34- PyTorch数据增强和迁移学习 (PyTorch系列) (深度学习)
迪丽瓦拉
2024-05-30 09:23:06
0次
知识要点
- 对vgg 模型进行迁移学习
- 定义数据路径: train_dir = os.path.join(base_dir, 'train') # base_dir = './dataset'
-
定义转换格式:
transform = transforms.Compose([transforms.Resize((96, 96)), # 统一缩放transforms.ToTensor(), # 转换为tensortransforms.Normalize(mean=[0.5, 0.5, 0.5], # 正则化std=[0.5, 0.5, 0.5])])- 数据转换: train_ds = torchvision.datasets.ImageFolder(train_dir, transform=transform)
- train_d1 = torch.utils.data.DataLoader(train_ds, batch_size=batch_size, shuffle=True, drop_last=True) # 定义数据训练格式
- 修改结果特征, 4分类: model.classifier[-1].out_features = 4 # 调整输出层
- 数据位置调整: device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
- 定义优化器: optimizer = optim.Adam(model.parameters(), lr=0.001)
- 定义损失: loss_fn = nn.CrossEntropyLoss()
- 梯度归零: optimizer.zero_grad()
- loss.backward()
- 梯度更新: optimizer.step()
- 查看模型: model.parameters
- 图示: plt.plot(range(1, epochs+1), train_loss, label='train_loss')
- 图例显示: plt.legend()
- 模型参数: model.state_dict()
- 保存参数: torch.save(model.state_dict(), './vgg16.pth')
- 给模型传参: new_model.load_state_dict(torch.load('./vgg16.pth'))
- 测试数据预测:
# 测试过程
test_correct = 0
test_total = 0
new_model.eval() # eval 评价, 评估with torch.no_grad():for x, y in test_d1:x, y = x.to(device), y.to(device)y_pred = new_model(x)y_pred = torch.argmax(y_pred, dim=1)test_correct += (y_pred == y).sum().item()test_total += y.size(0)epoch_test_acc = test_correct / test_total
print(epoch_test_acc) # 0.9644444444444444- 保存最佳参数:
model = torchvision.models.vgg16(pretrained=False)
model.classifier[-1].out_features = 4import copy
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 没有训练前的初始化参数
best_model_weight = model.state_dict()
best_acc = 0.0
train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch, model, train_d1, test_d1)train_loss.append(epoch_loss)train_acc.append(epoch_acc)test_loss.append(epoch_test_loss)test_acc.append(epoch_test_acc)if epoch_test_acc > best_acc:best_acc = epoch_test_acc# 更新参数, 保存最佳参数best_model_weight = copy.deepcopy(model.state_dict())# 把最好的参数加载到模型
model.load_state_dict(best_model_weight)- 保存完整模型: torch.save(model, './my_whole_model.pth')
- 加载完整模型: new_model2 = torch.load('./my_whole_model.pth')
跨设备保存模型及加载:
- model.load_state_dict(torch.load('./my_best_weight', map_location=device))
# 把刚才保存的模型映射到GPU
torch.save(model.state_dict(), './my_best_weight')model = torchvision.models.vgg16(pretrained=False)
model.classifier[-1].out_features = 4# 下载完模型后, 执行了model.to(device), 默认在CPU上
model.load_state_dict(torch.load('./my_best_weight', map_location=device))- 学习率衰减: step_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1) # step_lr_scheduler.step() # from torch.optim import lr_scheduler
- 数据加强处理:
# 数据增强只会加载在训练数据上, 预测数据不调整
train_transform = transforms.Compose([transforms.Resize((224, 224)), # 统一缩放到224, 224transforms.RandomCrop(192), # 随机裁剪部分transforms.RandomHorizontalFlip(), # 水平翻转transforms.RandomVerticalFlip(), # 垂直翻转transforms.RandomRotation(0.4), #随机旋转transforms.ColorJitter(brightness=0.5), # 亮度调整transforms.ColorJitter(contrast=0.5), # 对比度调整transforms.ToTensor(), # 转换为tensor# 正则化 # 数值大小调整transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])test_transform = transforms.Compose([transforms.Resize((224, 224)), # 统一缩放到224, 224transforms.ToTensor(), # 转换为tensor# 正则化 # 数值大小调整transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])一 天气图片分类
1.1 简介
数据四分类: Rain, sunshine, sunrise, cloudy.
