Pandas库:从入门到应用(一)
一、Pandas简介

pandas是 Python 的核⼼数据分析⽀持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。pandas是Python进⾏数据分析的必备⾼级⼯具。
pandas的主要数据结构是 **Series(**⼀维数据)与 DataFrame (⼆维数据),这两种数据结构⾜以处理⾦融、统计、社会科学、⼯程等领域⾥的⼤多数案例
处理数据⼀般分为⼏个阶段:数据整理与清洗、数据分析与建模、数据可视化与制表,Pandas 是处理数据的理想⼯具
二、Pandas 安装验证
2.1、本地wendows或linux直接pip安装
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
2.2、登入python验证
import pandas as pd ## 没有报错说明pandas安装成功

三、Pandas 的数据结构
3.1、Series
Series对象用来表示一维数据结构 ,和常规的数组类型,但是Series的内部结构是包含了两个数组
一个是用来保存数据(data),一个是用来保存数据的索引(index)
pandas.Series( data, index, dtype, name, copy)
参数说明:
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
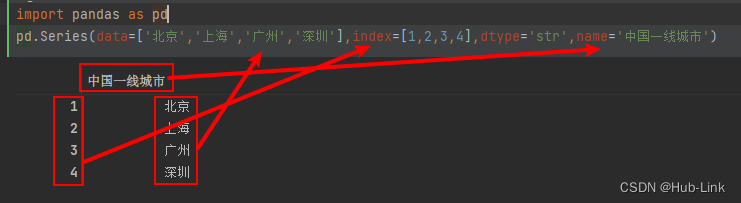
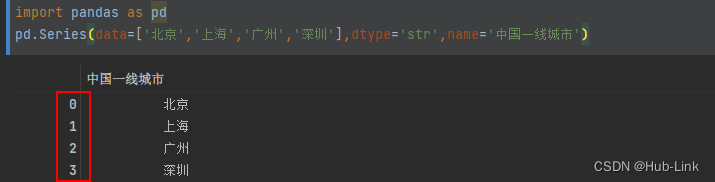
pd.Series(data=['北京','上海','广州','深圳'],index=[1,2,3,4],dtype='str',name='中国一线城市')
如果不指定索引(index)会自动从0开始
3.2、DataFrame
DataFrame 是一个二维数组的数据结构,类似Excel、sql表。
DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
df1 = pd.DataFrame(data = np.random.randint(0,151,size=(3,3)), #index = ['张三','李四','王五'], # ⾏索引columns= ['python','math','english'])
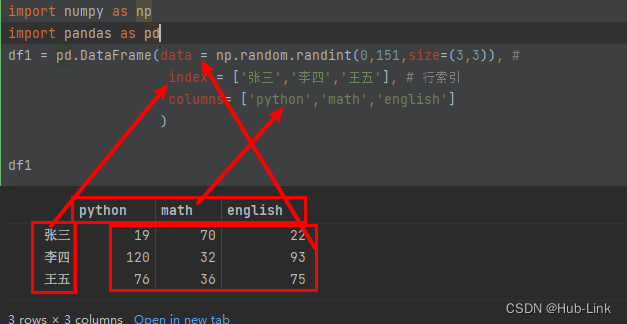
四、DataFrame的常用属性
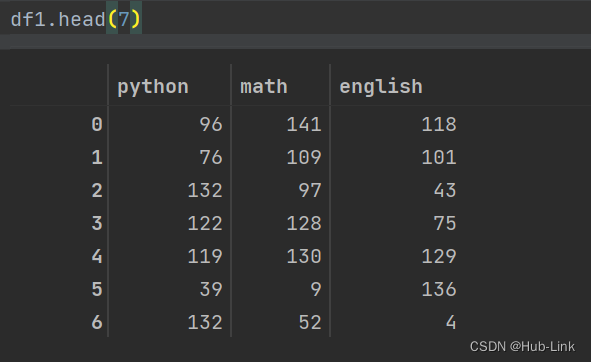
4.1、head()函数
显示头部数据,默认显示头部5行数据
import numpy as np
import pandas as pd
df1 = pd.DataFrame(data = np.random.randint(0,151,size=(10,3)), columns= ['python','math','english'])
df1.head(7) ##显示前7行数据
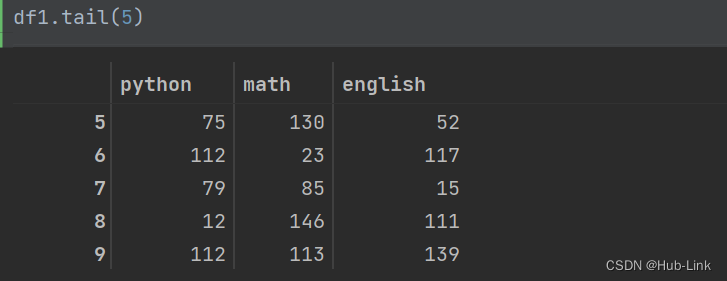
4.2、tail()函数
显示尾部数据,默认显示尾部5行数据
df1.tail(5)
4.3、shape 函数
显示DataFrame数据结构的行数和列数
df1.shape ## (10, 3)
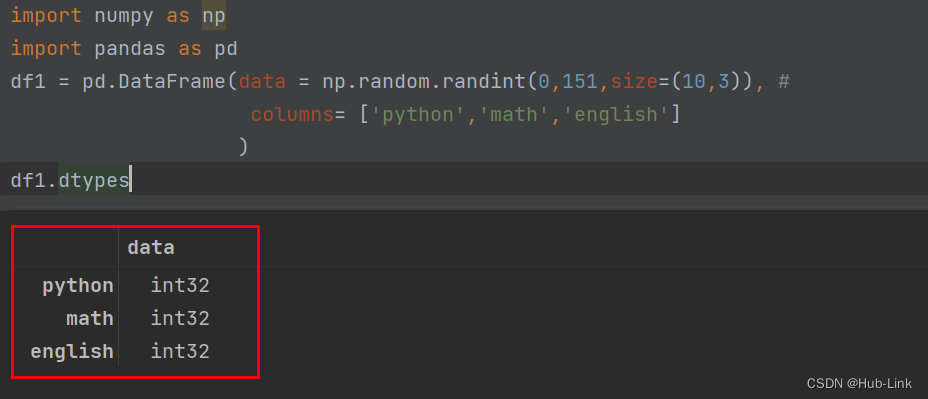
4.4、dtypes 函数
显示各列的数据类型
df1.dtypes
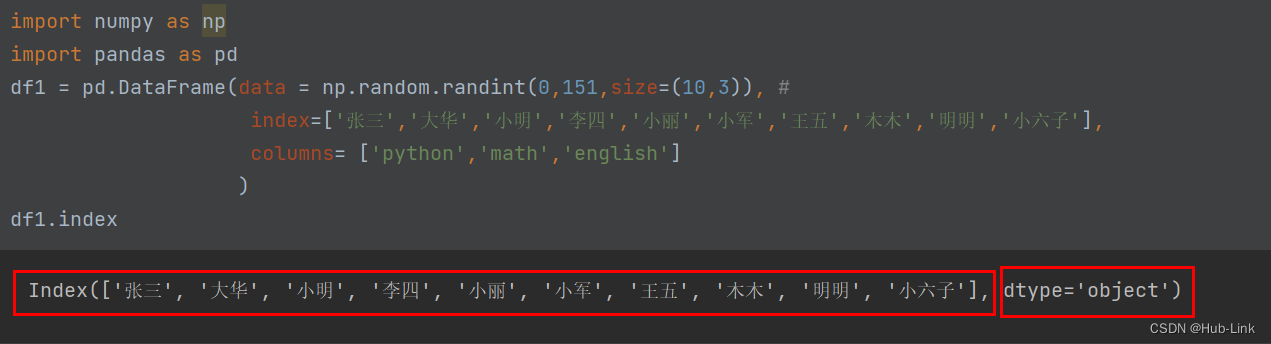
4.5、index 函数
显示DataFrame数据的行索引,及索引类型
import numpy as np
import pandas as pd
