Redis学习【12】之Redis 缓存
迪丽瓦拉
2024-06-01 01:43:21
0次
文章目录
- 前言
- 一 Jedis 简介
- 二 使用 Jedis
- 2.1 测试代码
- 2.2 使用 JedisPool
- 2.3 使用 JedisPooled
- 2.4 连接 Sentinel 高可用集群
- 2.5 连接分布式系统
- 2.6 操作事务
- 三 Spring Boot整合Redis
- 3.1 创建工程
- 3.2 定义 pom 文件
- 3.3 完整代码
- 3.4 总结
- 四 高并发问题
- 4.1 缓存穿透
- 4.2 缓存击穿
- 4.3 缓存雪崩
- 4.5 数据库缓存双写不一致
- 4.5.1 “修改 DB 更新缓存”场景
- 4.5.2 “修改 DB 删除缓存”场景
- 4.5.3 解决方案:延迟双删
- 4.5.4 解决方案:队列
- 4.5.4 解决方案:分布式锁
前言
- 本文是作者在学习redis的笔记,学习动力节点的redis课程
- 仅供学习交流,不得用于商业用途
一 Jedis 简介
- Jedis 是一个基于 java 的 Redis 客户端连接工具,旨在提升性能与易用性。github 上的官网地址
二 使用 Jedis
- Jedis 基本使用十分简单,其提供了非常丰富的操作 Redis 的方法,而这些方法名几乎与Redis 命令相同。
- 在每次使用时直接创建 Jedis 实例即可。在 Jedis 实例创建好之后,Jedis 底层实际会创建一个到指定 Redis 服务器的 Socket 连接。所以,为了节省系统资源与网络带宽,在每次使用完 Jedis 实例之后,需要立即调用 close()方法将连接关闭。
- 首先创建一个普通的 Maven 工程 ,然后在 POM 文件中添加 Jedis 与 Junit 依赖
redis.clients jedis 4.2.0
junit junit 4.11
org.slf4j slf4j-simple 1.7.25 test
2.1 测试代码
import org.junit.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.resps.Tuple;import java.util.HashMap;
import java.util.List;
import java.util.Set;/*** @author 缘友一世* date 2023/3/8-22:44*/
public class test {/*** value 为 String 的测试*/@Testpublic void test01() {Jedis jedis = new Jedis("192.168.28.123", 6379);jedis.set("name","007");jedis.mset("age","23","depart","market");System.out.println(jedis.get("name"));System.out.println(jedis.get("age"));System.out.println(jedis.get("depart"));jedis.close();}/*** value 为 Hash 的测试*/@Testpublic void test02() {Jedis jedis = new Jedis("192.168.28.123", 6379);jedis.hset("direction","east","north");HashMap map = new HashMap<>();map.put("height","500m");map.put("character","major");jedis.hset("mapTest",map);String heigt = jedis.hget("mapTest", "height");List mapTest = jedis.hmget("mapTest", "height", "character");System.out.println("height:"+heigt);System.out.println("mapTest:"+mapTest);jedis.close();}/*** value 为 List 的测试*/@Testpublic void test03() {Jedis jedis = new Jedis("192.168.28.123", 6379);jedis.rpush("cities","冰雪北境","南幻水乡","西凉荒漠");List cities = jedis.lrange("cities", 0, -1);System.out.println("cities:"+cities);jedis.close();}/*** value 为 Set 的测试*/@Testpublic void test04() {Jedis jedis = new Jedis("192.168.28.123", 6379);long sadd = jedis.sadd("midwares", "Redi", "Nginx", "RocketMQ");Set midwares = jedis.smembers("midwares");System.out.println("midwares:"+midwares);jedis.close();}/*** value 为 zSet 的测试*/@Testpublic void test05() {Jedis jedis = new Jedis("192.168.28.123", 6379);jedis.zadd("sales",80,"BMW");jedis.zadd("sales",90,"BYD");jedis.zadd("sales",60,"Benz");jedis.zadd("sales",70,"BMW");//获取销量前三List top = jedis.zrevrange("sales", 0, 2);System.out.println("top:"+top);List sales = jedis.zrevrangeWithScores("sales", 0, -1);for (Tuple sale:sales) {System.out.println(sale.getScore()+":"+sale.getElement());}jedis.close();}
