【bloom】轻松玩转开源大语言模型bloom(三)
前言
从本篇开始本系列的标题前将加上【bloom】的tag,好像可以增加展现量,不喜勿喷。另外文章将采取小短文的篇幅,写的太长也没人看。
那么书接正题,上期介绍了greed search和beam search,其实beam search的缺点在上文中没有提到,那就是缺乏随机性,看起来过于合理,不像人写出来的东西,所以本期将介绍sampling采样技术和与之相关的temperature温度值设定来合理的增加生成文字的随机性。
随机采样
字面意思很简单,就是在选取字词的时候随机选取,如下图所示:
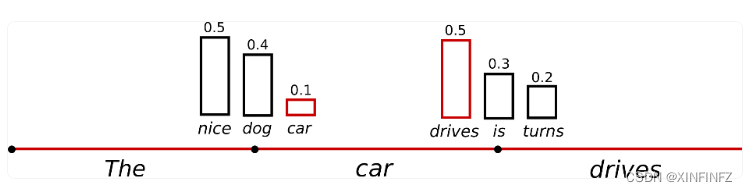
按贪心搜索的方法肯定会选取可能性最高的nice和drives,但是添加了sampling之后就可能会选择可能性只有0.1的car,下面我们来看代码:
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
import time
a1 = time.time()
checkpoint = "bigscience/bloom-1b1"tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
inputs = tokenizer.encode("我和我的猫都很想你", return_tensors="pt") #prompt
outputs = model.generate(inputs,min_length=150,
do_sample=True,max_length=200,temperature=1.0)
print(tokenizer.decode(outputs[0])) #使用tokenizer对生成结果进行解码
a2 = time.time()
print(f'time cost is {a2 - a1} s')
主要还是在model.generate这里进行参数上的改变,添加了do_sample=True保证每次生成随机,temperature=1.0是默认值,这里故意写出来方便之后理解,这种情况下是没有对随机的概率分布进行处理的。
生成结果如下:
我和我的猫都很想你,你却不在,我知道你也在等我,我有些伤感,
但还是要相信一切都会好起来的,一切,包括我和你猫。
图片发自简书app 我们这群猫,虽然现在都离不开我们,但还是有很多地方,比如我的家、我们家后院、我的小狗、我家的猫咪,
还有小狗、小猫...还有很多呢,他们只是需要我...
图片发自简书app 图片发自简书app 图片发自简书app 图片发自简书app 图片发自简书app 图片发自简书app 图 片发自简书app 图片发自简书app 你说,我还能做什么?
time cost is 29.499494075775146 s
可以看到除了后面重复的文字之外,前面生成的文字多半有点杂乱,这就是没设定温度值的问题所在。
温度设定
先来看这么个东西,这玩意叫softmax,或者更直观一点叫soft arg max,简单的说是用于把一串实数值转化为总和为1的概率分布。我们的词向量的概率分布,就是很多词组成,加起来概率等于1的分布,比如上文图中的{nice,dog,car}对应的概率是{0.5,0.4,0.1}。而设定温度值,其实本质上就是在设定softmax分布的β值。
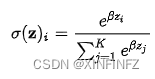
在最极端的情况下,soft arg max 就会趋于argmax,即{0,0,0,0,…1,0},一串one-hot向量,只有一个特征是1,其他全是0,那这是什么情况下呢?即β趋于无穷大,而温度值T等于1/β,趋向于0,此时只有一个词的概率接近于0.99999999999,其他词的概率都会接近于0,此时的概率分布就变成了贪心搜索,即就算是随机选取也没法选中其他词了,只会选中概率最大的那个词。
示例代码如下:
outputs = model.generate(inputs,min_length=150,do_sample=True,
max_length=200,temperature=0.001)
此时我们将temperature设定的非常小,生成的结果如下:
我和我的猫都很想你。 猫咪:你什么时候回来?
狗狗:明天。 猫咪:明天? 狗狗:明天。
猫咪:明天? 狗狗:明天。 猫咪:明天?
狗狗:明天。 猫咪:明天? 狗狗:明天。
猫咪:明天? 狗狗:明天。 猫咪:明天?
狗狗:明天。 猫咪:明天? 狗狗:明天。 猫咪:明天? 狗狗:明天。 猫咪:明天? 狗狗:明天。 猫咪:明天? 狗狗:明天。 猫咪:明天? 狗狗:明天。 猫咪:明天? 狗狗:明天。 猫咪:明 天? 狗狗:明天。 猫咪:明天? 狗狗:明天。 猫咪:明天? 狗狗:明天。 猫咪:明天? 狗狗:明天。 猫咪:
time cost is 35.493085861206055 s
发现结果和上节我们设定的贪心搜索是一模一样。
那么如果我把temperature设定的非常大呢?
outputs = model.generate(inputs,min_length=150,do_sample=True,
max_length=200,temperature=100)
T=100,此时β接近于0,概率分布接近于{1/n,1/n,1/n…1/n},所有词都含有相同被选中的概率,生成的文字结果如下:
我和我的猫都很想你:猫小狗喐呔猫 小白兔子,
还有"毛孩儿的猫阿玛 祝你过日子平实和暖昧、开一家宠物食品商店。 这几件都是送 给老爸们的.我买的礼物",
是希望他们一直走在那里开这猫饭窝里的饭呢... 春节刚贴的对家长的条子里:"孩子们对父亲节的怀念和对母亲节日感激,有家人们对父母的敬戴祝福以及对爱的肯定"这是对他们说的了......
我的爱爸爸- 我从小没有受过父亲的教育,
但我 爱在春节与家人有快乐一起回家参加他们的生活了 "对父母有最好的爱的时候是第一次见外"是对家人父母说:爱自己才是最完美的呢 对外孙 女儿 奶奶奶奶,说有朋友请,大家见面,就象吃晚饭时我们用膳的""老"! 我是一个不会唱歌不认爹我总想妈妈,每次吃
time cost is 35.58598041534424 s
可以看到随机生成的结果完全一坨乱七八糟的垃圾,没有什么规律,都是平等的随机选取。
最后放一个设定temperature=0.7的结果:
我和我的猫都很想你,因为你是我的偶像。
在人生路上,我们都在跌跌撞撞,我们都在摸爬滚打,但我们最终都选择了安稳,选择了安逸,选择了安逸。
因为你的存在,让我们 的生活变得安稳,让我们的生活变得温暖。
我知道,你现在过得很好,你一切都很好,我一定会好好照顾你的,所以,我会一直爱你 ,保护你,保护你。
文字起码能看有逻辑一点了。所以随机采样一定要合理的设定温度值。那什么是合理的温度值呢?就像下图所示:
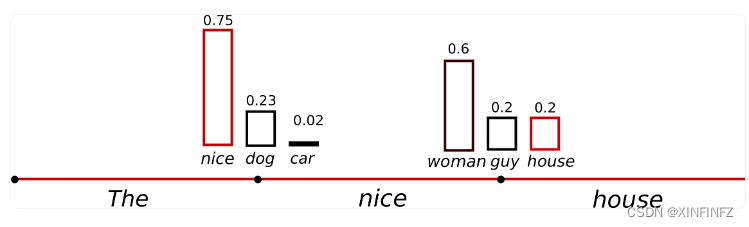
可以看到整个分布变得更陡峭了,car的概率从0.1变为了0.02,更难被选中,合理的温度值就是在保留随机性的同时让概率比较高应该被选取的词汇能够被选中,保留一定的逻辑。
上一篇:多线程案例——阻塞队列
下一篇:【erlang】语法篇