目标检测常用Optimizer及LearningRate的代码实现
迪丽瓦拉
2024-06-02 01:47:34
0次
文章目录
- 前言
- 1、基础知识
- 2、RetinaNet
- 2.1.优化器简介
- 2.2.Demo及学习率可视化
- 总结
- 参考
前言
在本人阅读目标检测相关论文时,一直对论文中所介绍的优化器及学习率比较困惑,尤其在复写论文代码时,很可能会因参数对不齐而导致最终的复现结果大相径庭。因此,本文旨在记录相关论文在MMDetection中所使用的优化器及其code实现。(本文不定时更新…)
1、基础知识
常用的优化器有SGD, ADAM和ADAMW;而学习率调整器就比较多了,余弦退火,OneCycle还有多阶段衰减啥的。
2、RetinaNet
2.1.优化器简介
在mmdetection中retinanet的优化器包含两部分:优化器:sgd;学习率调整器包含warmup(热身500个iterationo),并在第9轮和第12轮时学习率以指数的形式衰减0.1倍。
#在训练开始的前num_warmup_iters次迭代里,采取warmup操作
num_warmup_iters=500
#采用constant的warmup操作
warmup_factor=0.001
#lr衰减率
lr_decay_factor=0.1
#lr衰减的时间点
lr_decay_time=[9, 12]
#训练的最大epoch数量
max_epochs=12
#基础学习率
base_lr=0.01
#基础weight_decay率
weight_decay=0.0001
#优化器的动量
momentum=0.9
2.2.Demo及学习率可视化
代码如下(示例):
import torch
import torch.nn as nn
import numpy as np
import config as cfg # config文件就是2.1节中的内容,新建一个config.py即可
import matplotlib.pyplot as plt# net
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.layer1 = nn.Linear(10, 2)self.layer2 = nn.Linear(2, 10)def forward(self, input):return self.layer2(self.layer1(input))
# dataloader
dataloader = [i for i in range(1000)]# optimizer
def build_net_optim():net = Net()params = net.parameters()optimizer = torch.optim.SGD(params, lr=cfg.base_lr,momentum=cfg.momentum,weight_decay=cfg.weight_decay)return net, optimizer# --- lr and optim function --- #
