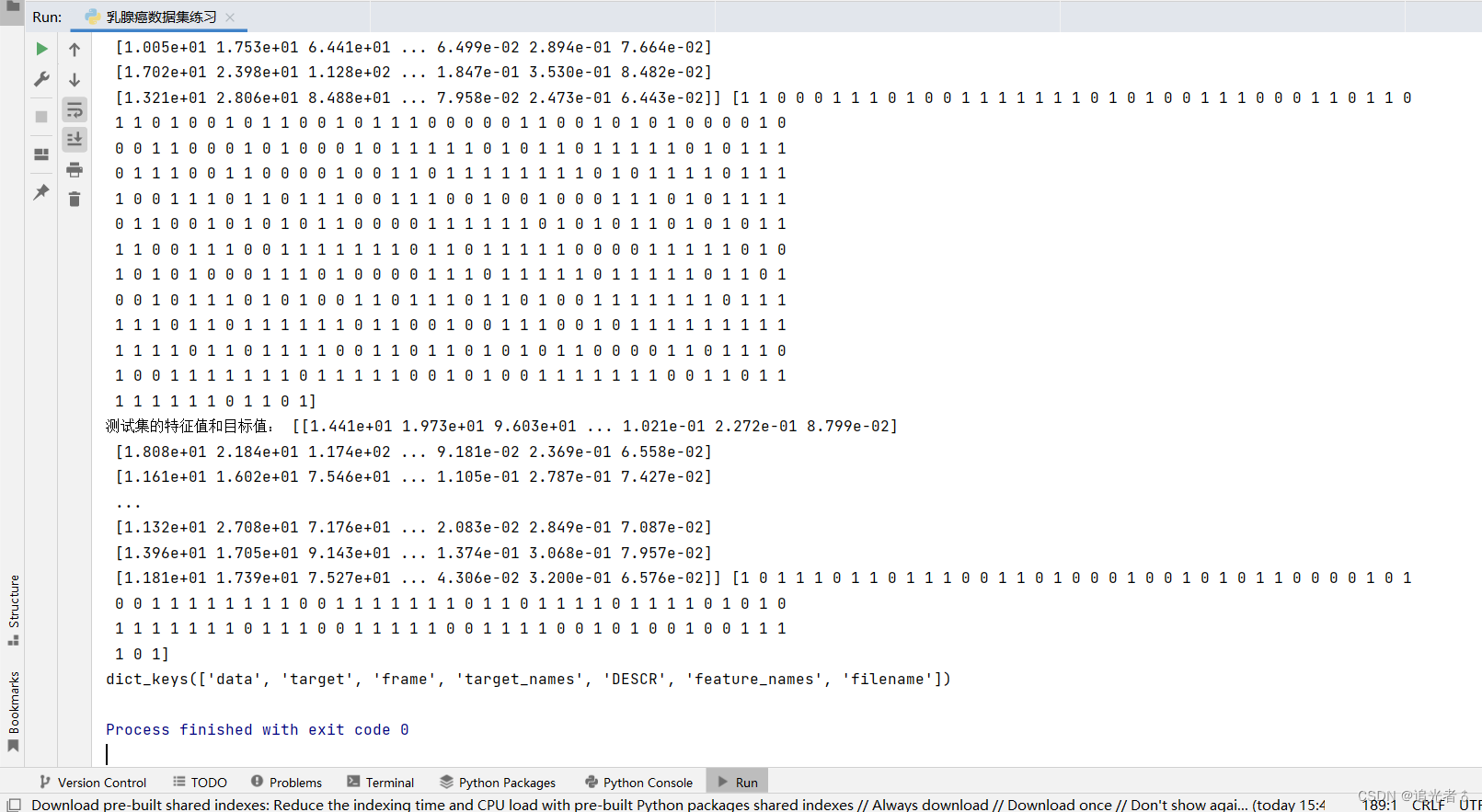
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2)
print('训练集的特征值和目标值:', x_train, y_train)
print('测试集的特征值和目标值:', x_test, y_test)# dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
print(cancers.keys())
由于控制台打印的内容较长,因此这里截取几张图片示例:
完整的输出内容还请各位测试查看~
🍑2.6 本小节完整code(2)使用逻辑回归来预测
# 导入乳腺癌数据集
from sklearn.datasets import load_breast_cancerdata = load_breast_cancer() # 记得需要自己主动加(),否则下边无法正常调用!# 特征值和标签的赋值
X = data.data
y = data.target
# print("X.shape:", X.shape) # X.shape: (569, 30)
# print("y.shape:", y.shape) # y.shape: (569,)# print(X)X = X[:, :10]# print("\n", "*" * 66, "\n")
# print(X)# 方法的实现
# 使用逻辑回归算法
from sklearn.linear_model import LogisticRegressionmodel = LogisticRegression() # 这种都要记得后面的小括号()需要自己主动添加
model.fit(X, y)y_pred = model.predict(X)# print("y_pred:", y_pred)# 评估方法
from sklearn.metrics import accuracy_scoreprint("accuracy_score(y,y_pred):", accuracy_score(y, y_pred))
# accuracy_score(y,y_pred): 0.9121265377855887
部分输出的内容,已经放到注释中了。并且,结合上面的查看数据信息,可以更完整地理解该部分。
🍄三、无监督学习(聚类)的例子
本小节中,我们来看一下无监督学习的聚类问题的实现方法的各个步骤。和之前一样,这里我们也使用scikit-learn包。
本次所采用的数据集是scikit-learn包内置的与葡萄酒种类有关的数据集。该数据集有13个特征值,目标变量为葡萄酒的种类。
由于本次介绍的是无监督学习的聚类算法,因此不使用目标变量。为了简单起见,我们使用13个特征值中的alcohol(酒精度)和color_intensity(色泽)两个特征值。我们对该数据集应用k-means聚类算法,将其分为3个簇。
葡萄酒数据的特征值:(注:这里仅以第一行为例)
| alcohol | malic_acid | ash | alcalinity_of_ash | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | diluted_wines | proline | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127.0 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065.0 |
