Python自学入门(七):Pandas之文件操作
迪丽瓦拉
2025-05-28 07:24:15
0次
Python自学入门(一):环境安装
Python自学入门(二):数据类型和运算符
Python自学入门(三):数据类型详解
Python自学入门(四):流程控制
Python自学入门(五):函数和模块
Python自学入门(六):Pandas之数据结构
5.2 文件操作
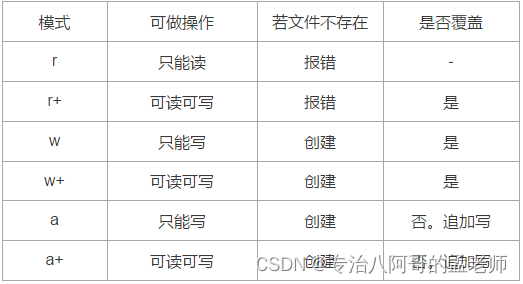
5.2.1 文本文件
读取文件
f = open("D:/temp/test.txt", encoding='utf-8') # 返回一个文件对象
line = f.readline() # 调用文件的 readline()方法
while line:print(line) line = f.readline()
f.close() #关闭
f = open("D:/temp/test.txt", encoding='utf-8') # 返回一个文件对象
line = f.readlines() #读取所有
print(line)
f.close() #关闭
写入文件
#会清空文件中原来的内容,文件不存在会创建文件
f = open("D:/temp/test2.txt","w",encoding="utf-8")
f.write("我爱Python\n")
f.close()
#追加内容
f = open("D:/temp/test2.txt","a",encoding="utf-8")
f.write("我爱Python\n")
f.close()
5.2.2 CSV文件
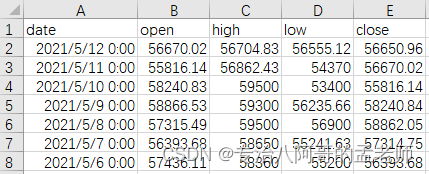
CSV文件(Comma-Separated Values),CSV文件是以纯文本形式存储的数据,列之间用逗号分隔。
date,open,high,low,close
2021/5/12,56670.02,56704.83,56555.12,56650.96
2021/5/11,55816.14,56862.43,54370,56670.02
2021/5/10,58240.83,59500,53400,55816.14
2021/5/9,58866.53,59300,56235.66,58240.84
2021/5/8,57315.49,59500,56900,58862.05
2021/5/7,56393.68,58650,55241.63,57314.75
2021/5/6,57436.11,58360,55200,56393.68
CSV文件可以用Excel打开
读取CSV,读取到的结果是一个DataFrame
df = pandas.read_csv('csv-data.csv')
print(df.shape)
print(df.head())
写入CSV
subjects=['Java','Python','HTML5']
teachers=['张','李','Rose']
dic={"subject":subjects,"teacher":teachers}
df=pandas.DataFrame(dic)
df.to_csv('data.csv')
5.2.3 Excel文件
需要安装openpyxl模块,
pip install openpyxl
读取Excel
df = pandas.read_excel('excel-data.xlsx')
print(df.shape)
print(df.head())
写入Excel
subjects=['Java','Python','HTML5']
teachers=['张','李','Rose']
dic={"subject":subjects,"teacher":teachers}
df=pandas.DataFrame(dic)
df.to_excel('data.xlsx')
5.2.4 XML文件
读取XML
from xml.dom.minidom import parsedomTree = parse("xml-data.xml")
# 文档根元素
rootNode = domTree.documentElement
print(rootNode.nodeName)# 所有顾客
docs = rootNode.getElementsByTagName("doc")
data=[]
for doc in docs:url= doc.getElementsByTagName("url")[0].childNodes[0].datadocno= doc.getElementsByTagName("docno")[0].childNodes[0].datatitle= doc.getElementsByTagName("contenttitle")[0].childNodes[0].datacontent= doc.getElementsByTagName("content")[0].childNodes[0].datadata.append([url,docno,title,content])
df=pandas.DataFrame(data,columns=['url','docno','title','content'])
写入XML
subjects=['Java','Python','HTML5']
teachers=['张','李','Rose']
dic={"subject":subjects,"teacher":teachers}
df=pandas.DataFrame(dic)
with open('data.xml', 'w',encoding='utf-8') as xmlfile:# 写头部xmlfile.write('\n') xmlfile.write('\n') # 名称可以根据实际需要修改for i in df.index: # 写数据xmlfile.write('\n')xmlfile.write('')xmlfile.write(df.iloc[i]['subject'])xmlfile.write(' \n')xmlfile.write('')xmlfile.write(df.iloc[i]['teacher'])xmlfile.write(' \n')xmlfile.write('\n') xmlfile.write(' ') # 名称可以根据实际需要修改
5.2.5 JSON文件
读取json
df = pandas.read_json('json-data.json')
写入json
subjects=['Java','Python','HTML5']
teachers=['张','李','Rose']
dic={"subject":subjects,"teacher":teachers}
df=pandas.DataFrame(dic)
df.to_json('data.json',orient='records',force_ascii=False)
相关内容
热门资讯
Linux-scheduler...
四、调度域 SDTL结构 linux内核使用SDTL结构体来组织CPU的层次关系 struct sc...
leetcode - 2379...
Description You are given a 0-indexed string block...
Retinanet网络与foc...
参考代码:https://github.com/yhenon/pytorch-reti...