} 2.2 使用 JedisPool
- 如果应用非常频繁地创建和销毁 Jedis 实例,虽然节省了系统资源与网络带宽,但会大大降低系统性能。因为创建和销毁 Socket 连接是比较耗时的。此时可以使用 Jedis 连接池来解决该问题。
- 使用 JedisPool 与使用 Jedis 实例的区别是,JedisPool 是全局性的,整个类只需创建一次即可,然后每次需要操作 Redis 时,只需从 JedisPool 中拿出一个 Jedis 实例直接使用即可。使用完毕后,无需释放 Jedis 实例,只需返回 JedisPool 即可。
/*** @author 缘友一世* date 2023/3/8-23:12*/
public class jedisPool {@Testpublic void test01(){JedisPool jedisPool = new JedisPool("192.168.28.123", 6379);try(Jedis jedis=jedisPool.getResource()) {jedis.set("name","007");jedis.mset("age","23","depart","market");System.out.println("name:"+jedis.get("name"));System.out.println("age"+jedis.get("age"));System.out.println("depart"+jedis.get("depart"));}}
}
2.3 使用 JedisPooled
- 对于每次对 Redis 的操作都需要使用 try-with-resource 块是比较麻烦的,而使用
JedisPooled则无需再使用该结构来自动释放资源
/*** 使用JedisPooled 则无需再使用该结构来自动释放资源*/
@Test
public void test02(){JedisPooled jedisPooled = new JedisPooled("192.168.28.123", 6379);//value为string的情况jedisPooled.set("id","212666");jedisPooled.mset("tools","weChat","search","everything");System.out.println("id:"+jedisPooled.get("id"));System.out.println("tools:"+jedisPooled.get("tools"));System.out.println("search:"+jedisPooled.get("search"));
}
2.4 连接 Sentinel 高可用集群
- 对于 Sentinel 高可用集群的连接,直接使用 JedisSentinelPool 即可。在该客户端只需注册所有 Sentinel 节点及其监控的 Master 的名称即可,无需出现 master-slave 的任何地址信息。
- 其采用的也是 JedisPool,使用完毕的 Jedis 也需要通过 close()方法将其返回给连接池。
/*** @author 缘友一世* date 2023/3/9-9:20*/
public class jedisSentinelPoolTest {private JedisSentinelPool jedisPool;{Set sentinels = new HashSet<>();sentinels.add("192.168.28.123:26380");sentinels.add("192.168.28.123:26381");sentinels.add("192.168.28.123:26382");jedisPool = new JedisSentinelPool("mymaster", sentinels);}@Testpublic void test01(){try(Jedis jedis=jedisPool.getResource()) {jedis.set("math","100");jedis.mset("math2","100","age2","18");System.out.println("math:"+jedis.get("math"));System.out.println("math2:"+jedis.get("math2"));System.out.println("age2:"+jedis.get("age2"));}}@Testpublic void test() {Jedis jedis = new Jedis("192.168.28.123", 6380);System.out.println(jedis.get("name"));}
} 2.5 连接分布式系统
- 对于 Redis 的分布式系统的连接,直接使用 JedisCluster 即可。其底层采用的也是 Jedis连接池技术。每次使用完毕后,无需显式关闭,其会自动关闭。
- 对于 JedisCluster 常用的构造器有两个:
- 一个是只需一个集群节点的构造器,这个节点可以是集群中的任意节点,只要连接上了该节点,就连接上了整个集群。但该构造器存在一个风险:其指定的这个节点在连接之前恰好宕机,那么该客户端将无法连接上集群。
- 所以,推荐使用第二个构造器,即将集群中所有节点全部罗列出来。这样就会避免这种风险