| 1 | 13.20 | ||||||||||||
| 2 | 13.16 | ||||||||||||
| 3 | 14.37 | ||||||||||||
| 4 | 13.24 |
本次使用的两个特征值:
| alcohol | color_intensity | |
|---|---|---|
| 0 | 14.23 | 5.64 |
| 1 | 13.20 | 4.38 |
| 2 | 13.16 | 5.68 |
| 3 | 14.37 | 7.80 |
| 4 | 13.24 | 4.32 |
🍑3.1 导入数据、查看数据
先使用scikit-learn包来加载该数据集:
from sklearn.datasets import load_wine
data = load_wine()
从数据集中选择alcohol列和color_intensity列作为特征值赋给X。(为了在显示结果时,用二维图形对结果进行可视化)
X = data.data[:, [0, 9]]
print("X.shape:",X.shape) # X.shape: (178, 2)
可以从注释中看出,特征值是178行 2列的数据。
🍑3.2 用k-means聚类算法实现聚类
导入并使用实现k-means算法的KMeans类,初始化KMeans类,将它作为学习前的模型赋给变量model,通过n_clusters参数,将数据分为三个簇:
from sklearn.cluster import KMeansn_clusters = 3
model = KMeans(n_clusters=n_clusters)
向学习前的模型model的 fit_predict()方法传入特征值数据,预测结果赋给变量pred:
pred = model.fit_predict(X)
🍑3.3 可视化,查看聚类结果
将聚类的结果可视化。
由于本次使用的特征值只有两种,因此绘制二维图形即可实现结果的可视化。通过下述code可实现可视化。
import matplotlib.pyplot as pltfig, ax = plt.subplots()
ax.scatter(X[pred == 0, 0], X[pred == 0, 1], color='red', marker='s', label='Label1')
ax.scatter(X[pred == 1, 0], X[pred == 1, 1], color='blue', marker='s', label='Label2')
ax.scatter(X[pred == 2, 0], X[pred == 2, 1], color='green', marker='s', label='Label3')
ax.scatter(model.cluster_centers_[:, 0], model.cluster_centers_[:, 1], s=200, color='yellow', marker="*",label="center")
ax.legend()
plt.show()
特征值的可视化:
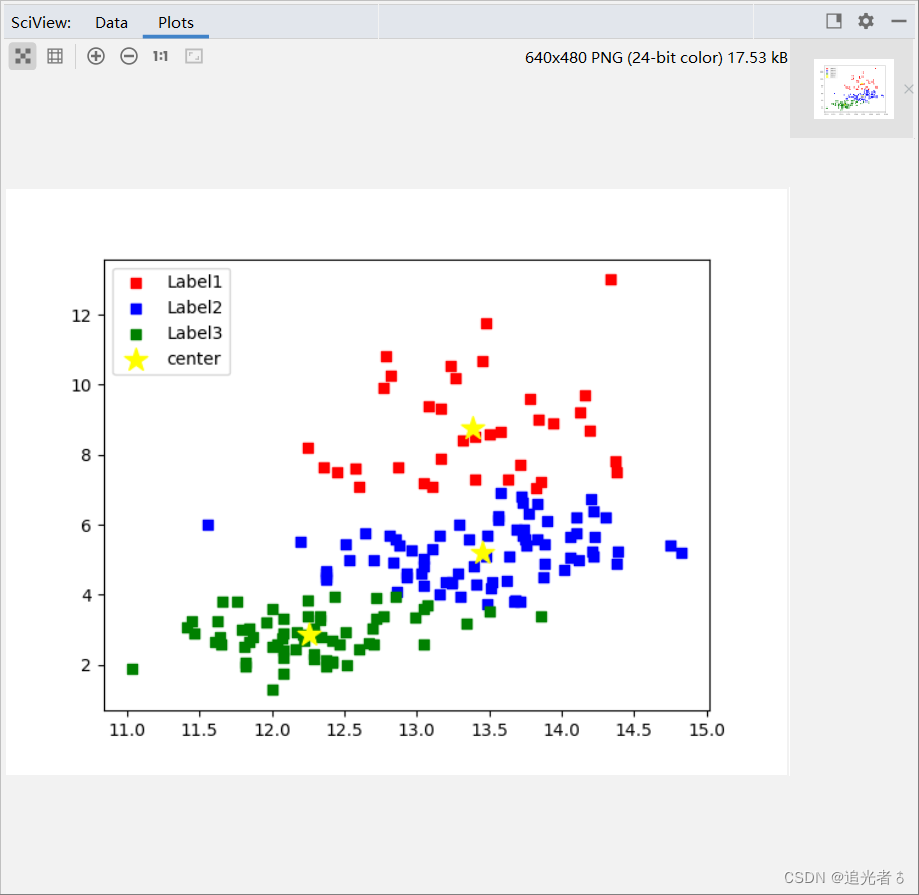
从数据点的颜色,我们可以看出每种酒属于哪个簇。上图中,3个黄色的星星是各个簇的重心,即分别是这3个簇的代表点。
进一步分析。原本通过酒精度、色泽等变量表示的葡萄酒,现在以“属于哪个簇”这种简洁直观的形式展示了出来。此外,如果大家要想了解各个簇具有什么特征,只需要查看作为代表点的重心的值即可。例如,第3个簇的特点是“酒精度低、色泽淡”。