df1 = pd.DataFrame(data = np.random.randint(0,151,size=(10,3)), #index=['张三','大华','小明','李四','小丽','小军','王五','木木','明明','小六子'],columns= ['python','math','english'])
df1.index
4.6、columns 函数
显示DataFrame数据的列索引,及索引类型
df1.columns
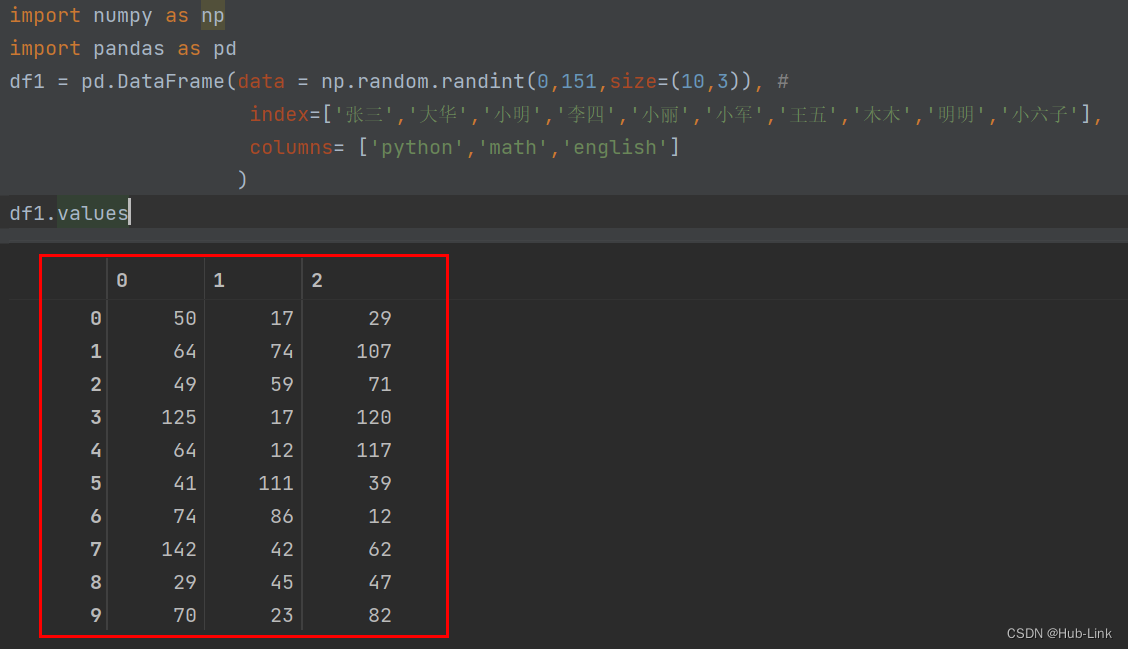
4.7、values 函数
显示DataFrame数据的二维ndarray数组
df1.values
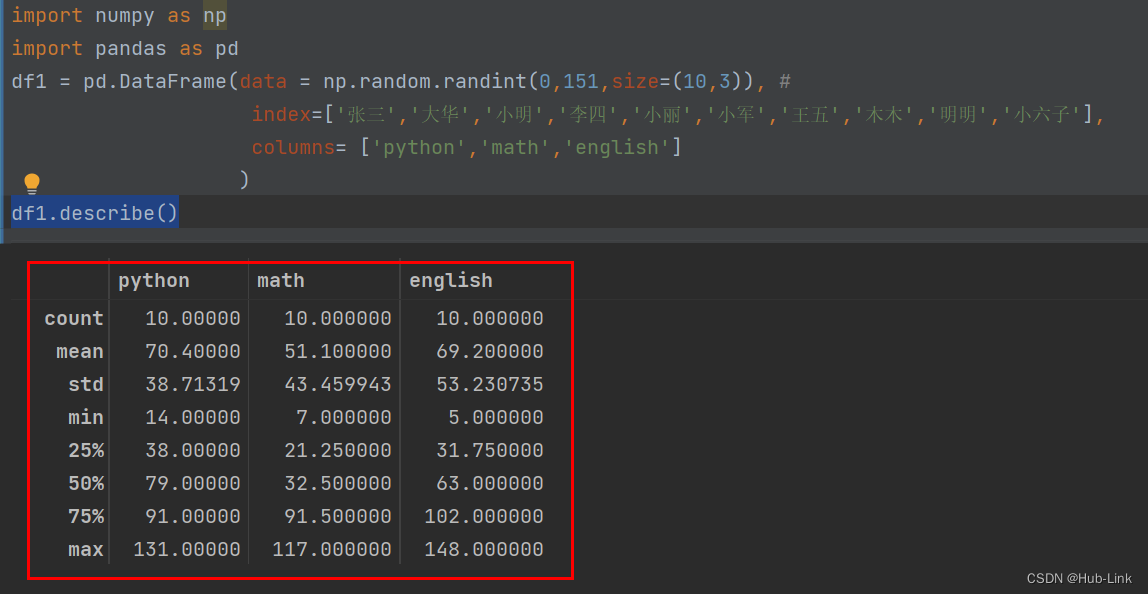
4.8、describe() 函数
查看数值型列的汇总统计,计数、平均值、标准差、最⼩值、四分位数、最⼤值
df1.describe()
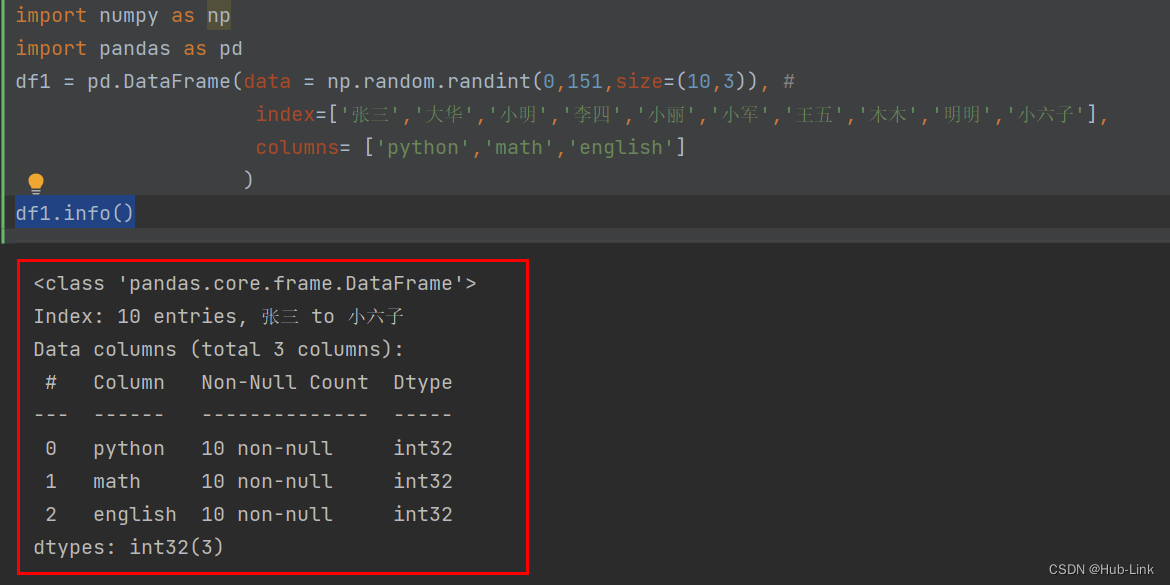
4.9、info() 函数
查看列索引、数据类型、⾮空计数和内存信息
df1.info()
五、Pandas 数据输入与输出
5.1、操作csv文件
5.1.1、写入csv文件
import numpy as np
import pandas as pd
df1 = pd.DataFrame(data = np.random.randint(0,151,size=(10,3)), #index=['张三','大华','小明','李四','小丽','小军','王五','木木','明明','小六子'],columns= ['python','math','english'])df1.to_csv('./score.csv',sep = ',', # ⽂本分隔符,默认是逗号header = True,# 是否保存列索引index = True, # 是否保存⾏索引,保存⾏索引,⽂件被加载时,默认⾏索引会作为⼀列index_label= '姓名') # 设置index列的名称
