深度學習之捲積神經網絡(CNN)之貓狗識別
目录
- 什麽是捲積神經網絡
- 結構
- 输入层
- 卷积层(convolutional layer)
- 作用:特征提取
- 一维卷积
- 二维卷积
- 卷积计算
- 填充(padding)
- 步幅(stride)
- 感受野
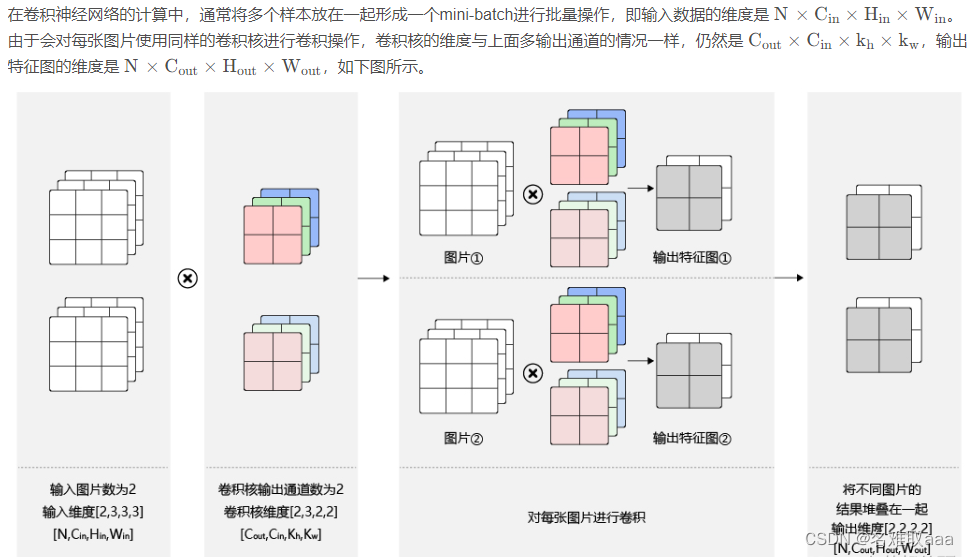
- 多输入通道场景
- 多输出通道场景
- 批量操作
- 例子
- 性质
- 局部连接
- 稀疏交互
- 权重共享
- 池化层(pooling layer)
- 作用:降维(大幅降低参数量级)
- 池化操作
- 激活函数
- 全连接层
- 作用:对提取的特征进行非线性组合以得到输出
- 實戰
- 數據采集
- 建立模型
- 總結
什麽是捲積神經網絡
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。
卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)”。
对卷积神经网络的研究始于二十世纪80至90年代,时间延迟网络和LeNet-5是最早出现的卷积神经网络 ;在二十一世纪后,随着深度学习理论的提出和数值计算设备的改进,卷积神经网络得到了快速发展,并被应用于计算机视觉、自然语言处理等领域。
卷积神经网络仿造生物的视知觉(visual perception)机制构建,可以进行监督学习和非监督学习,其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的计算量对格点化(grid-like topology)特征,例如像素和音频进行学习、有稳定的效果且对数据没有额外的特征工程(feature engineering)要求 。
定义:采用监督方式训练的一种面向两维形状不变性识别的特定多层感知机。
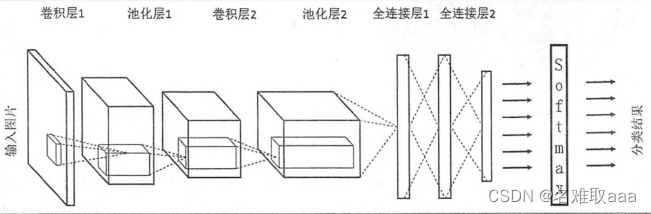
結構
输入层
卷积神经网络的输入层可以处理多维数据,常见地,一维卷积神经网络的输入层接收一维或二维数组,其中一维数组通常为时间或频谱采样;二维数组可能包含多个通道;二维卷积神经网络的输入层接收二维或三维数组;三维卷积神经网络的输入层接收四维数组 。由于卷积神经网络在计算机视觉领域应用较广,因此许多研究在介绍其结构时预先假设了三维输入数据,即平面上的二维像素点和RGB通道。
与其它神经网络算法类似,由于使用梯度下降算法进行学习,卷积神经网络的输入特征需要进行标准化处理。具体地,在将学习数据输入卷积神经网络前,需在通道或时间/频率维对输入数据进行归一化,若输入数据为像素,也可将分布于 的原始像素值归一化至区间 。输入特征的标准化有利于提升卷积神经网络的学习效率和表现