再者,通过k-means算法实现的剧烈是以“将酒精百分之多少以上的数据分到第一个簇”之类的规则进行聚类的,这些规则不是由我们预先设置的,而是由算法自动进行聚类得出的。这一点是很重要的,这说明该算法具有通用性,可应用于葡萄酒之外的数据。
🍑3.4 本小节完整code(截止到上述)
# 昵 称:XieXu
# 时 间: 2023/3/18/0018 18:17# 加载葡萄酒数据集
from sklearn.datasets import load_winedata = load_wine()X = data.data[:, [0, 9]]
print("X.shape:", X.shape) # X.shape: (178, 2)# 用k-means算法实现聚类
from sklearn.cluster import KMeansn_clusters = 3
model = KMeans(n_clusters=n_clusters)pred = model.fit_predict(X)# 可视化,查看聚类结果
import matplotlib.pyplot as pltfig, ax = plt.subplots()
ax.scatter(X[pred == 0, 0], X[pred == 0, 1], color='red', marker='s', label='Label1')
ax.scatter(X[pred == 1, 0], X[pred == 1, 1], color='blue', marker='s', label='Label2')
ax.scatter(X[pred == 2, 0], X[pred == 2, 1], color='green', marker='s', label='Label3')
ax.scatter(model.cluster_centers_[:, 0], model.cluster_centers_[:, 1], s=200, color='yellow', marker="*",label="center")
ax.legend()
plt.show()
🍄四、 附:图形的种类和画法:使用Matplotlib显示图形的方法
在此之前,2022年下半年我就曾出过对应的Blog记录如何使用Python中的matplotlib库来绘制各种常见的图形,感兴趣的朋友可以看看哈:(选看!)
-
【Python】使用 Matplotlib 和 Numpy 的 知识绘制一个简单的 二次函数图像 || 同一坐标系下绘制多个函数图像
-
【Python】使用 Matplotlib 绘制“三角函数”图像 || plt.subplot(2, 2, 3) 将图像分区 || plt.plot(x, y, “r-v“) 中第三个参数说明
-
【Python】绘制 对数函数
-
【Python】绘制 指数函数 || 同一个坐标系绘制多个指数函数 || 数学的魅力
-
【Python】使用 Matplotlib 和 Numpy 的 知识绘制一个简单的 二次函数图像 || 同一坐标系下绘制多个函数图像
-
【机器学习 之 Matplotlib】绘制折线图 基础练习
-
【Python 之 Numpy】数组 基本处理(一)
-
【Python & 机器学习 基础】绘制 sigmoid 函数曲线 || exp:以e为底的指数函数(科普向)
-
【Python】turtle 库:基本介绍 || 绘制简单图形:圆形、正方形、正六边形、小风车、等边三角形、五角星、奥运五环、四叶花瓣、太阳花、五星红旗、正方形螺旋线
包括但不限于上述文章,我想应该会对大家在Python绘图(基于matplotlib库)有一个比较好的帮助!