1.2 导包
# vgg
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms1.3 导入数据
import os
base_dir = './dataset'
train_dir = os.path.join(base_dir, 'train')
test_dir = os.path.join(base_dir, 'test')- 图片数据转换方式: 图片尺寸统一, 数据转换为tensor, 数据正则化
transform = transforms.Compose([transforms.Resize((96, 96)), # 统一缩放transforms.ToTensor(), # 转换为tensor# 正则化transforms.Normalize(mean=[0.5, 0.5, 0.5],std=[0.5, 0.5, 0.5])])- 图片数据导入
train_ds = torchvision.datasets.ImageFolder(train_dir, transform=train_transform)
test_ds = torchvision.datasets.ImageFolder(test_dir, transform=test_transform)# dataloader
batch_size = 32 # batch 批次
train_d1 = torch.utils.data.DataLoader(train_ds, batch_size=batch_size,shuffle=True, drop_last=True)
test_d1 = torch.utils.data.DataLoader(test_ds, batch_size=batch_size)1.4 导入模型 (迁移学习)
# 加载预训练模型
model = torchvision.models.vgg16(pretrained=True)
model 
for param in model.features.parameters():param.requires_grad = False- 定义输出类别
# 修改结果特征, 4分类
model.classifier[-1].out_features = 4
model.classifier[-1] # Linear(in_features=4096, out_features=4, bias=True)# 另一种修改方式 # 直接替换最后一层
# model.classifier[-1] = torch.nn.Linear(model.classifier[-1], 4)- 数据拷贝到 GPU
# 训练 # 拷贝到GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model.to(device)1.5 定义训练
# 继续训练
optimizer = optim.Adam(model.parameters(), lr=0.001)
loss_fn = nn.CrossEntropyLoss()# 定义训练过程
def fit(epoch, model, train_loader, test_loader):correct = 0total = 0running_loss = 0for x, y in train_loader:x, y = x.to(device), y.to(device)y_pred = model(x)loss = loss_fn(y_pred, y)optimizer.zero_grad()loss.backward()optimizer.step()with torch.no_grad():y_pred = torch.argmax(y_pred, dim=1)correct += (y_pred == y).sum().item()total += y.size(0)running_loss += loss.item()epoch_loss = running_loss / len(train_loader.dataset)epoch_acc = correct / total# 测试过程test_correct = 0test_total = 0test_running_loss = 0with torch.no_grad():for x, y in test_loader:x, y = x.to(device), y.to(device)y_pred = model(x)loss = loss_fn(y_pred, y)y_pred = torch.argmax(y_pred, dim=1)test_correct += (y_pred == y).sum().item()test_total += y.size(0)test_running_loss += loss.item()test_epoch_loss = test_running_loss / len(test_loader.dataset)test_epoch_acc = test_correct /test_totalprint('epoch', epoch,'loss', round(epoch_loss, 3),'accuracy', round(epoch_acc, 3),'test_loss', round(test_epoch_loss, 3),'test_accuracy', round(test_epoch_acc, 3))return epoch_loss, epoch_acc, test_epoch_loss, test_epoch_acc- 指定训练
# 指定训练次数
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):epoch_loss, epoch_acc, test_epoch_loss, test_epoch_acc = fit(epoch, model,train_d1, test_d1)train_loss.append(epoch_loss)train_acc.append(epoch_acc)test_loss.append(test_epoch_loss)test_acc.append(test_epoch_acc)model.parameters # 查看模型结构
1.6 结果展示
plt.plot(range(1, epochs+1), train_loss, label='train_loss')
plt.plot(range(1, epochs+1), test_loss, label='test_loss')
plt.legend()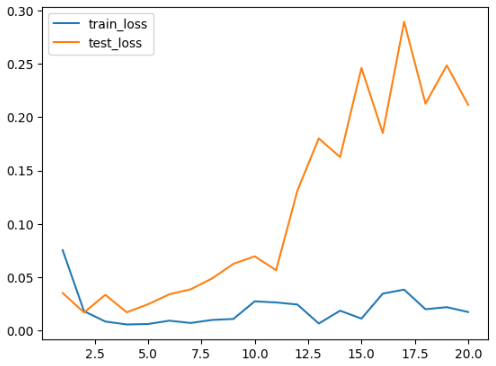
plt.plot(range(1, epochs+1), train_acc, label='train_acc')
plt.plot(range(1, epochs+1), test_acc, label='test_acc')
plt.legend()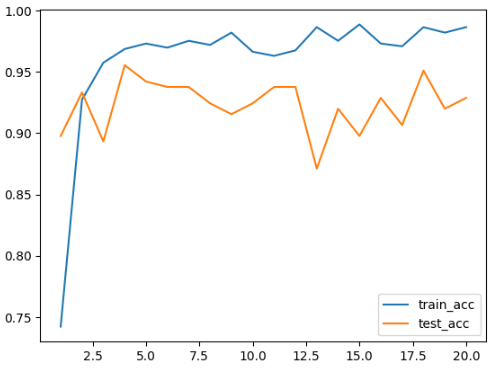
二 保存模型