在处理图像的CNN中,输入层一般代表了一张图片的像素矩阵。可以用三维矩阵代表一张图片。三维矩阵的长和宽代表了图像的大小,而三维矩阵的深度代表了图像的色彩通道。比如黑白图片的深度为1,而在RGB色彩模式下,图像的深度为3。
卷积层(convolutional layer)
卷积神经网络的核心是卷积层,卷积层的核心部分是卷积操作。
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的卷积操作,也是卷积神经网络的名字来源。
作用:特征提取
卷积层内部包含多个卷积核,组成卷积核的每个元素都对应一个权重系数和一个偏差量。卷积核的所覆盖的区域,被称为“感受野(receptive field)”。
一维卷积

其中,wk被称为滤波器(filter)或卷积核(convolution kernel)。
二维卷积
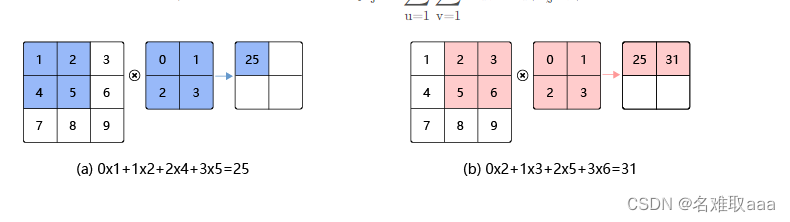
卷积计算


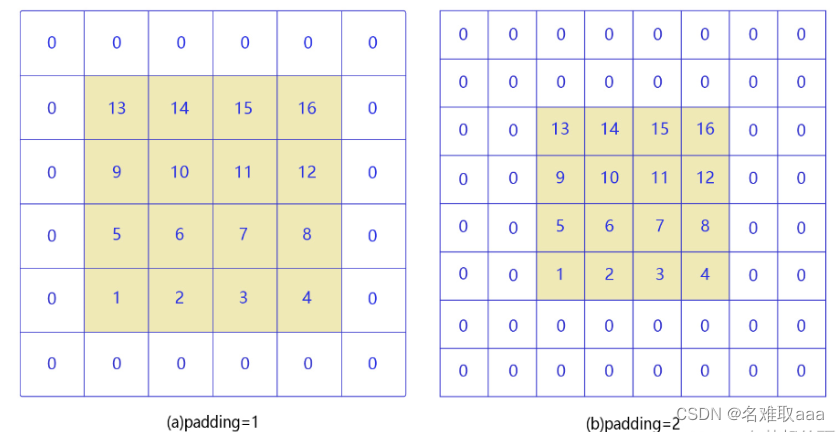
填充(padding)
当卷积核尺寸大于 1 时,输出特征图的尺寸会小于输入图片尺寸。如果经过多次卷积,输出图片尺寸会不断减小。为了避免卷积之后图片尺寸变小,通常会在图片的外围进行填充(padding),如下图所示。

步幅(stride)
步幅为卷积核每次滑动的像素点个数。下图是步幅为2的卷积过程,卷积核在图片上移动时,每次移动大小为2个像素点。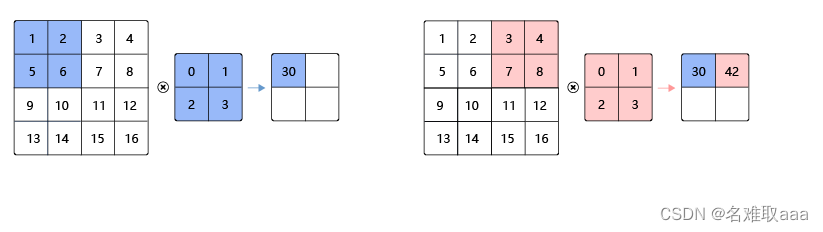

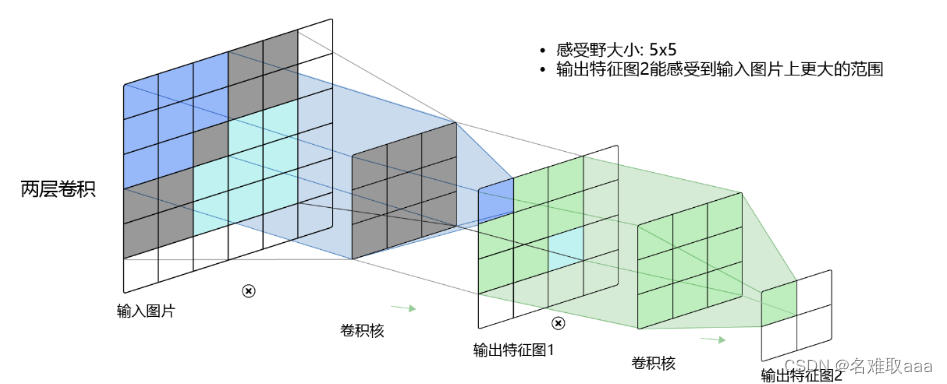
感受野
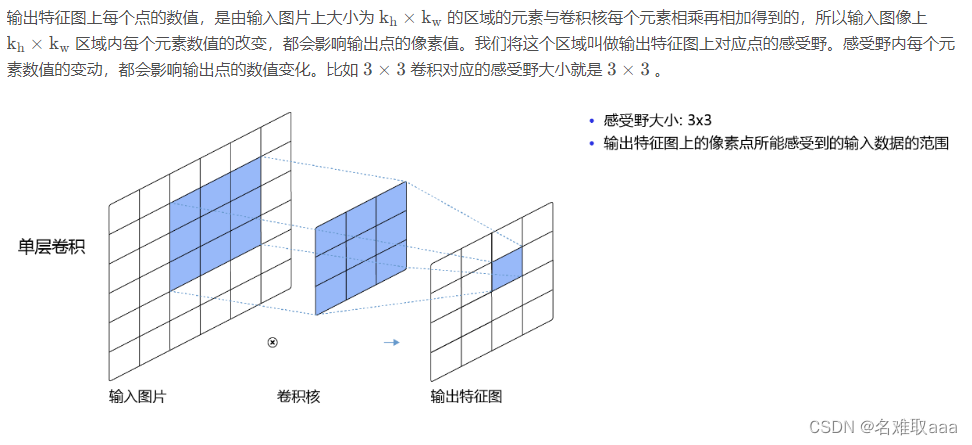
而当通过两层 3 × 3 的卷积之后,感受野的大小将会增加到 5 × 5 。当增加卷积网络深度的同时,感受野将会增大,输出特征图中的一个像素点将会包含更多的图像语义信息。
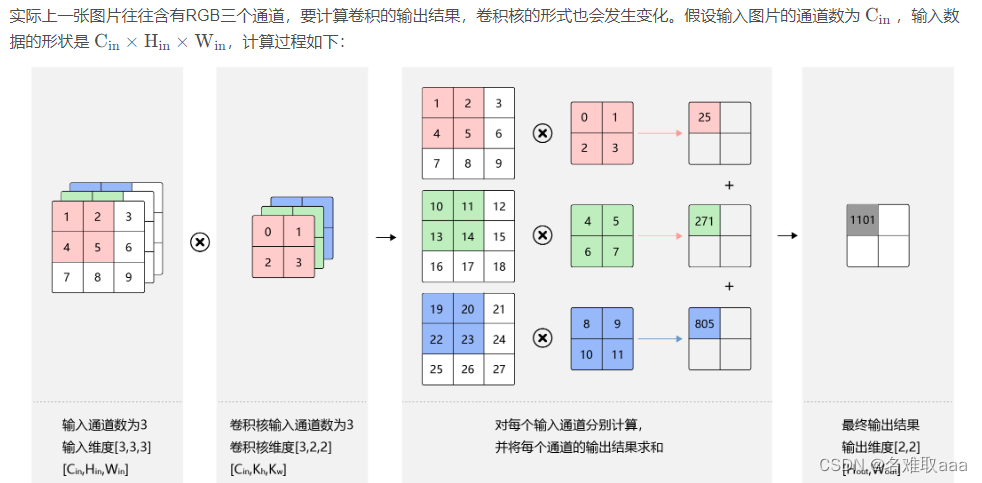
多输入通道场景

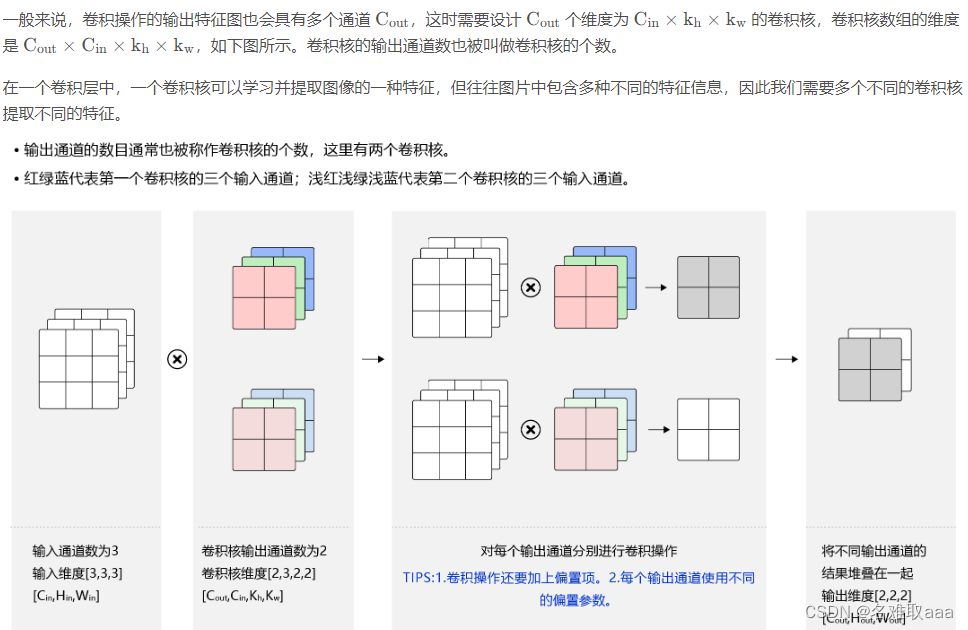
多输出通道场景
批量操作
例子
https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
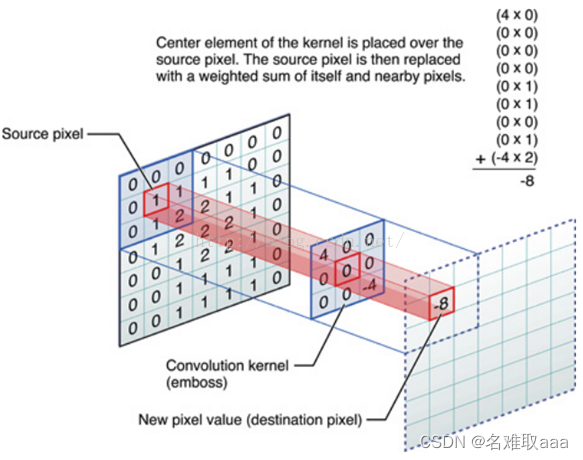
比如下图中,图中左边部分是原始输入数据,图中中间部分是滤波器filter,图中右边是输出的新的二维数据。中间滤波器filter与数据窗口做内积,其具体计算过程则是:40+00+00+00+01+01+00+01±4*2=-8
在CNN中,滤波器filter对局部输入数据进行卷积计算。每计算完一个数据窗口内的局部数据后,数据窗口不断平移滑动,直到计算完所有数据。这个过程中,有这么几个参数:
-
深度depth:神经元个数,决定输出的depth厚度。同时代表滤波器个数。
-
步长stride:决定滑动多少步可以到边缘。
-
填充值padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑到末尾位置,通俗地讲就是为了总长能被步长整除。
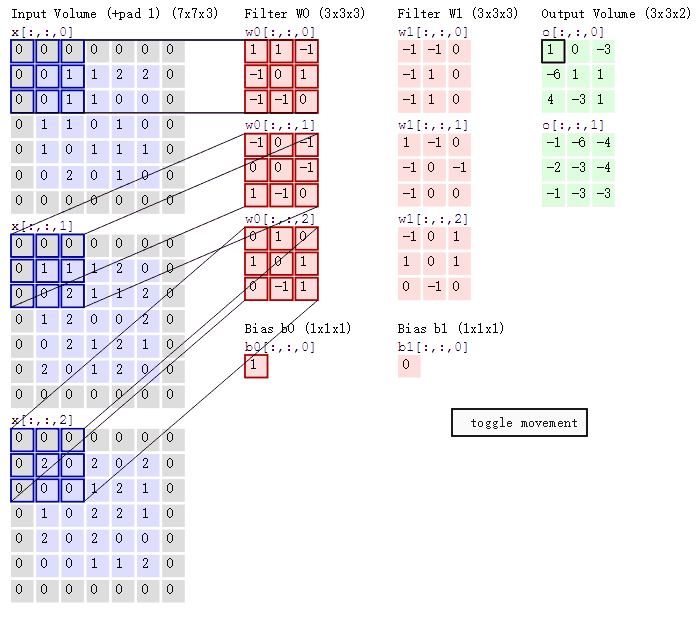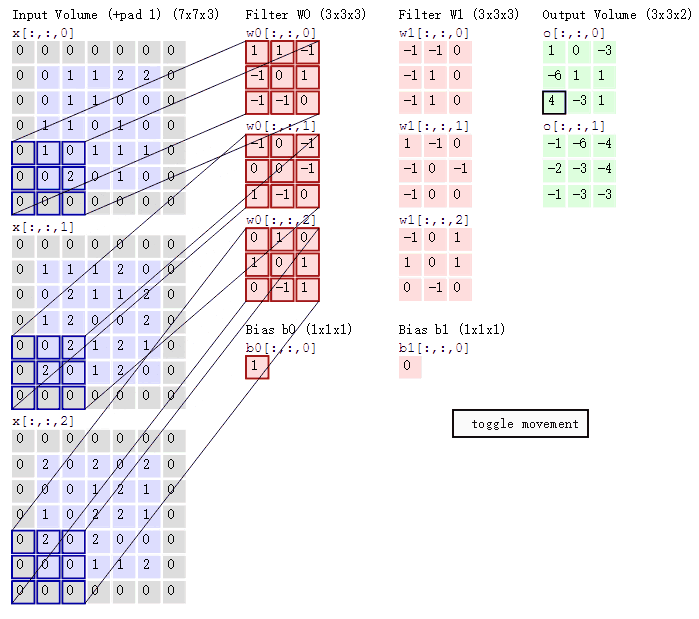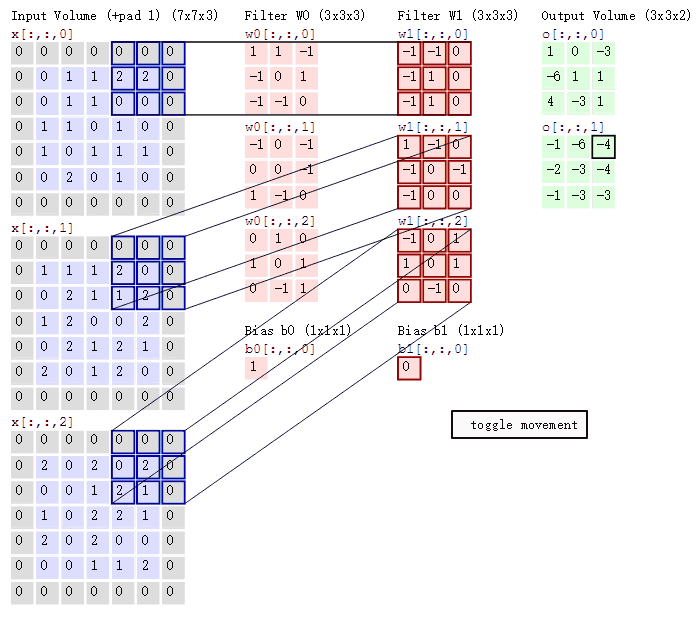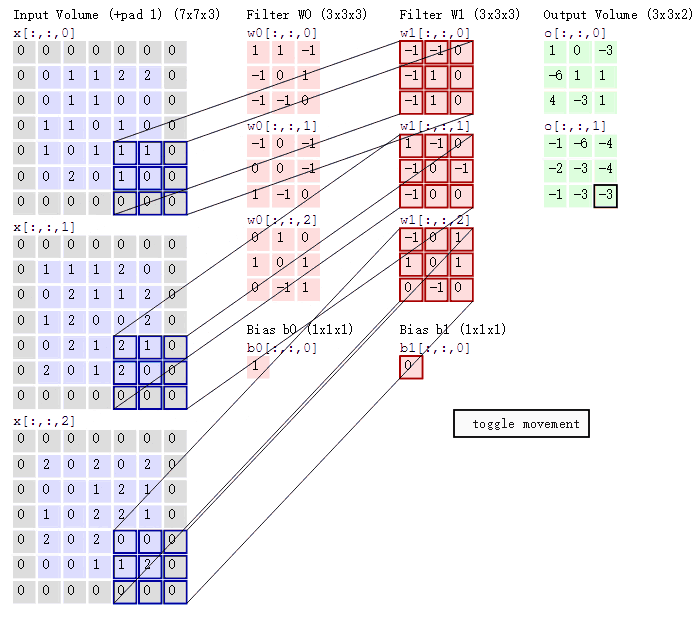
可以看到:
-
两个神经元,即depth=2,意味着有两个滤波器。
-
数据窗口每次移动两个步长取3*3的局部数据,即stride=2。
-
padding=1。(填充一圈,灰色部分)
然后分别以两个滤波器filter为轴滑动数组进行卷积计算,得到两组不同的结果。
左边是输入(773中,7*7代表图像的像素/长宽,3代表R、G、B三个颜色通道);中间部分是两个不同的滤波器Filter w0、Filter w1;最右边则是两个不同的输出。随着左边数据窗口的平移滑动,滤波器Filter w0/Filter w1对不同的局部数据进行卷积计算。
值得一提的是:左边数据在变化,每次滤波器都是针对某一局部的数据窗口进行卷积,这就是所谓的CNN中的局部感知机制。
由于图像的空间联系是局部的,每个神经元不需要对全部的图像做感受,只需要感受局部特征即可,然后在更高层将这些感受得到的不同的局部神经元综合起来就可以得到全局的信息
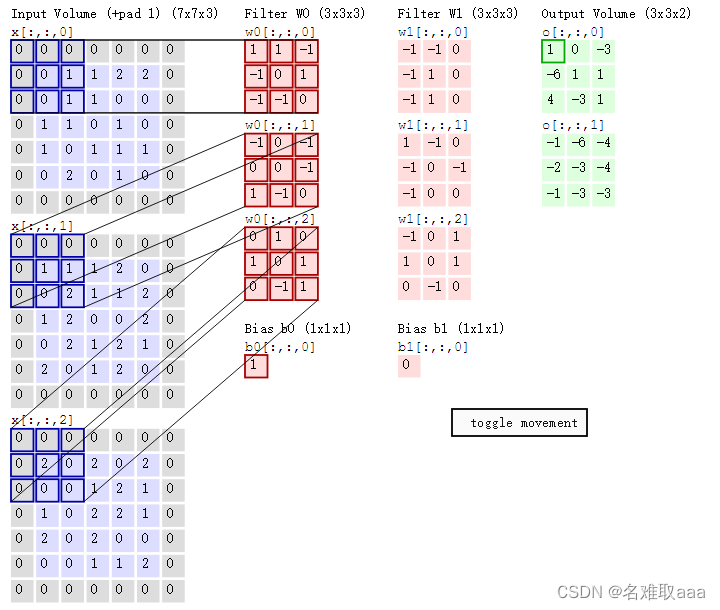
即上图中的输出结果1具体是怎么计算得到的呢?其实,类似wx+b,w对应滤波器Filter w0,x对应不同的数据窗口,b对应Bias b0,相当于滤波器Filter w0与一个个数据窗口相乘再求和后,最后加上Bias b0得到输出结果1,如下过程所示: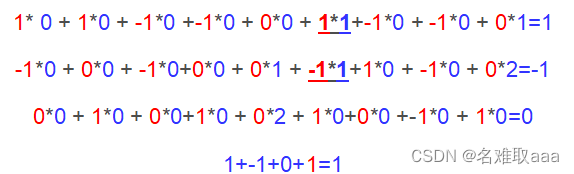
性质
在图像处理中 ,卷积经常作为特征提取的有效方法。卷积滤波器的参数需要学习。
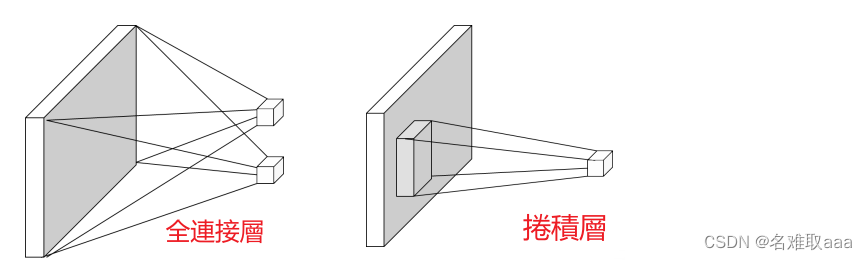
局部连接

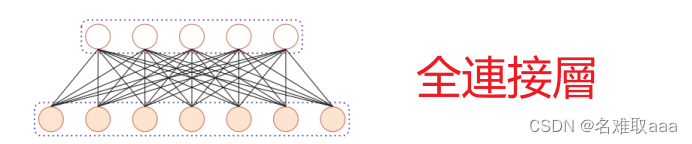

二维全连接层和卷积层:
稀疏交互
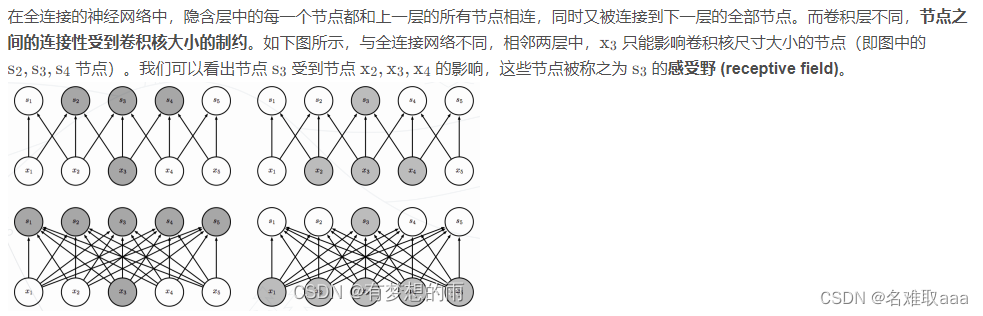
尽管一个节点在一个层级之间仅与其感受野内的节点相关联,但是对于深层中的节点,其与绝大部分输入之间却存在这间接交互,如下图所示。节点 g3 尽管直接的连接是稀疏的,但处于更深的层中可以间接的连接到全部或者大部分的输入节点。这就使得网络可以仅通过这种稀疏交互来高效的描述多个输入变量之间的复杂关系。