这里,也算是再回顾一下Python中的简单绘图吧!
🍑4.1 “魔法命令” %matplotlib inline
有些时候,我们通过代码在Jupyter Notebook页面上显示图形。在code单元格内,运行 %matplotlib inline 这个以 % 开始的“魔法命令”后,即使不运行 matplotlib中的show()方法,页面上也会输出图形。
就如下图:
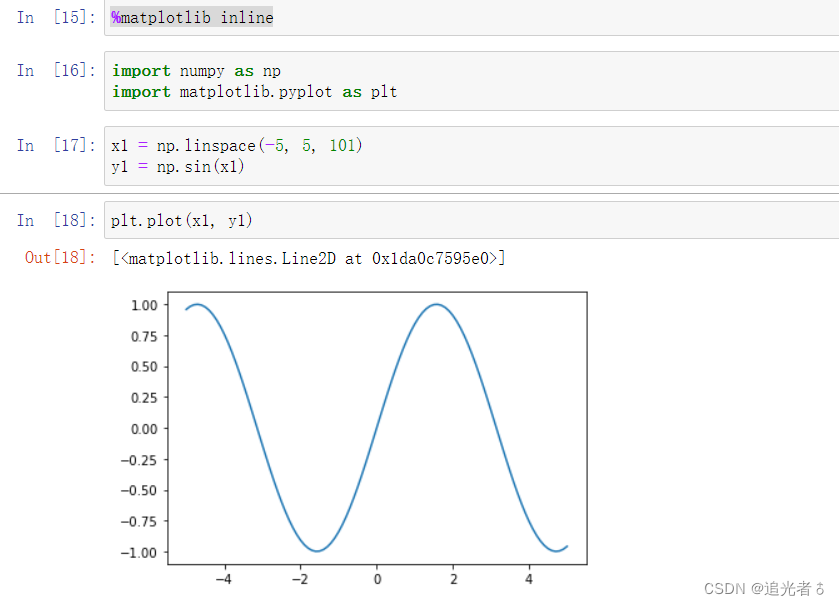
当然!在PyCharm中,不写魔法命令即可:(写了也无法识别,会报错哦!)
# 昵 称:XieXu
# 时 间: 2023/3/18/0018 19:17
# %matplotlib inline
import numpy as np
import matplotlib.pyplot as pltx1 = np.linspace(-5, 5, 101)
y1 = np.sin(x1)plt.plot(x1,y1) # 声明绘图!
plt.show()
当然,需要写show()方法,否则图形也出不来呀!!
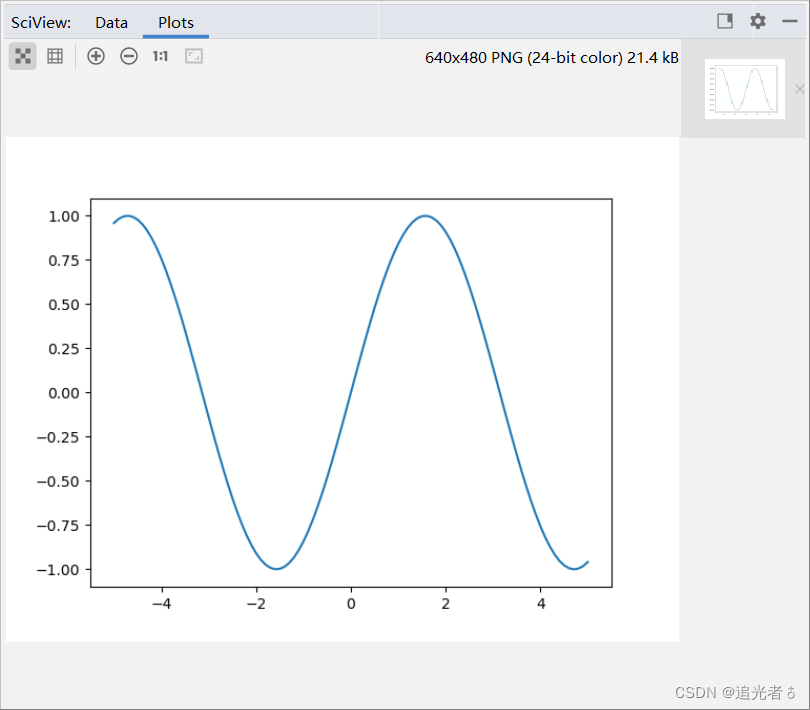
上面的例子中,绘制的是sin函数的曲线,其中x1中保存的是为了显示sin曲线而生成的-5到5的101个数据;而y1中保存的是使用Numpy的sin函数生成的数据。
