【hadoop】集群配置
迪丽瓦拉
2024-06-01 19:53:45
0次
设置分发脚本
作用:循环复制文件到所有节点的相同目录下
脚本需要放在声明了全局环境变量的路径
echo $PATHcd /home/用户
mkdir bin
cd bin
vim xsync#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Arguement!exit;
fi#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4. 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone
donechmod +x xsync
xsync /home/atguigu/bin
将脚本复制到/bin 中,以便全局调用
sudo cp xsync /bin/
同步环境变量配置(root 所有者)
sudo ./bin/xsync /etc/profile.d/my_env.sh
如果用了 sudo,那么 xsync 一定要给它的路径补全。
source /etc/profile设置ssh免密登录
【Linux】ssh免密登录_岱宗夫如何、的博客-CSDN博客
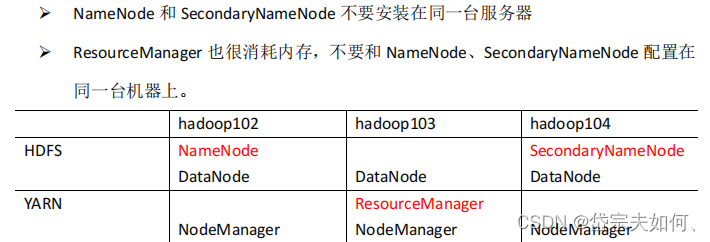
部署规划
配置文件
Hadoop 配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认 配置值时,才需要修改自定义配置文件,更改相应属性值 (1)默认配置文件:cd $HADOOP_HOME/share/hadoopcores-site.xml : 负责全局的配置(common)
hdfs-site.xml:负责hdfs的配置
mapred-site.xml: 负责mapreduce的配置
yarn-site.xml:负责yarn的配置
cd $HADOOP_HOME/etc/hadoopvim core-site.xml
fs.defaultFS hdfs://hadoop102:8020 hadoop.tmp.dir /opt/module/hadoop-3.1.3/data hadoop.http.staticuser.user atguigu vim hdfs-site.xml
dfs.namenode.http-address hadoop102:9870 dfs.namenode.secondary.http-address hadoop104:9868 vim yarn-site.xml
yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname hadoop103 yarn.nodemanager.env-whitelist JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME yarn.log-aggregation-enable true
yarn.log.server.url http://hadoop102:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds 604800
vim mapred-site.xml
mapreduce.framework.name yarn 分发配置文件
xsync /opt/module/hadoop-3.1.3/etc/hadoop/配置workers
vim /opt/module/hadoop-3.1.3/etc/hadoop/workershadoop102
hadoop103
hadoop104xsync /opt/module/hadoop-3.1.3/etc启动集群
第一次启动需要格式化NameNode
hdfs namenode -format会产生新的集群id。NameNode和DataNode集群id不一致,会找不到之前的数据。
如果需要格式化Namenode,先停掉namenode 和 datanode 进程,删除所有机器的data和logs目录。
启动HDFS
sbin/start-dfs.shsbin/start-yarn.shmapred --daemon start historyservercd /opt/module/hadoop-3.1.3/etc/hadoop
vim mapred-site.xml
mapreduce.jobhistory.address hadoop102:10020
mapreduce.jobhistory.webapp.address hadoop102:19888
xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml来源:Hadoop权威指南 Tom Wbite著
b站尚硅谷
相关内容
热门资讯
Linux-scheduler...
四、调度域 SDTL结构 linux内核使用SDTL结构体来组织CPU的层次关系 struct sc...
leetcode - 2379...
Description You are given a 0-indexed string block...
Retinanet网络与foc...
参考代码:https://github.com/yhenon/pytorch-reti...