/*** @author 缘友一世* date 2023/3/9-12:29*/
public class jedisClusterTest {private JedisCluster jedisCluster;{HashSet nodes = new HashSet<>();nodes.add(new HostAndPort("192.168.28.123",6380));nodes.add(new HostAndPort("192.168.28.123",6381));nodes.add(new HostAndPort("192.168.28.123",6382));nodes.add(new HostAndPort("192.168.28.123",6383));nodes.add(new HostAndPort("192.168.28.123",6384));nodes.add(new HostAndPort("192.168.28.123",6385));jedisCluster=new JedisCluster(nodes);}@Testpublic void test01(){jedisCluster.set("name","wuwang");System.out.println("name:"+jedisCluster.get("name"));}
} 2.6 操作事务
- 对于 Redis 事务的操作,Jedis 提供了 multi()、watch()、unwatch()方法来对应 Redis 中的multi、watch、unwatch 命令。Jedis的 multi()方法返回一个 Transaction 对象,其 exec()与 discard()方法用于执行和取消事务的执行
/*** @author 缘友一世* date 2023/3/9-23:04*/
public class jedisTxTest {public static void main(String[] args) {JedisPool jedisPool = new JedisPool("192.168.28.123", 6379);try(Jedis jedis=jedisPool.getResource()) {jedis.set("name","001");//构造异常Transaction multi = jedis.multi();try {int i=1/0;multi.set("name","002");multi.exec();}catch (Exception e) {//发生异常全部,回滚multi.discard();}finally {System.out.println(jedis.get("name"));}}}
}
三 Spring Boot整合Redis
- 下面通过一个例子来说明 Spring Boot 是如何与 Redis 进行整合的。
- 对于一个资深成熟的金融产品交易平台,其用户端首页一般会展示其最新金融产品列表,同时还为用户提供了产品查询功能。另外,为了显示平台的实力与信誉,在平台首页非常显眼的位置还会展示平台已完成的总交易额与注册用户数量。对于管理端,管理员可通过管理
页面修改产品、上架新产品、下架老产品。 - 为了方便了解 Redis 与 Spring Boot 的整合流程,这里对系统进行了简化:用户端首页仅提供根据金融产品名称的查询,显眼位置仅展示交易总额。管理端仅实现上架新产品功能。
- 对于一个资深成熟的金融产品交易平台,其用户端首页一般会展示其最新金融产品列表,同时还为用户提供了产品查询功能。另外,为了显示平台的实力与信誉,在平台首页非常显眼的位置还会展示平台已完成的总交易额与注册用户数量。对于管理端,管理员可通过管理
3.1 创建工程
- 定义一个 Spring Boot 工程
3.2 定义 pom 文件
- 在 pom 文件中需要导入 MySQL 驱动、Druid 等大量依赖
DROP TABLE IF EXISTS `product`;
CREATE TABLE `product` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(20) DEFAULT NULL,`rate` double DEFAULT NULL,`amount` double DEFAULT NULL,`raised` double DEFAULT NULL,`cycle` int(11) DEFAULT NULL,`endTime` char(10) DEFAULT '0',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;INSERT INTO `product` VALUES
(1,'天鑫添益 2',2.76,50000,20000,30,'2022-07-10'),
(2,'国泰添益',2.86,30000,30000,60,'2022-07-12'),
(3,'国泰高鑫',2.55,60000,50000,90,'2022-07-09'),
(4,'国福民安',2.96,30000,20000,7,'2022-05-10'),
(5,'天益鑫多',2.65,80000,60000,20,'2022-07-05'),
(6,'惠农收益',3.05,30000,20000,10,'2022-06-10'),
(7,'惠农三鑫',2.76,50000,30000,30,'2022-07-02'),
(8,'励学收益',2.86,30000,20000,20,'2022-07-11');
3.3 完整代码
- 项目源码地址
- 源码的内容,自动力节点案例的改进【主要解决:打开主页面,直接卸载jsp文件的错误】
- 这里作者遇到了打开jsp主页,直接下载了jsp文件。可能的原因是浏览器配置了
NDM多线程下载器
3.4 总结
- 如何将 Spring Boot 与 Redis 整合?