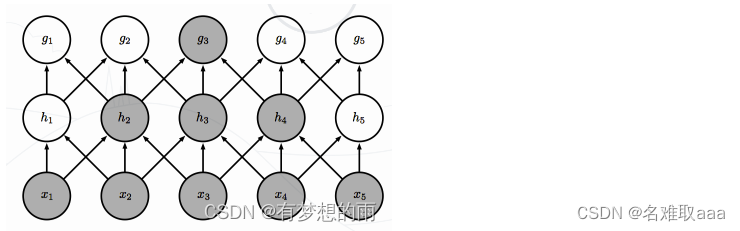
权重共享
作为参数的滤波器 w (l) 对于第 l 层的所有的神经元都是相同的。如上图卷积层中,只有一个滤波器完成特征图抽取。权重共享可以理解为一个滤波器只捕捉输入数据中的一种特定的局部特征。因此,如果要提取多种特征就需要使用多个不同的滤波器。
正是由于权重共享机制,使得卷积层具有 平移等变 (equivariance) 的性质。对于函数f(x) 和 g(x),如果满足f(g(x))=g(f(x)) ,就称 f(x) 对于变换 g 具有等变性。即对于图像如果我们将所有的像素点进行移动,则卷积后的输出表示也会移动同样的量。
池化层(pooling layer)
作用:降维(大幅降低参数量级)
特征选择和信息过滤
池化层,也称汇聚层、子采样层,其主用作用是进行特征选择,降低特征数量,从而减少参数数量。池化相当于在空间范围内做了维度约减,分别作用于每个输入的特征并减小其大小。
池化层包含预设定的池化函数,其功能是将特征图中单个点的结果替换为其相邻区域的特征图统计量。使用某一位置的相邻输出的总体统计特征代替网络在该位置的输出,其好处是当输入数据做出少量平移时,经过池化函数后的大多数输出还能保持不变。
池化操作
池化操作将输入矩阵某一位置相邻区域的总体统计特征作为该位置的输出,主要有平均池化(Average Pooling)、最大池化(Max Pooling) 等。简单来说池化就是在该区域上指定一个值来代表整个区域。池化层的超参数:池化窗口和池化步长。池化操作也可以看做是一种卷积操作。
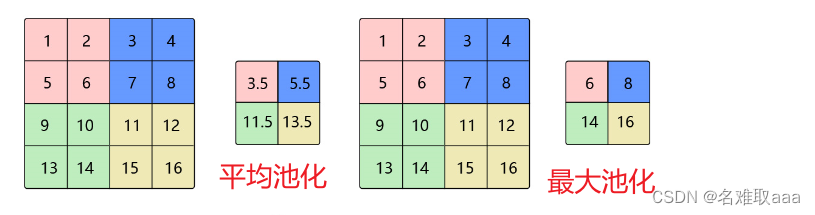

通常使用 2 × 2 大小的池化窗口,步幅也使用 2,填充为0;通过这种方式的池化,输出特征图的高和宽都减半,但通道数不会改变。
激活函数
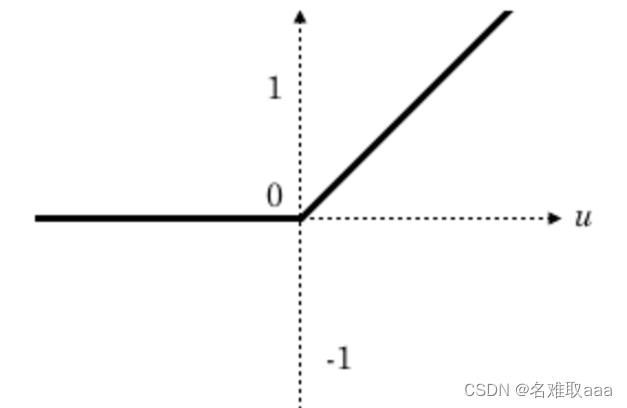
激活函数(非线性激活函数,如果激活函数使用线性函数的话,那么它的输出还是一个线性函数。)但使用非线性激活函数可以得到非线性的输出值。常见的激活函数有Sigmoid、tanh和Relu等。一般我们使用Relu作为卷积神经网络的激活函数。Relu激活函数提供了一种非常简单的非线性变换方法,函数图像如下所示
全连接层
在经过多轮卷积层和池化层的处理之后,在CNN的最后一般会由1到2个全连接层来给出最后的分类结果。经过几轮卷积层和池化层的处理之后,可以认为图像中的信息已经被抽象成了信息含量更高的特征。我们可以将卷积层和池化层看成自动图像特征提取的过程。在提取完成之后,仍然需要使用全连接层来完成分类任务
作用:对提取的特征进行非线性组合以得到输出