def lr_decay(optim, epoch, base_lr):lr_decay_time=np.array(cfg.lr_decay_time,dtype=np.int_) # [9, 12]index = np.nonzero(lr_decay_time<= (epoch+1))[0] # 非0元素下标if(index.size==0):optim.param_groups[0]['lr'] = base_lrreturn optimnum=index[-1].item()+1optim.param_groups[0]['lr'] = base_lr * (cfg.lr_decay_factor ** num)return optimdef warmup_lr(optim, cur_iter):if cur_iter >= cfg.num_warmup_iters:optim.param_groups[0]['lr'] = cfg.base_lrreturn optimupdate_lr = (1 - (1 - cur_iter / cfg.num_warmup_iters) * (1 - cfg.warmup_factor)) * cfg.base_lroptim.param_groups[0]['lr'] = update_lrreturn optimdef main():all_lr = []net, optimizer = build_net_optim()for epoch in range(cfg.max_epochs):# 学习率据epoch数目进行衰减optimizer = lr_decay(optimizer, epoch, cfg.base_lr)# 仅在第一个epoch内进行warmup,若num_warmup_iters超过了一个epoch所需的iteration,则第二个epoch后则默认以base_lr进行优化for cur_iter, data in enumerate(dataloader):if epoch == 0:optimizer = warmup_lr(optimizer, cur_iter)#print('{}/{}/{}'.format(epoch, cur_iter, optimizer.param_groups[0]['lr']))all_lr.append(optimizer.param_groups[0]['lr'])return all_lrif __name__ == '__main__':all_lr = main()plt.plot(range(len(all_lr)), all_lr, color='r')plt.show()plt.savefig('/root/lr.png', dpi=300)
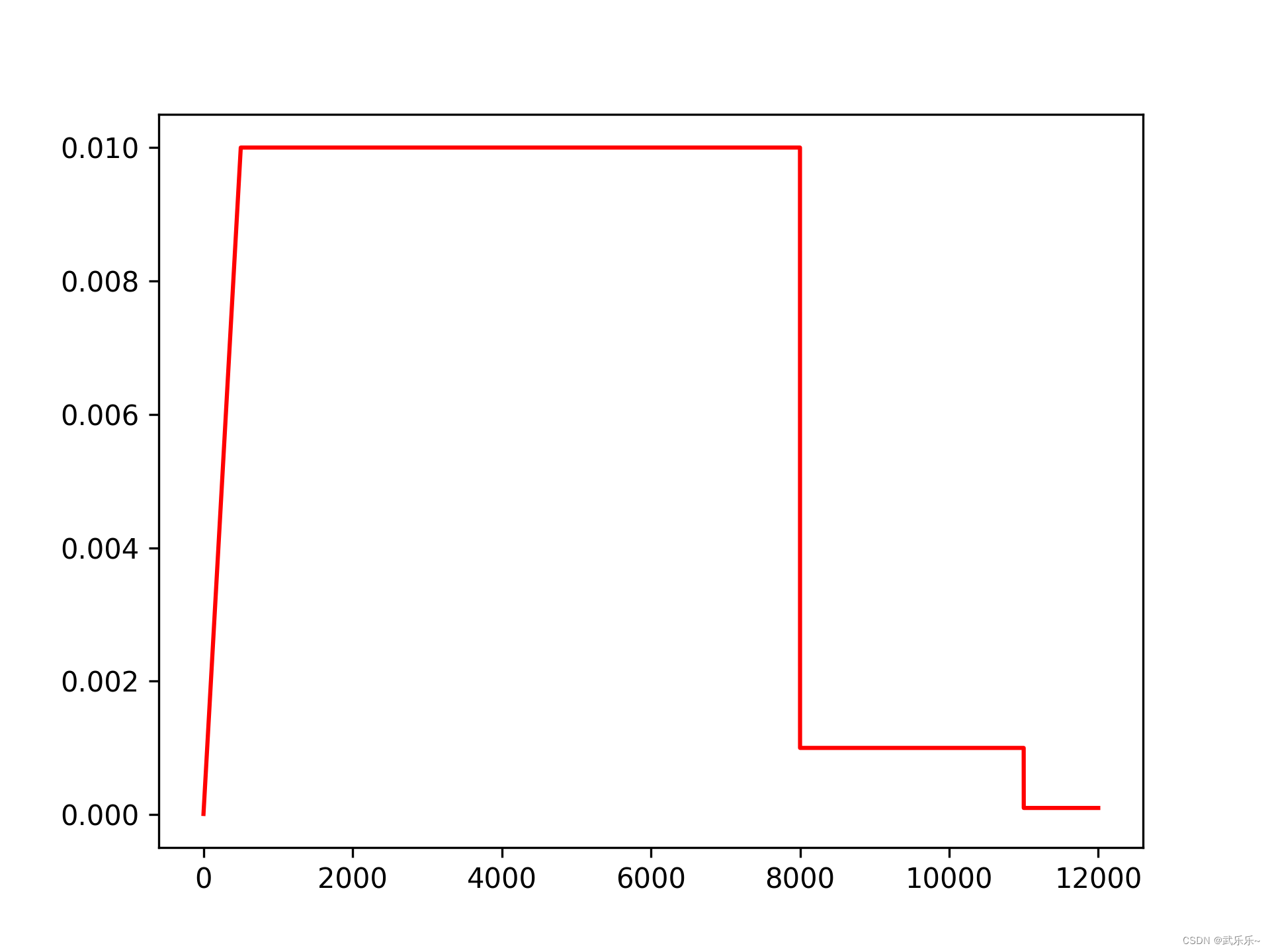
总结
后期会更新其余论文中的优化器及其学习率曲线,应该还会出一期可视化mmdetection学习率曲线的教程,以便对齐自己复现学习率曲线。敬请期待…
参考
https://mp.weixin.qq.com/s/t_gUJWWMLfkG06-R_pXJqQ
相关内容
热门资讯
Linux-scheduler...
四、调度域 SDTL结构 linux内核使用SDTL结构体来组织CPU的层次关系 struct sc...
leetcode - 2379...
Description You are given a 0-indexed string block...
Retinanet网络与foc...
参考代码:https://github.com/yhenon/pytorch-reti...