自然语言处理(三): Text Classification
迪丽瓦拉
2024-06-02 00:06:09
0次
目录
1. Classification
1.1 Text Classification Tasks
2. Algorithms for Classification
2.1 Choosing a Classification Algorithm
2.2 Naïve Bayes
2.3 Logistic Regression
2.4 Support Vector Machines
2.5 K-Nearest Neighbour
2.6 Decision tree
2.7 Random Forests
2.8 Neural Networks
编辑
2.9 Hyper-parameter Tuning
3. Evaluation
3.1 Accuracy
3.2 Precision & Recall
3.3 F(1)-score
4. A Final Word
1. Classification
Input
- A document d
- Often represented as a vector of features 通常表示为一个特征向量
- A fixed output set of classes C = {c1,c2,…ck}
- Categorical, not continuous (regression) or ordinal (ranking) 分类的,不是连续的(回归)或顺序的(排名)。
Output
- A predicted class c ∈ C
1.1 Text Classification Tasks
一些常见的例子
- 主题分类 Topic classification
- 情感分析 Sentiment analysis
- 本土语言识别 Native-language identification
- 自然语言推理 Natural language inference
- 自动事实核查 Automatic fact-checking
- 释义 Paraphrase
输入可能不是一个长的文件
- 句子或推文级情感分析
2. Algorithms for Classification
2.1 Choosing a Classification Algorithm
- Bias vs. Variance
- Bias: assumptions we made in our model 我们在模型中所作的假设
- Variance: sensitivity to training set 对训练集的敏感性
- Underlying assumptions, e.g., independence
- Complexity
- Speed
2.2 Naïve Bayes

Pros:
- Fast to train and classify
- robust, low-variance -> good for low data situations
- optimal classifier if independence assumption is correct
- extremely simple to implement.
Cons:
- Independence assumption rarely holds
- low accuracy compared to similar methods in most situations
- smoothing required for unseen class/feature combinations
2.3 Logistic Regression

Pros:
- Unlike Naive Bayes not confounded by diverse, correlated features better performance
Cons:
- Slow to train;
- Feature scaling needed
- Requires a lot of data to work well in practice
- Choosing regularisation strategy is important since overfitting is a big problem
2.4 Support Vector Machines
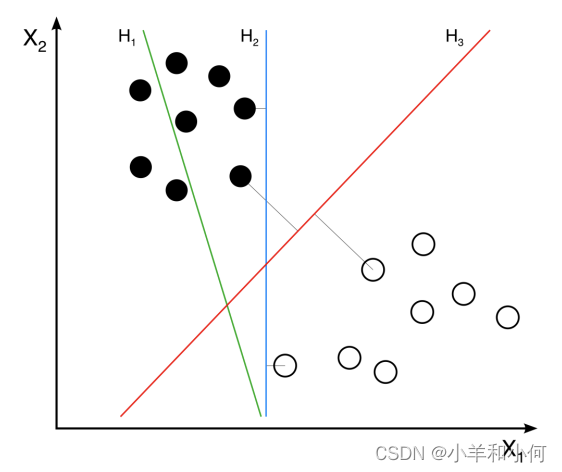
Finds hyperplane which separates the training data with maximum margin
Pros:
- Fast and accurate linear classifier
- Can do non-linearity with kernel trick
- works well with huge feature sets
Cons:
- Multiclass classification awkward
- Feature scaling needed
- Deals poorly with class imbalances
- Interpretability
2.5 K-Nearest Neighbour
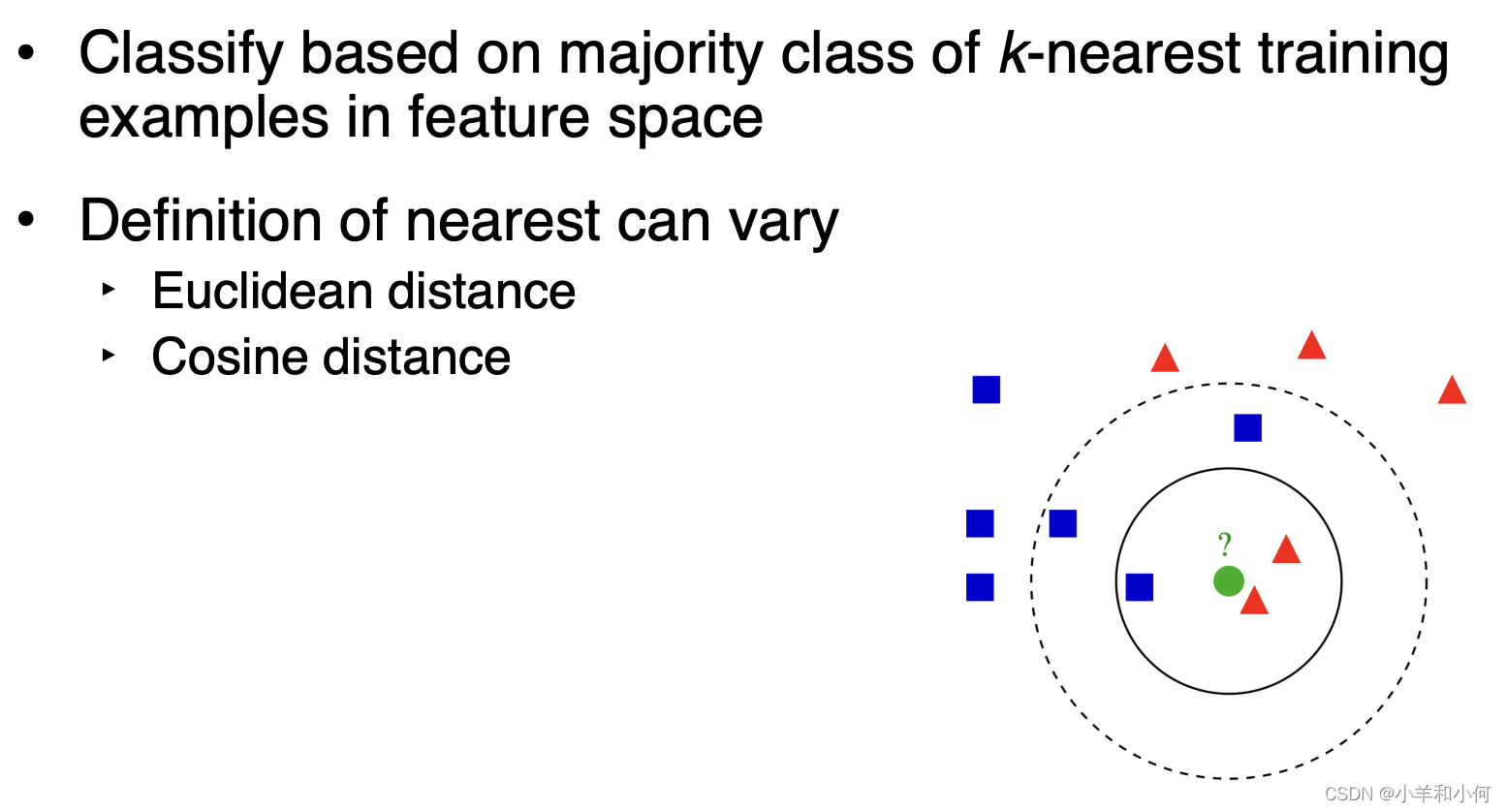
Pros:
- Simple but surprisingly effective
- No training required
- Inherently multiclass
- Optimal classifier with infinite data
Cons:
- Have to select k