全连接层本身不具有特征提取能力,而是使得目标特征图失去空间拓扑结构,被展开为向量。
實戰
基於dataset\training_set數據,根據提供的結構建立CNN模型,識別圖片中的貓/狗,計算預測準確率:
- 識別圖片中的貓/狗、計算dataset\training_set測試數據預測準確率
- 從網站下載貓/狗,對其進行預測
數據采集
因爲沒找到數據集所以就自己采集百度的貓狗圖片了,以下提供參考
# -*- coding:utf-8 -*-
# @Time : 2023/2/26 15:30
# @Author: fbz
# @File : baidu_image.py
import random
import timeimport requestsdef downloadImg(word, i):global numurl = 'https://image.baidu.com/search/acjson'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',}params = {'tn': 'resultjson_com','word': word,'pn': 30 * i,'1677397526392': '','logid': '','ipn': '','fp': '','ct': ''}res = requests.get(url, headers=headers, params=params).json()data = res.get('data')for i in range(30):thumbURL = data[i].get('thumbURL')image = requests.get(thumbURL, headers=headers).contentwith open("img/dog/dog.{num}.jpg".format(num=num), mode="wb") as f:f.write(image) # 图片内容写入文件num += 1print('dog.{num}.jpg 下載完成'.format(num=num))if __name__ == '__main__':num = 1word = '狗'for i in range(30):downloadImg(word=word, i=i)time.sleep(random.randint(2, 4))建立模型
# load the data
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255,