2.1 保存参数
- state_dict 是一个字典, 保存了训练模型
model.state_dict() # 保存位置# 保存参数
path = './vgg16.pth'
torch.save(model.state_dict(), path)2.2 恢复模型
-
先创建模型, 然后通过模型加载参数
new_model = torchvision.models.vgg16(pretrained=False)
new_model.classifier[-1].out_features = 4# 传参
new_model.load_state_dict(torch.load('./vgg16.pth'))
new_model.state_dict() # 保存位置2.3 模型预测
# 把模型拷贝到数据所在的位置(GPU/ CPU)
new_model.to(device)# 测试过程
test_correct = 0
test_total = 0
new_model.eval() # eval 评价, 评估with torch.no_grad():for x, y in test_d1:x, y = x.to(device), y.to(device)y_pred = new_model(x)y_pred = torch.argmax(y_pred, dim=1)test_correct += (y_pred == y).sum().item()test_total += y.size(0)epoch_test_acc = test_correct / test_total
print(epoch_test_acc) # 0.96444444444444442.4 保存参数最佳的模型
model = torchvision.models.vgg16(pretrained=False)
model.classifier[-1].out_features = 4# 传参
# model.load_state_dict(torch.load('./vgg16.pth'))import copy
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 没有训练前的初始化参数
best_model_weight = model.state_dict()
best_acc = 0.0
train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch, model, train_d1, test_d1)train_loss.append(epoch_loss)train_acc.append(epoch_acc)test_loss.append(epoch_test_loss)test_acc.append(epoch_test_acc)if epoch_test_acc > best_acc:best_acc = epoch_test_acc# 更新参数, 保存最佳参数best_model_weight = copy.deepcopy(model.state_dict())
- 加载最佳参数模型
# 把最好的参数加载到模型
model.load_state_dict(best_model_weight)2.5 保存完整模型和参数
- 保存模型参数
torch.save(model, './my_whole_model.pth')- 加载模型及参数
new_model2 = torch.load('./my_whole_model.pth')
# 查看保存参数
new_model2.state_dict()
new_model2
2.6 跨设备的模型保存和加载
# GPU和cpu
device # device(type='cpu')- 把刚才保存的模型映射到GPU
# 把刚才保存的模型映射到GPU
torch.save(model.state_dict(), './my_best_weight') # 保存参数model = torchvision.models.vgg16(pretrained=False)
model.classifier[-1].out_features = 4# 下载完模型后, 执行了model.to(device), 默认在CPU上
model.load_state_dict(torch.load('./my_best_weight', map_location=device))三 学习率衰减
3.1 导入模型
# 加载预训练模型
model = torchvision.models.vgg16(pretrained=True)for param in model.features.parameters():param.requires_grad = False# 修改结果特征, 4分类
model.classifier[-1].out_features = 4# 拷贝到GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model.to(device)# 继续训练
optimizer = optim.Adam(model.parameters(), lr=0.001)
loss_fn = nn.CrossEntropyLoss()3.2 学习率衰减
from torch.optim import lr_scheduler# 学习率衰减
step_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
- 模型训练
# 定义训练过程
def fit(epoch, model, train_loader, test_loader):correct = 0total = 0running_loss = 0for x, y in train_loader:x, y = x.to(device), y.to(device)y_pred = model(x)loss = loss_fn(y_pred, y)optimizer.zero_grad()loss.backward()optimizer.step()with torch.no_grad():y_pred = torch.argmax(y_pred, dim=1)correct += (y_pred == y).sum().item()total += y.size(0)running_loss += loss.item()# 衰减学习率step_lr_scheduler.step()epoch_loss = running_loss / len(train_loader.dataset)epoch_acc = correct / total# 测试过程test_correct = 0test_total = 0test_running_loss = 0with torch.no_grad():for x, y in test_loader:x, y = x.to(device), y.to(device)y_pred = model(x)loss = loss_fn(y_pred, y)y_pred = torch.argmax(y_pred, dim=1)test_correct += (y_pred == y).sum().item()test_total += y.size(0)test_running_loss += loss.item()test_epoch_loss = test_running_loss / len(test_loader.dataset)test_epoch_acc = test_correct /test_totalprint('epoch', epoch,'loss', round(epoch_loss, 3),'accuracy', round(epoch_acc, 3),'test_loss', round(test_epoch_loss, 3),'test_accuracy', round(test_epoch_acc, 3))return epoch_loss, epoch_acc, test_epoch_loss, test_epoch_acc# 指定训练次数