- Issues with imbalanced classes
- Often slow (for finding the neighbours)
- Features must be selected carefully
2.6 Decision tree
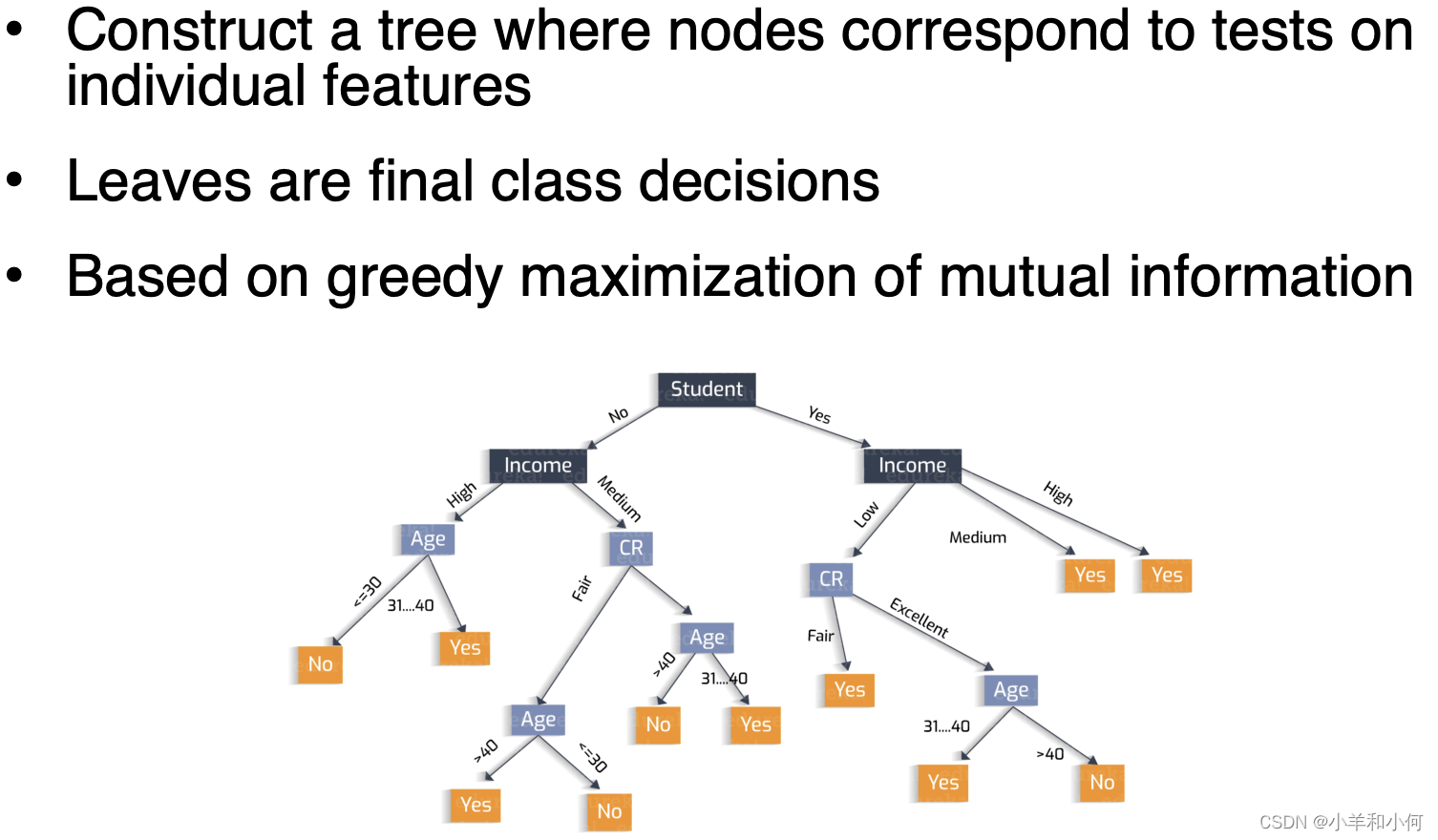
Pros:
- Fast to build and test
- Feature scaling irrelevant
- Good for small feature sets
- Handles non-linearly-separable problems
Cons:
- In practice, not that interpretable Highly redundant sub-trees
- Not competitive for large feature sets
2.7 Random Forests
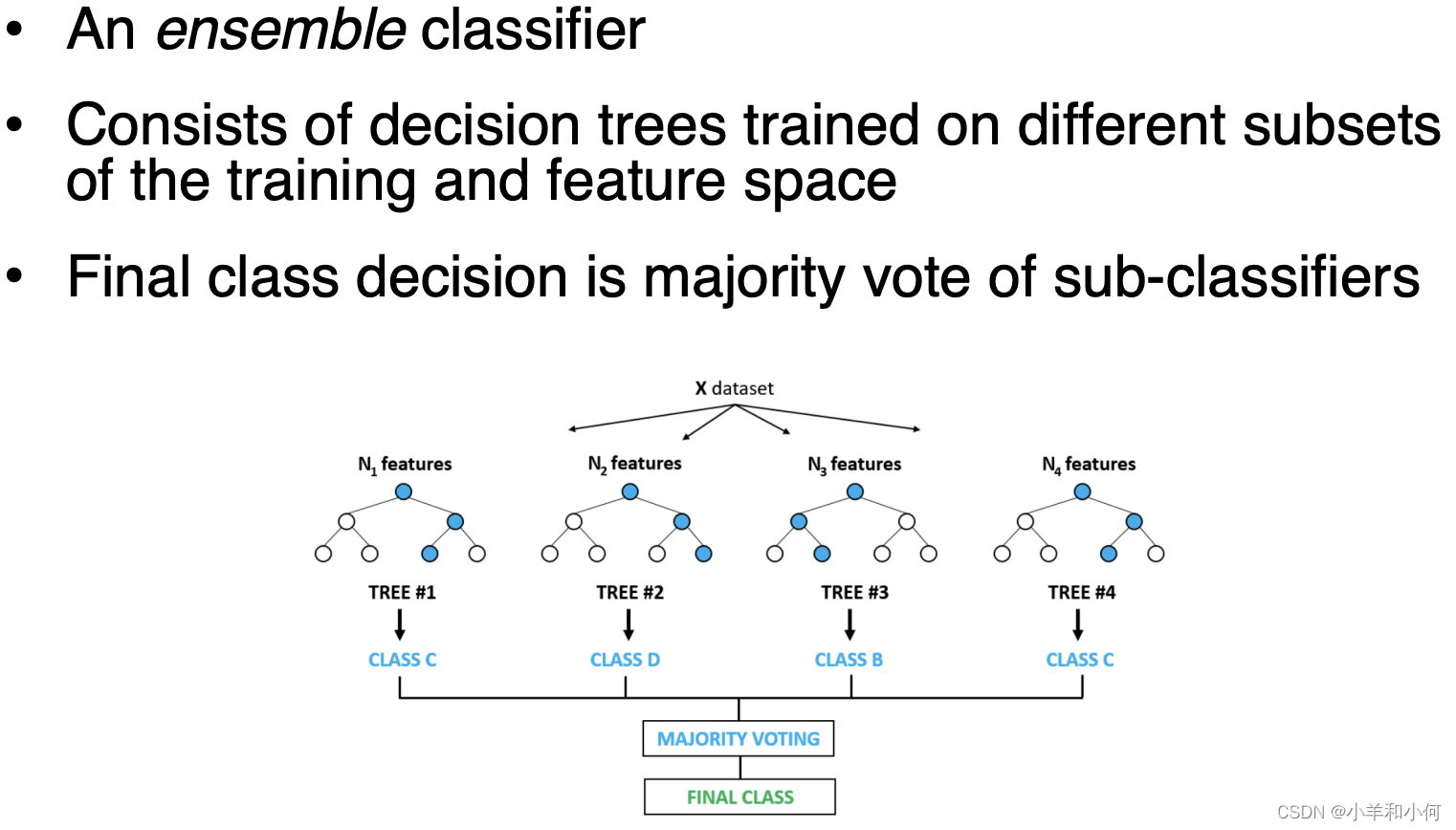
Pros:
- Usually more accurate and more robust than decision trees
- Great classifier for medium feature sets
- Training easily parallelised
Cons:
- Interpretability