# rotation_range=15, # 旋转范围
# shear_range=0.2, # 剪切强度
# zoom_range=0.2, # 缩放范围
# width_shift_range=0.2, # 水平平移范围
# height_shift_range=0.2, # 垂直平移范围
# horizontal_flip=True, # 水平反转
# vertical_flip=True # 垂直翻转)training_set = train_datagen.flow_from_directory('./dataset/training_set',target_size=(50,50), # 所有的图像将被调整到的統一尺寸batch_size=32, # 一次拿幾張圖片
# save_to_dir='./dataset/save_data', # 指定正在生成的增强图片要保存的目录(用于可视化你在做什么)
# save_prefix='trans_', # 保存图片的文件名前缀
# save_format='jpeg', # "png", "jpeg" 之一。默认:"png"。class_mode='binary')
這裏有兩個類別,就是兩個文件夾

# set up the cnn model
from keras.models import Sequential
from keras.layers import Conv2D,MaxPool2D,Flatten,Densemodel = Sequential()
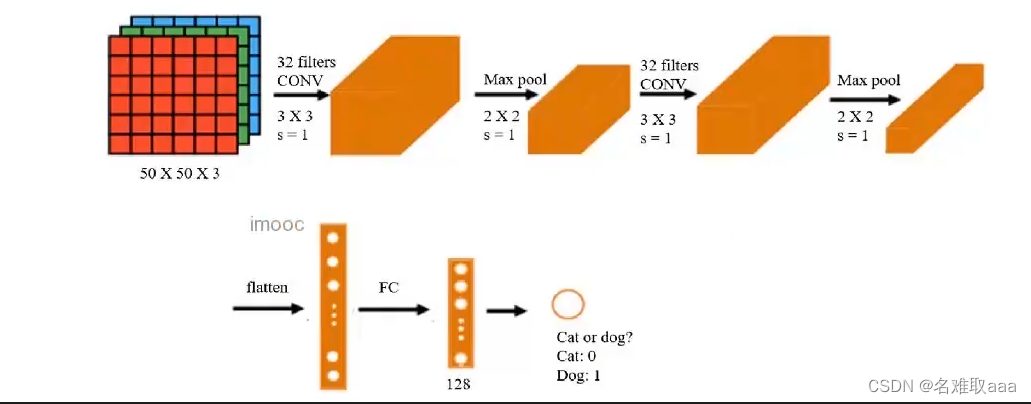
# 捲積層
model.add(Conv2D(32,(3,3),input_shape=(50,50,3),activation='relu'))
# 池化層
model.add(MaxPool2D(pool_size=(2,2)))
# 捲積層
model.add(Conv2D(32,(3,3),activation='relu'))
# 池化層
model.add(MaxPool2D(pool_size=(2,2)))
# flattening layer
model.add(Flatten())
# FC layer
model.add(Dense(units=128,activation='relu'))
model.add(Dense(units=1,activation='sigmoid'))
# configure the model
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])
metrics=[‘accuracy’] 輸出準確率
model.summary()
看一下模型結構
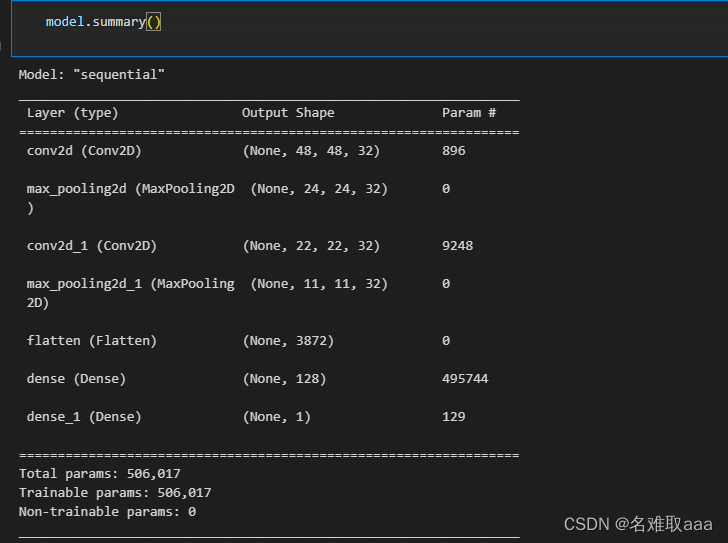
可以明顯看出有哪些層以及每一層的維度和訓練參數
# train the model
model.fit_generator(training_set,epochs=25)