事实上,我们在这里只是简单地调用了plt.plot(),只是声明了绘图,其实这并不是Matplotlib中绘制图形的代码的标准写法。下面我们来介绍较为严密的做法,即
先创建要绘制的对象,然后再输出图形。
如下:
🍑4.2 较为严密的做法
import numpy as np
import matplotlib.pyplot as pltx1 = np.linspace(-5, 5, 101)
y1 = np.sin(x1)fig, ax = plt.subplots()
ax.set_title("Sin") # 显示图形名称(标签)
ax.set_xlabel("rad") # 显示X轴信息
ax.plot(x1, y1) # 严密地面向对象声明的方法
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles, labels)
plt.show()
效果:
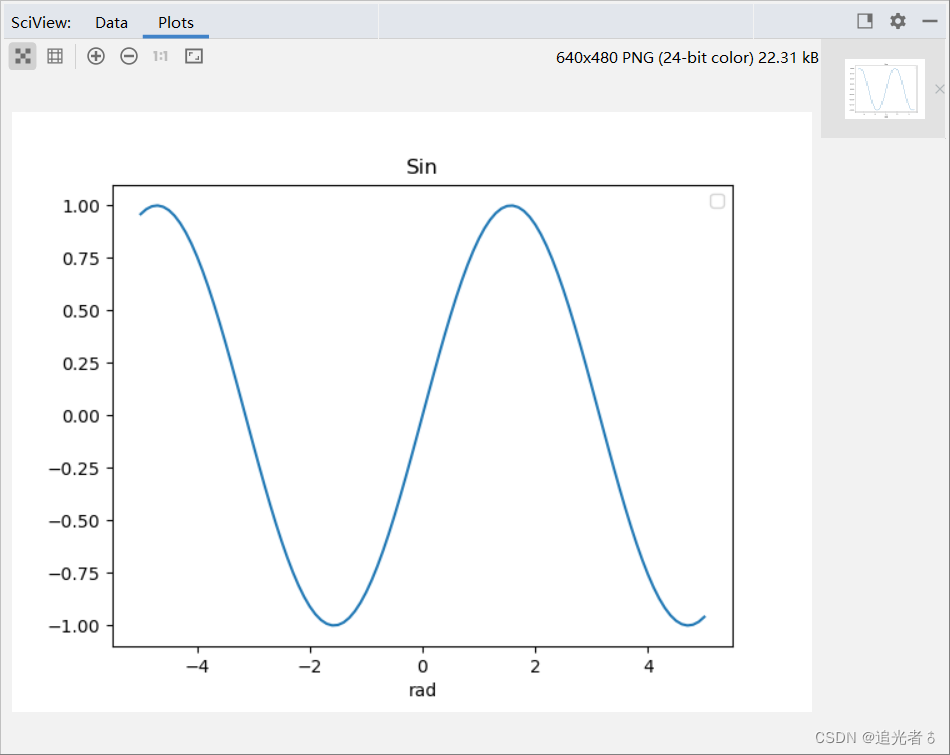
简单分析一下上述code:实际上,用于显示图形的主要代码只有 ax.plot(x1, y1) 这一行,虽然这种方法更受欢迎,不过如果要输出简单的图形,可以使用plt.plot(x1,y1)形式。
请注意,方法共有两种:
- [1] 形如 plt.plot() 的简单方法;
- [2] ax.plot() 的严密地面向对象声明的方法。