- Slow with large feature sets
2.8 Neural Networks
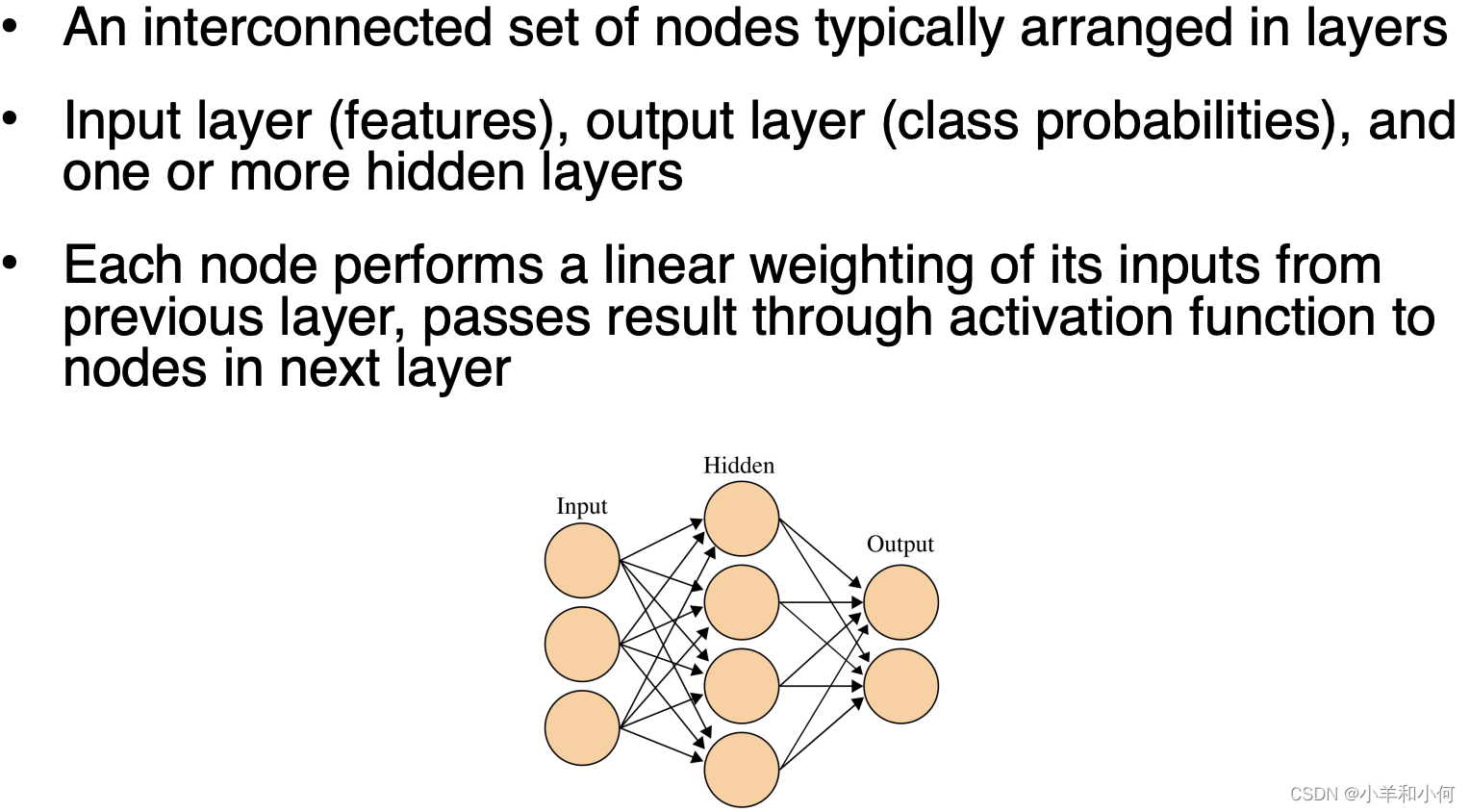
Ppros:
- Extremely powerful, dominant method in NLP and vision
- Little feature engineering
Cons:
- Not an off-the-shelf classifier
- Many hyper-parameters, difficult to optimise
- Slow to train
- Prone to overfitting
2.9 Hyper-parameter Tuning
- Dataset for tuning
- Development set
- Not the training set or the test set
- k-fold cross-validation
- Specific hyper-parameters are classifier specific
- E.g. tree depth for decision trees
- But many hyper-parameters relate to regularisation
- Regularisation hyper-parameters penalise model complexity