迭代25次試試看
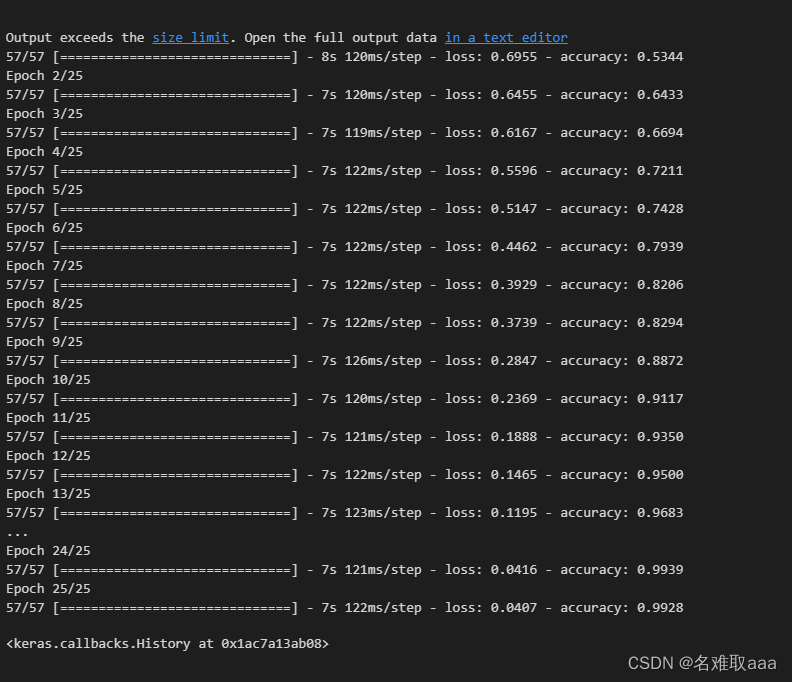
可以看出損失函數越來越小而準確率越來越高
# accuracy on the training data
accuracy_train = model.evaluate_generator(training_set)
print(accuracy_train)
還可以

# accuracy on the test data
test_set = train_datagen.flow_from_directory('./dataset/test_set',target_size=(50,50),batch_size=32,class_mode='binary')accuracy_test = model.evaluate_generator(test_set)
print(accuracy_test)
看一下測試集

# load single image
from keras.utils.image_utils import load_img,img_to_array
pic_cat = './dataset/test_set/cat/cat.273.jpg'
pic_cat = load_img(pic_cat,target_size=(50,50))
pic_cat= img_to_array(pic_cat)
pic_cat = pic_cat/255
pic_cat = pic_cat.reshape(1,50,50,3)
import numpy as np
result = np.around(model.predict(pic_cat))
print(result)
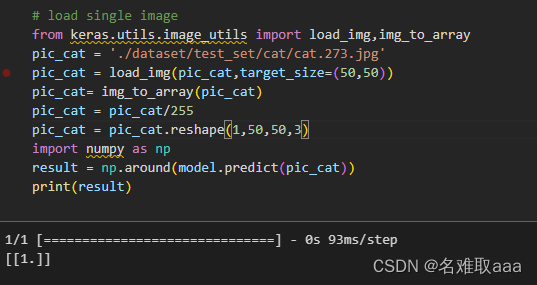
沒預測對啊
# load single image
from keras.utils.image_utils import load_img,img_to_array
pic_dog = './dataset/test_set/dog/dog.398.jpg'
pic_dog = load_img(pic_dog,target_size=(50,50))
pic_dog= img_to_array(pic_dog)
pic_dog = pic_dog/255
pic_dog = pic_dog.reshape(1,50,50,3)
import numpy as np
result = np.around(model.predict(pic_dog))
print(result)
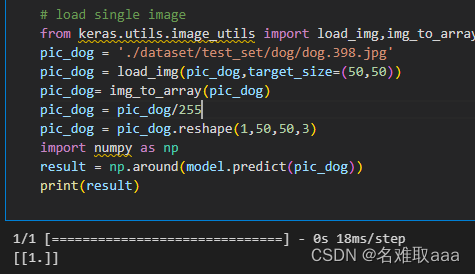
這個倒是對了
training_set.class_indices