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):epoch_loss, epoch_acc, test_epoch_loss, test_epoch_acc = fit(epoch, model, train_d1, test_d1)train_loss.append(epoch_loss)train_acc.append(epoch_acc)test_loss.append(test_epoch_loss)test_acc.append(test_epoch_acc)
四 数据增强
4.1 数据输入
数据增强
- transforms.RandomCrop # 随机位置裁剪
- transforms.RandomRotation # 随机旋转
- transforms.RandomHorizontalFlip # 水平翻转
- transforms.RandomVerticalFlip # 垂直翻转
- transforms.ColorJitter(brightness) # 亮度
- transforms.ColorJitter(contrast) # 对比度
- transforms.ColorJitter(saturation) # 饱和度
- transforms.ColorJitter(hue) # 色调
- transforms.RandomGrayscale # 随机灰度化
import os
base_dir = './dataset'
train_dir = os.path.join(base_dir, 'train')
test_dir = os.path.join(base_dir, 'test')# 数据增强只会加载在训练数据上, 预测数据不调整
train_transform = transforms.Compose([transforms.Resize((224, 224)), # 统一缩放到224, 224transforms.RandomCrop(192), # 随机裁剪部分transforms.RandomHorizontalFlip(), # 水平翻转transforms.RandomVerticalFlip(), # 垂直翻转transforms.RandomRotation(0.4), #随机旋转transforms.ColorJitter(brightness=0.5), # 亮度调整transforms.ColorJitter(contrast=0.5), # 对比度调整transforms.ToTensor(), # 转换为tensor# 正则化 # 数值大小调整transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])test_transform = transforms.Compose([transforms.Resize((224, 224)), # 统一缩放到224, 224transforms.ToTensor(), # 转换为tensor# 正则化 # 数值大小调整transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])train_ds = torchvision.datasets.ImageFolder(train_dir, transform=train_transform)
test_ds = torchvision.datasets.ImageFolder(test_dir, transform=test_transform)# dataloader
batch_size = 32 # batch 批次
train_d1 = torch.utils.data.DataLoader(train_ds, batch_size=batch_size,shuffle=True, drop_last=True)
test_d1 = torch.utils.data.DataLoader(test_ds, batch_size=batch_size)4.2 减弱数据增强
# 数据增强只会加载在训练数据上, 预测数据不调整
train_transform = transforms.Compose([transforms.Resize((224, 224)), # 统一缩放到224, 224transforms.RandomCrop(192), # 随机裁剪部分transforms.RandomHorizontalFlip(), # 水平翻转transforms.RandomVerticalFlip(), # 垂直翻转transforms.RandomRotation(0.4), #随机旋转# transforms.ColorJitter(brightness=0.5), # 亮度调整# transforms.ColorJitter(contrast=0.5), # 对比度调整transforms.ToTensor(), # 转换为tensor# 正则化 # 数值大小调整transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])test_transform = transforms.Compose([transforms.Resize((224, 224)), # 统一缩放到224, 224transforms.ToTensor(), # 转换为tensor# 正则化 # 数值大小调整transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])相关内容
热门资讯
Linux-scheduler...
四、调度域 SDTL结构 linux内核使用SDTL结构体来组织CPU的层次关系 struct sc...
leetcode - 2379...
Description You are given a 0-indexed string block...
Retinanet网络与foc...
参考代码:https://github.com/yhenon/pytorch-reti...