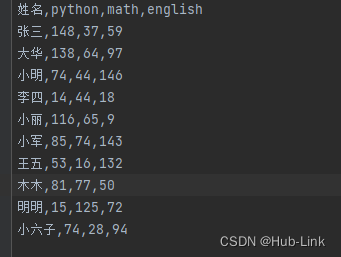
5.1.2、读取csv文件
import numpy as np
import pandas as pd
pd.read_csv('./score.csv',sep = ',',# 默认是逗号header = [0],#指定列索引index_col=0) # 指定⾏索引pd.read_table('./score.csv', # 和read_csv类似,读取限定分隔符的⽂本⽂件sep = ',',header = [0],#指定列索引index_col=0) # 指定⾏索引

5.2、操作Excel文件
5.2.1、下载Excel的包
pip install xlrd -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install xlwt -i https://pypi.tuna.tsinghua.edu.cn/simple
5.2.2、写入Excel文件
import numpy as np
import pandas as pd
import xlrd
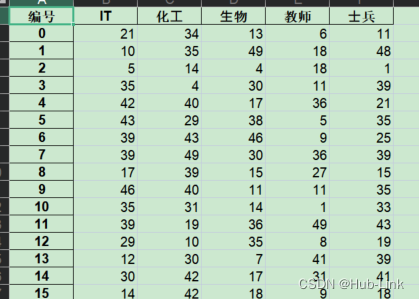
df1 = pd.DataFrame(data = np.random.randint(0,50,size = [50,5]), # 薪资情况columns=['IT','化⼯','⽣物','教师','⼠兵'])
# 保存到当前路径下,⽂件命名是:salary.xls
df1.to_excel('./salary.xls',sheet_name = 'salary',# Excel中sheet⼯作表的名字header = True,# 是否保存列索引index = True,# 是否保存⾏索引index_label= '编号' # 设置index列的名称)
5.2.3、⼀个Excel⽂件中保存多个⼯作表
import numpy as np