最后再运行 plt.show()即可。上面指出,如果在Jupyter Notebook中使用了魔法命令 %matplotlib inline,那么即使不写show也可以输出图形~
🍑4.3 绘制各种图形
🥝4.3.1 绘制 散点图
import numpy as np
import matplotlib.pyplot as plt# 绘制散点图
x2 = np.arange(100)
y2 = x2 * np.random.rand(100)plt.scatter(x2, y2)
plt.show()
可使用scatter()方法来绘制散点图,在PyCharm中运行后,效果如下:
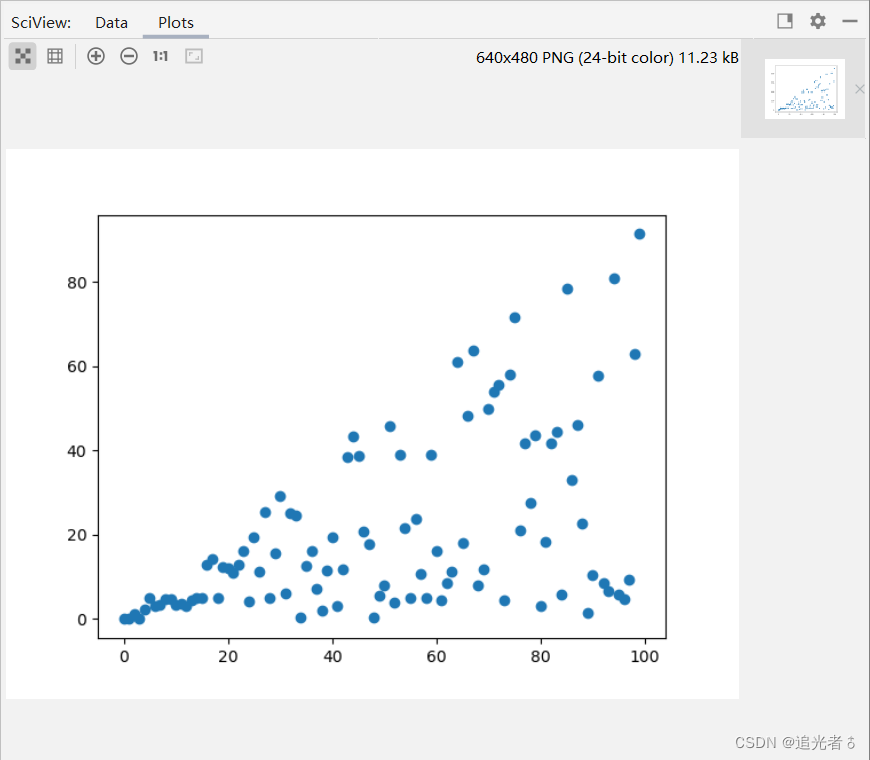
🥝4.3.2 绘制 直方图
import numpy as np
import matplotlib.pyplot as plt# 绘制 直方图
x2 = np.arange(100)
y2 = x2 * np.random.rand(100)
plt.hist(y2, bins=5)
plt.show()
可使用hist()方法绘制直方图。同理,得到的效果是:
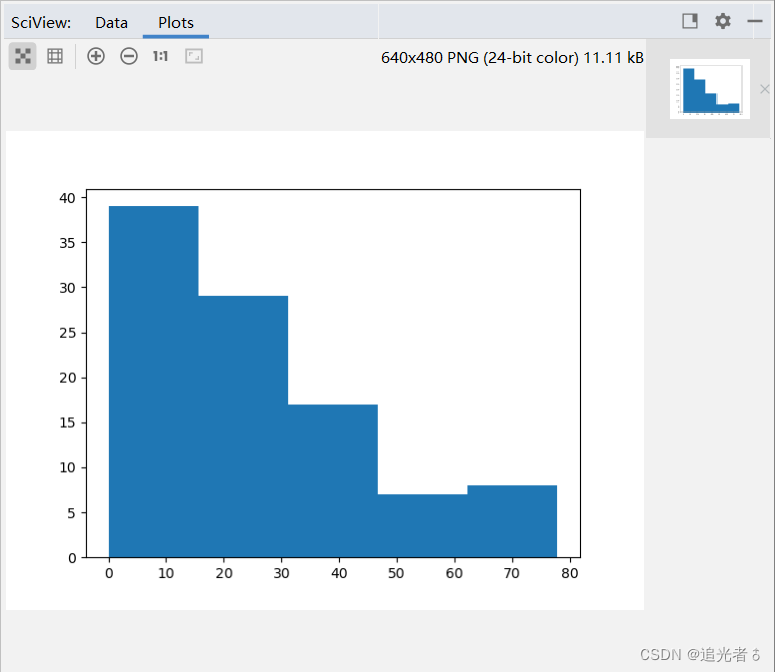
🥝4.3.3 绘制柱状图
import numpy as np
import matplotlib.pyplot as plt# 绘制柱状图
x2 = np.arange(100)
y2 = x2 * np.random.rand(100)