- 在 POM 中导入依赖
- 在配置文件中注册 Redis 连接信息与缓存信息
- 需要缓存到 Redis 中的实体类必须要序列化
- Spring Boot 启动类中要添加@EnableCaching 注解
- 查询方法上要添加@Cacheable 注解
- 对数据进行写操作的方法上添加@CacheEvict 注解
- 对于需要手工操作 Redis 的方法,需通过 RedisTemplate 来获取操作对象
四 高并发问题
- Redis 做缓存虽减轻了 DBMS 的压力,减小了 RT,但在高并发情况下也是可能会出现各种问题的。
4.1 缓存穿透
- 当用户访问的数据既不在缓存也不在数据库中时,就会导致每个用户查询都会“穿透”缓存“直抵”数据库。这种情况就称为缓存穿透。当高度发的访问请求到达时,缓存穿透不仅增加了响应时间,而且还会引发对 DBMS 的高并发查询,这种高并发查询很可能会导致DBMS 的崩溃。
- 缓存穿透产生的主要原因有两个:一是在数据库中没有相应的查询结果,二是查询结果为空时,不对查询结果进行缓存。所以,针对以上两点,解决方案也有两个:
- 对非法请求进行限制
- 对结果为空的查询给出默认值
4.2 缓存击穿
- 对于某一个缓存,在高并发情况下若其访问量特别巨大,当该缓存的有效时限到达时,可能会出现大量的访问都要重建该缓存,即这些访问请求发现缓存中没有该数据,则立即到DBMS 中进行查询,那么这就有可能会引发对 DBMS 的高并发查询,从而接导致 DBMS 的崩溃。这种情况称为缓存击穿,而该缓存数据称为热点数据。
- 对于缓存击穿的解决方案,较典型的是使用“双重检测锁”机制。
4.3 缓存雪崩