import pandas as pd
import xlrd
import xlwt
import openpyxl
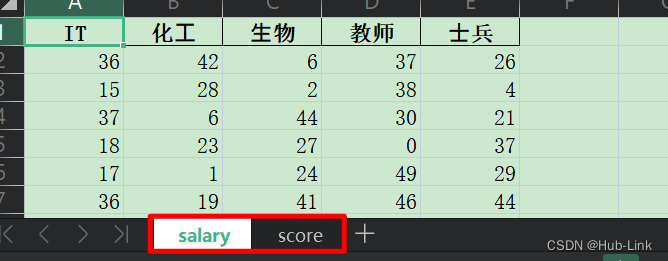
df1 = pd.DataFrame(data = np.random.randint(0,50,size = [50,5]), # 薪资情况columns=['IT','化⼯','⽣物','教师','⼠兵'])
df2 = pd.DataFrame(data = np.random.randint(0,50,size = [150,3]),# 计算机科⽬的考试成绩columns=['Python','Tensorflow','Keras'])# ⼀个Excel⽂件中保存多个⼯作表
with pd.ExcelWriter('./data.xls') as writer:df1.to_excel(writer,sheet_name='salary',index = False)df2.to_excel(writer,sheet_name='score',index = False)
5.2.4、读取Excel文件
import numpy as np
import pandas as pd
import xlwtpd.read_excel('./salary.xls',sheet_name=0,# 读取哪⼀个Excel中⼯作表,默认第⼀个header = 0,# 使⽤第⼀⾏数据作为列索引index_col=0)# 指定⾏索引,A作为⾏索引
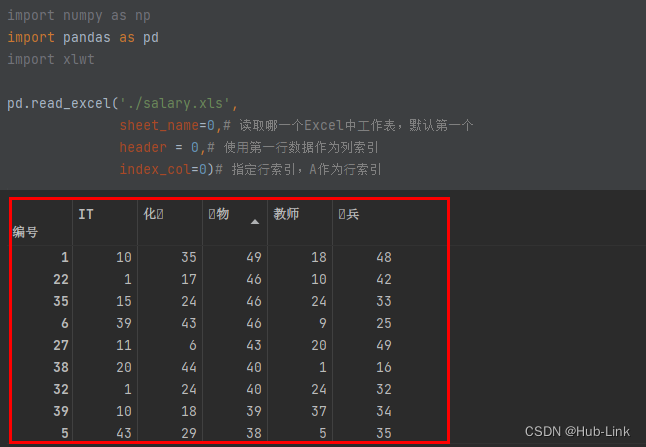
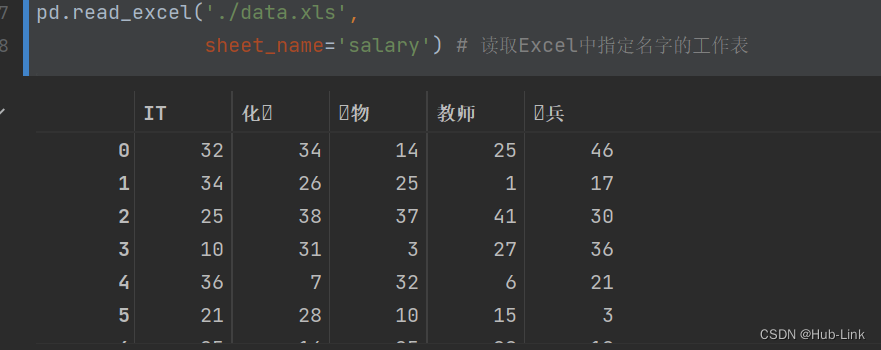
pd.read_excel('./data.xls',sheet_name='salary') # 读取Excel中指定名字的⼯作表
5.3、操作HDF5文件
5.3.1、HDF5简介及安装