- Used to prevent overfitting
- For multiple hyper-parameters, use grid search
3. Evaluation
3.1 Accuracy
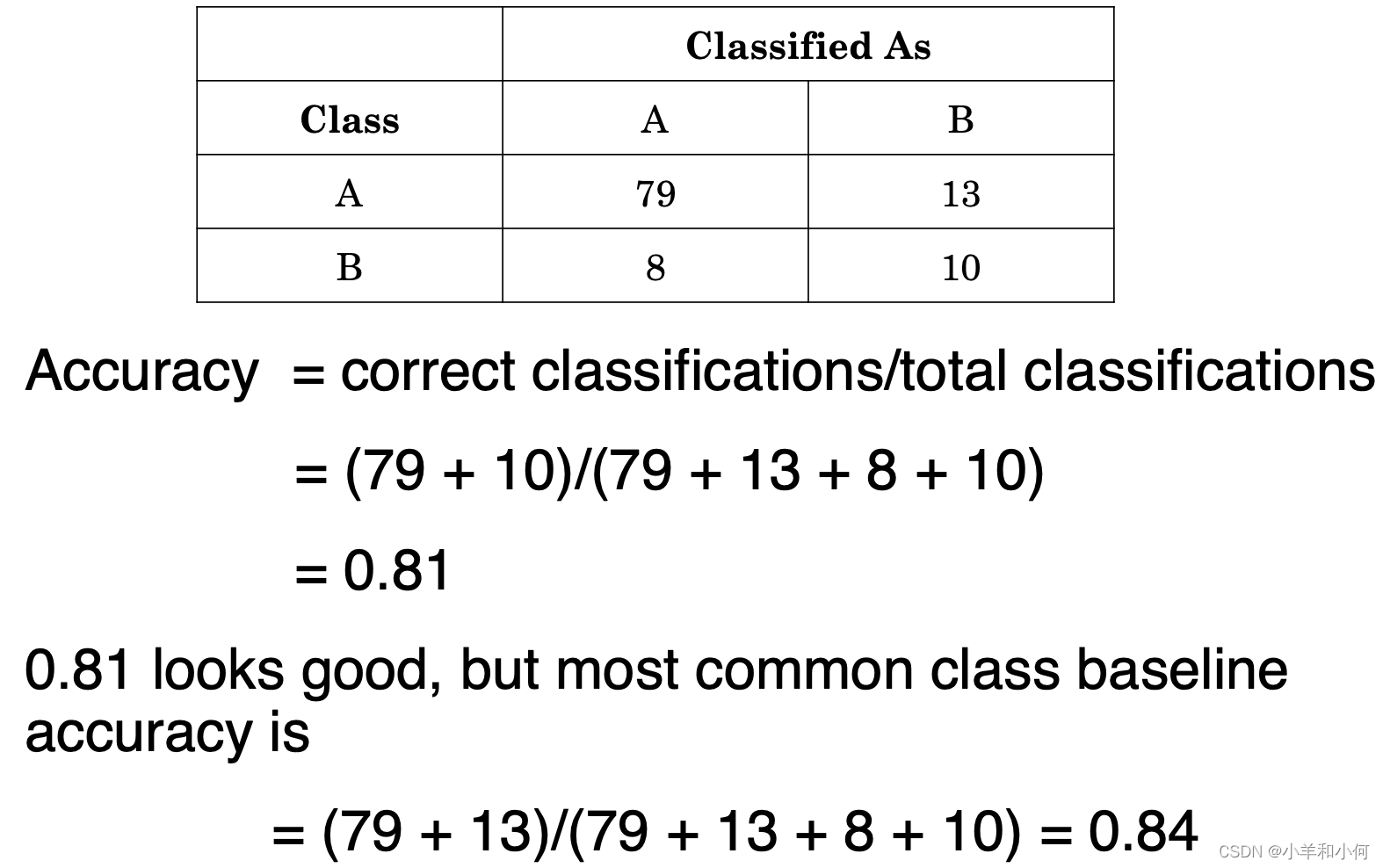
3.2 Precision & Recall
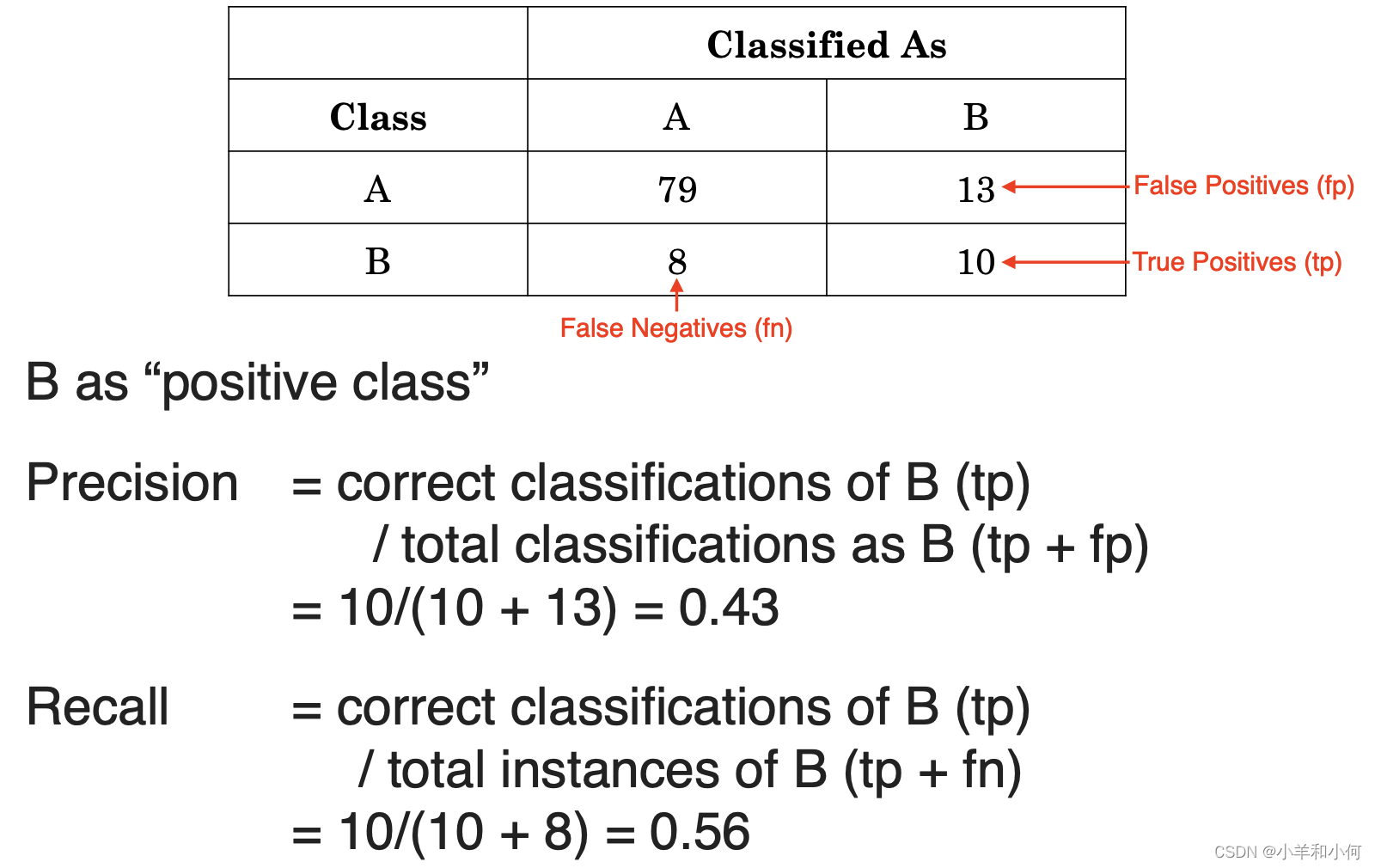
3.3 F(1)-score

4. A Final Word
- 在你感兴趣的任务上可以尝试很多算法(参见 scikit-learn)
- 但是,如果你的目标是在一项新任务中取得好的结果,那么注释良好、数据集丰富和适当的特性往往比所使用的特定算法更重要
上一篇:一个Bug让人类科技倒退几十年?
下一篇:NeRF in the Wild
相关内容
热门资讯
Linux-scheduler...
四、调度域 SDTL结构 linux内核使用SDTL结构体来组织CPU的层次关系 struct sc...
leetcode - 2379...
Description You are given a 0-indexed string block...
Retinanet网络与foc...
参考代码:https://github.com/yhenon/pytorch-reti...