- 对于缓存中的数据,很多都是有过期时间的。若大量缓存的过期时间在同一很短的时间段内几乎同时到达,那么在高并发访问场景下就可能会引发对 DBMS 的高并发查询,而这将可能直接导致 DBMS 的崩溃。这种情况称为缓存雪崩。
- 对于缓存雪崩没有很直接的解决方案,最好的解决方案就是预防,即提前规划好缓存的过期时间。要么就是让缓存永久有效,当 DB 中数据发生变化时清除相应的缓存。如果 DBMS采用的是分布式部署,则将热点数据均匀分布在不同数据库节点中,将可能到来的访问负载
均衡开来。
4.5 数据库缓存双写不一致
- 以上三种情况都是针对高并发读场景中可能会出现的问题,而数据库缓存双写不一致问题,则是在高并发写场景下可能会出现的问题。
对于数据库缓存双写不一致问题,以下两种场景下均有可能会发生:
4.5.1 “修改 DB 更新缓存”场景
- 对于具有缓存 warmup 功能的系统,DBMS 中常用数据的变更,都会引发缓存中相关数据的更新。在高并发写请求场景下,若多个请求要对 DBMS 中同一个数据进行修改,修改后还需要更新缓存中相关数据,那么就有可能会出现缓存与数据库中数据不一致的情况。
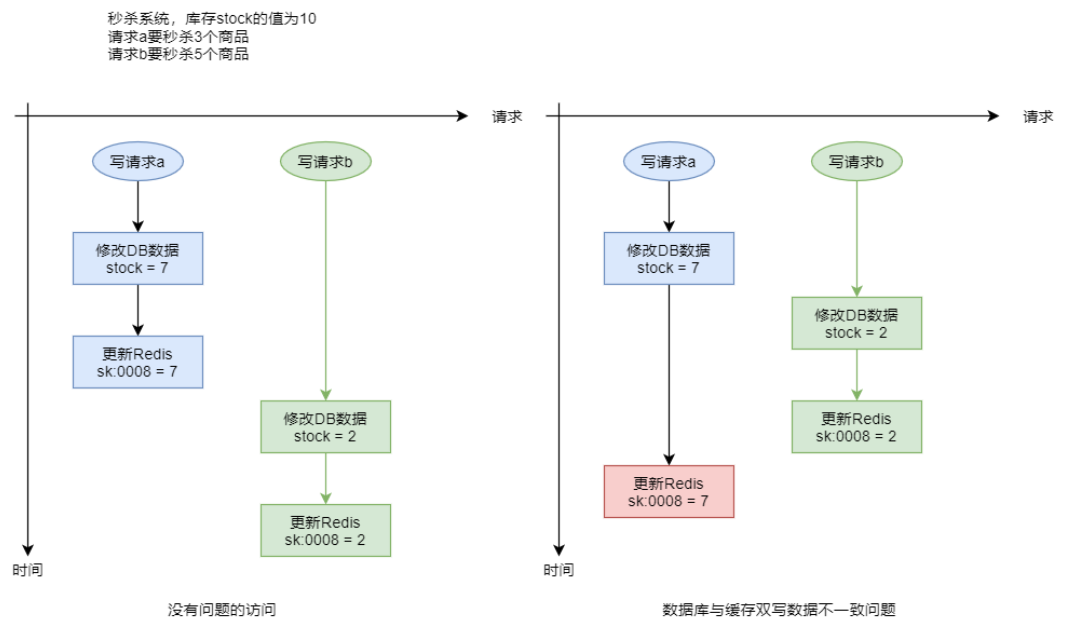
4.5.2 “修改 DB 删除缓存”场景
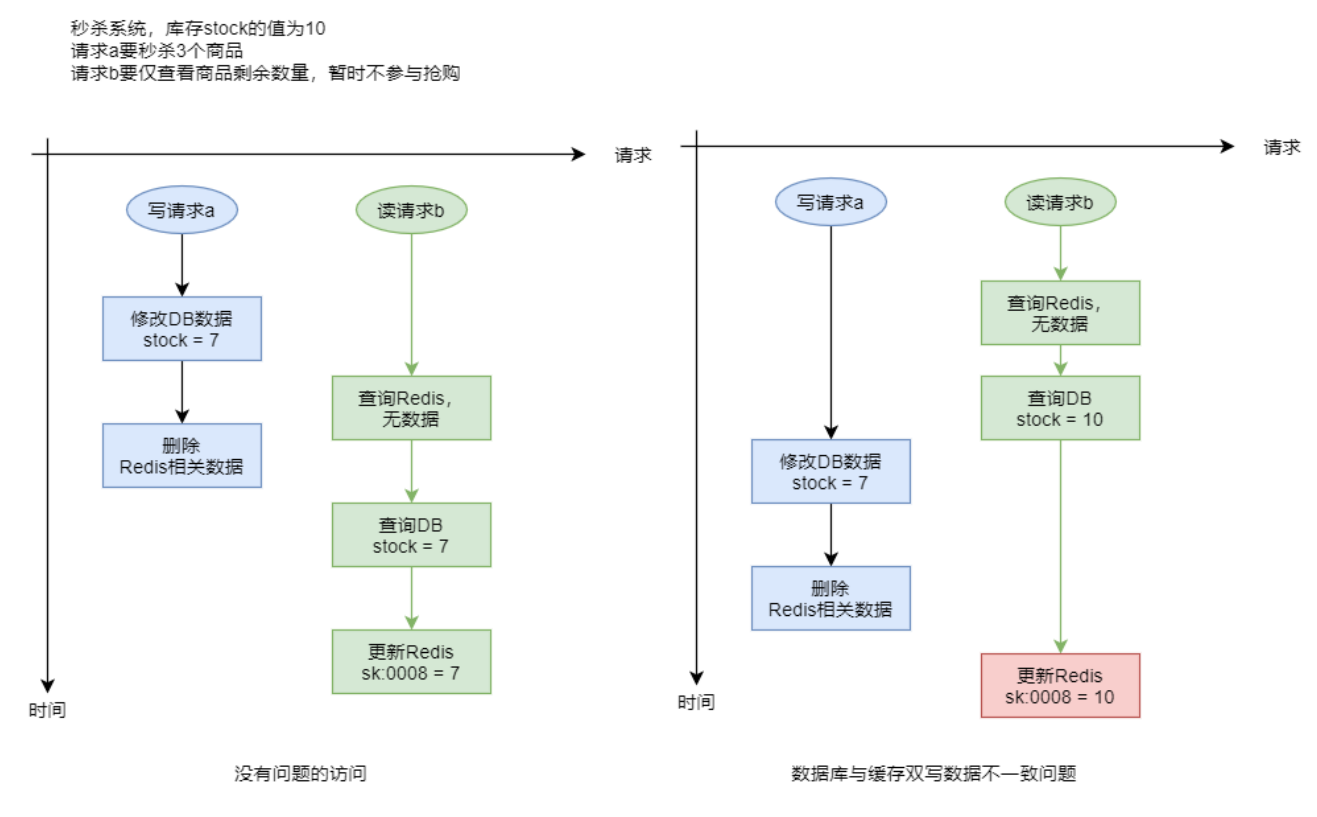
- 在很多系统中是没有缓存 warmup 功能的,为了保持缓存与数据库数据的一致性,一般都是在对数据库执行了写操作后,就会删除相应缓存。
- 在高并发读写请求场景下,若这些请求对 DBMS 中同一个数据的操作既包含写也包含读,且修改后还要删除缓存中相关数据,那么就有可能会出现缓存与数据库中数据不一致的情况