- HDF5是⼀个独特的技术套件,可以管理⾮常⼤和复杂的数据收集。
- HDF5可以存储不同类型数据的⽂件格式,后缀通常是.h5,它的结构是层次性的。
- HDF5⽂件可以被看作是⼀个组包含了各类不同的数据集。
pip install tables -i https://pypi.tuna.tsinghua.edu.cn/simple
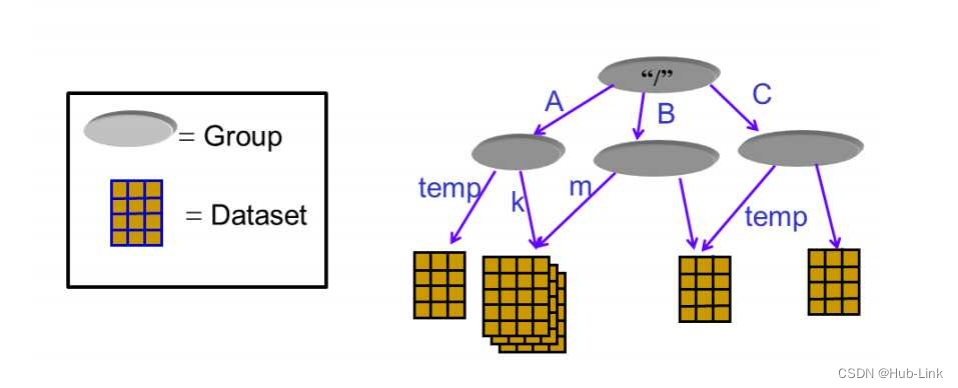
5.3.2、HDF5架构
对于HDF5⽂件中的数据存储,有两个核⼼概念:group 和 dataset
dataset :代表数据集,⼀个⽂件当中可以存放不同种类的数据集,
group:最直观的理解,可以参考我们的⽂件管理系统,不同的⽂件位于不同的⽬录下,⽬录就是HDF5中的group
5.3.2、写入HDF5文件
import numpy as np
import pandas as pddf1 = pd.DataFrame(data = np.random.randint(0,50,size = [50,5]), # 薪资情况columns=['IT','化⼯','⽣物','教师','⼠兵'])
df2 = pd.DataFrame(data = np.random.randint(0,50,size = [150,3]),# 计算机科⽬的考试成绩
columns=['Python','Tensorflow','Keras'])
# 保存到当前路径下,⽂件命名是:data.h5
df1.to_hdf('./data.h5',key='salary') # 保存数据的key,标记
df2.to_hdf('./data.h5',key = 'score')
.h5文件没法直接打开,打开全都乱码了,但是还是看到有HDF的标识
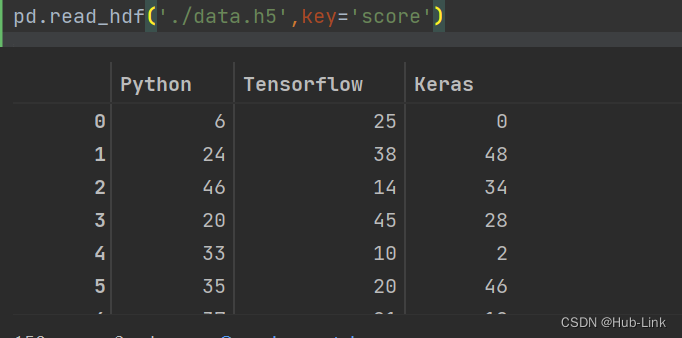
5.3.3、读取HDF5文件
pd.read_hdf('./data.h5',key='score')