plt.bar(x2, y2)
plt.show()
可使用bar()方法来绘制柱状图:
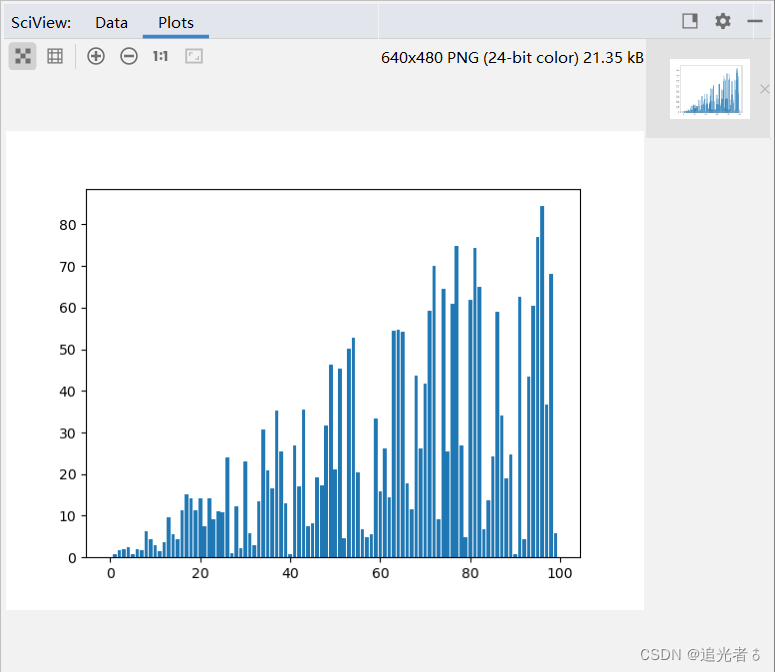
🥝4.3.4 绘制 折线图
import numpy as np
import matplotlib.pyplot as plt# 绘制折线图
x2 = np.arange(100)
y2 = x2 * np.random.rand(100)
plt.plot(x2, y2)
plt.show()
可使用plot()方法可绘制折线图。
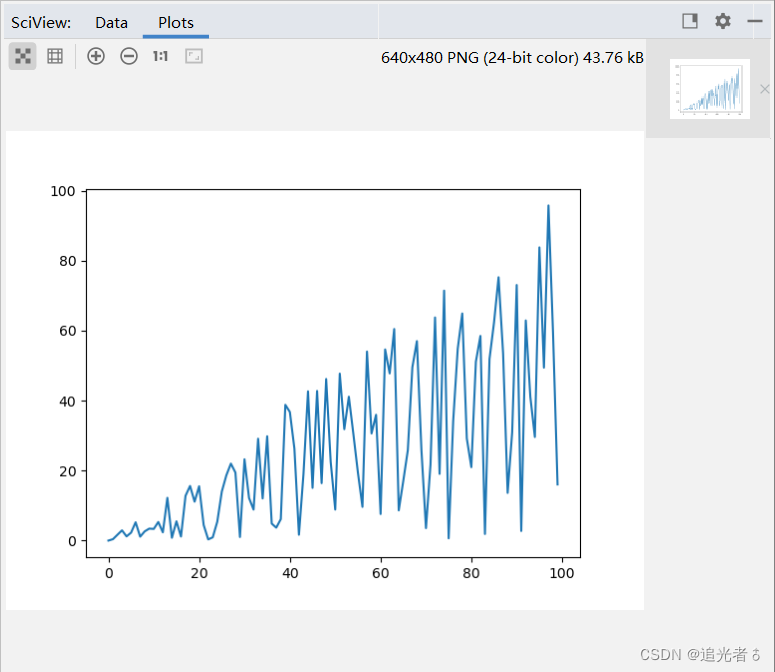
🥝4.3.5 绘制 箱形图
import numpy as np
import matplotlib.pyplot as plt# 绘制箱形图
x2 = np.arange(100)
y2 = x2 * np.random.rand(100)
plt.boxplot(y2)
plt.show()
还可使用boxplot()方法来绘制箱形图:(注:此前,未曾画过这种图)
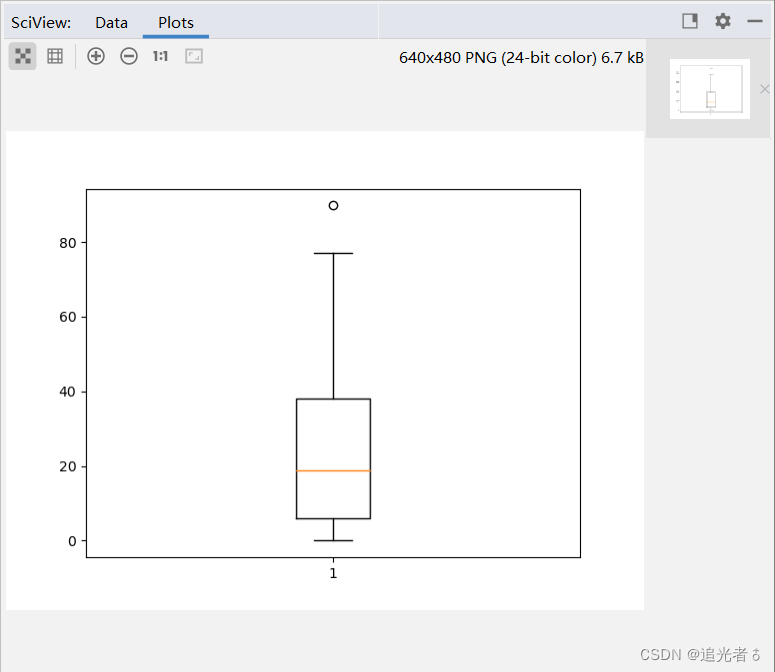
可以用箱形图输出y2的数据,如上图。箱形图是查看数据分布的优秀的可视化方法。
🍑4.4 对于该红酒数据集的处理(查看)
# 导入红酒数据集 2023.3.18 19:58
from sklearn.datasets import load_wine