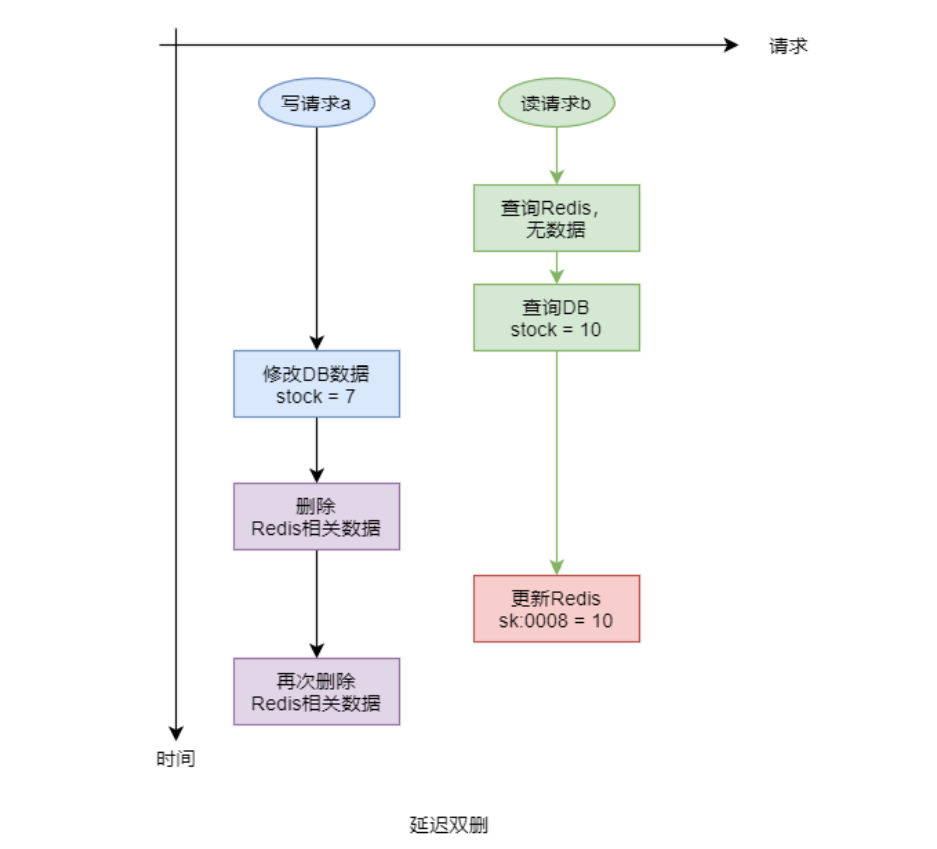
4.5.3 解决方案:延迟双删
- 延迟双删方案是专门针对于“修改 DB 删除缓存”场景的解决方案。但该方案并不能彻底解决数据不一致的状况,其只可能降低发生数据不一致的概率。
- 延迟双删方案是指,在写操作完毕后会立即执行一次缓存的删除操作,然后再停上一段时间(一般为几秒)后再进行一次删除。而两次删除中间的间隔时长,要大于一次缓存写操作的时长。
4.5.4 解决方案:队列
- 以上两种场景中,只所以会出现数据库与缓存中数据不一致,主要是因为对请求的处理出现了并行。只要将请求写入到一个统一的队列,只有处理完一个请求后才可处理下一个请求,即使系统对用户请求的处理串行化,就可以完全解决数据不一致的问题。
4.5.4 解决方案:分布式锁
- 使用队列的串行化虽然可以解决数据库与缓存中数据不一致,但系统失去了并发性,降低了性能。使用分布式锁可以在不影响并发性的前提下,协调各处理线程间的关系,使数据库与缓存中的数据达成一致性。
- 只需要对数据库中的这个共享数据的访问通过分布式锁来协调对其的操作访问即可。
相关内容
热门资讯
Linux-scheduler...
四、调度域 SDTL结构 linux内核使用SDTL结构体来组织CPU的层次关系 struct sc...
leetcode - 2379...
Description You are given a 0-indexed string block...
Retinanet网络与foc...
参考代码:https://github.com/yhenon/pytorch-reti...