看屬於哪個類別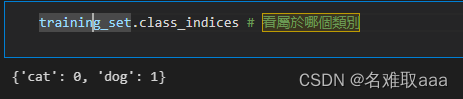
# make prediction on multiple images
# 多張圖片的預測
import matplotlib as mlp
font2 = {'family': 'SimHei','weiight': 'normal','size': 20
}
mlp.rcParams['font.family'] = 'SimHei'
mlp.rcParams['axes.unicode_minus'] = False
from matplotlib import pyplot as plt
from matplotlib.image import imread
from keras.utils.image_utils import load_img, img_to_array
from keras.models import load_modelfig = plt.figure(figsize=(10,10))
a = [i for i in range(1,10)]
for i in a:img_name = './dataset/test_set/cat/cat.{i}.jpg'.format(i=i)img_ori = load_img(img_name,target_size=(50,50))img = img_to_array(img_ori)img = img.astype('float32') / 255img = img.reshape(1,50,50,3)result = np.around(model.predict(img))img_ori = load_img(img_name,target_size=(250, 250))plt.subplot(3,3,i)plt.imshow(img_ori)plt.title('預測為: 狗狗' if result[0][0] == 1 else '預測為: 貓咪')
plt.show()
多張一起看看

效果感覺還好吧
總結
CNN實現貓狗識別實戰summary:
- 通過搭建CNN模型,實現了對複雜圖像的自動識別分類
- 掌握了圖像數據的批量加載與圖像增强方法
- 更熟練的掌握了keras的sequence結構,並嵌入捲積層、池化層
- 實現了對網絡圖片的分類識別
- 圖像預處理參考資料:
- https://keras.io/api/preprocessing/image/
- https://keras.io/zh/preprocessing/image/
這就是本次學習深度學習之捲積神經網絡(CNN)的筆記
附上本次實戰的數據集和源碼:
鏈接:https://github.com/fbozhang/python/tree/master/jupyter