import matplotlib.pyplot as plt
data = load_wine()# 数据划分
x3 = data.data[:, [0]]
y3 = data.data[:, [9]]# 绘制散点图
plt.scatter(x3, y3)
plt.show()
红酒数据集的散点图:
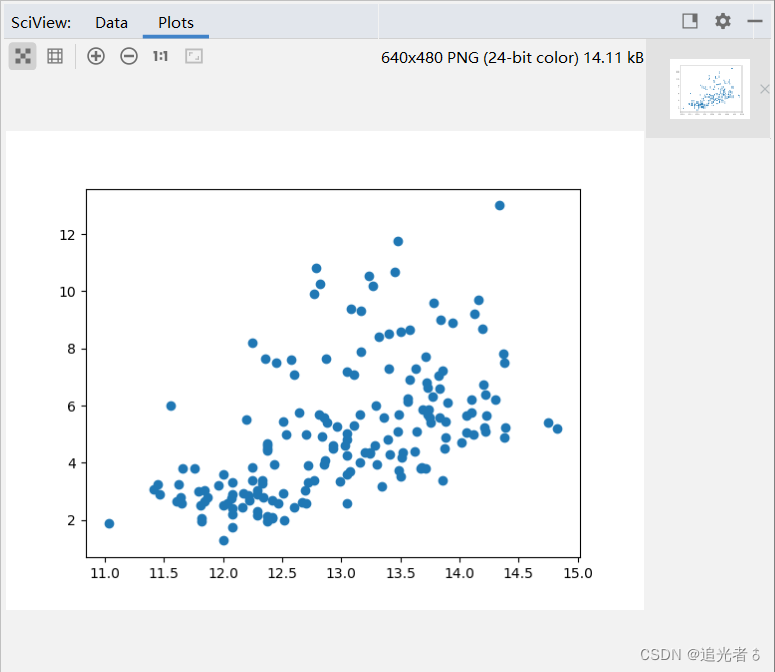
紧接上述code:
plt.hist(y3, bins=5)
plt.show()
y3的直方图:
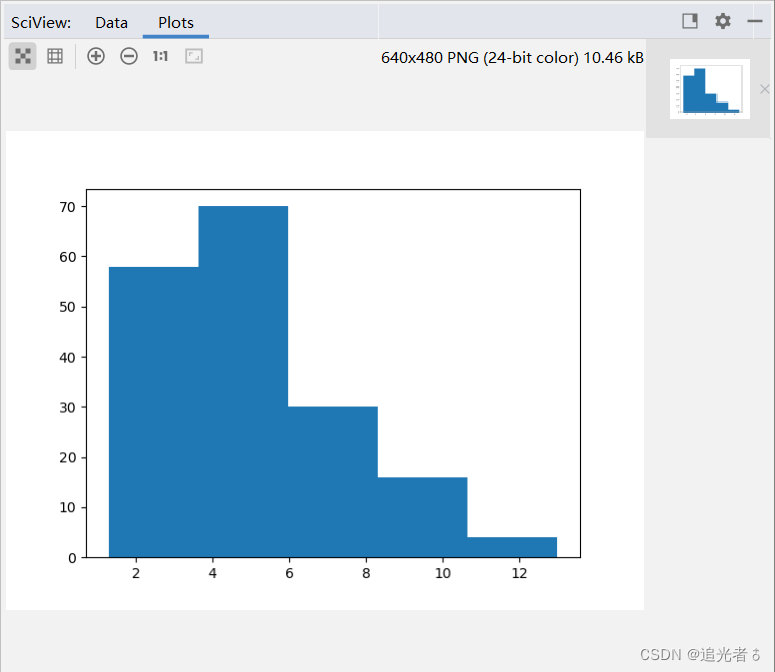
通过可视化查看与红酒数据集相关的两个图形,我们可以了解数据的特性。
由于篇幅所限:后续章节将会继续记录分析:
🍄五、使用pandas 理解和处理数据
可以期待一下!
也热烈欢迎大家提出自己的意见和建议!
🍒 热门专栏推荐:
- 🥇Python&AI专栏:【Python从入门到人工智能】
- 🥈前端专栏:【前端之梦~代码之美(H5+CSS3+JS.】
- 🥉论文阅读&项目专栏:【小小的项目 (实战+案例)】
- 🍎C语言/C++专栏:【C语言、C++基础代码~】
- 🌞问题解决专栏:【工具、技巧、解决办法】
- 📝 加入Community 一起追光:追光者♂社区
持续创作优质好文ing…✍✍✍
记得一键三连哦!!!
求关注!求点赞!求个收藏啦!
