M2E2: Cross-media Structured Common Space for Multimedia Event Extraction 论文解读
Cross-media Structured Common Space for Multimedia Event Extraction
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GZKTbcVF-1678195122476)(Cross-media Structured Common Space for Multimedia Event Extraction.assets/image-20230307140028162.png)]](https://img-blog.csdnimg.cn/a5dd0713101a428caa59b09fb7b1f27e.png#pic_center)
论文:multimediaspace2020.pdf (illinois.edu)
代码:limanling/m2e2: Cross-media Structured Common Space for Multimedia Event Extraction (ACL2020) (github.com)
期刊/会议:ACL 2020
摘要
我们介绍了一个新的任务,多媒体事件抽取(M2E2),旨在从多媒体文档中抽取事件及其参数。我们开发了第一个基准测试,并收集了245篇多媒体新闻文章的数据集,其中包含大量标注的事件和论点。我们提出了一种新的方法,弱对齐结构化嵌入(Weakly Aligned Structured Embedding, WASE),它将语义信息的结构化表示从文本和视觉数据编码到一个公共的嵌入空间。通过采用弱监督训练策略,使结构在不同模式之间保持一致,从而可以在没有显式跨媒体标注的情况下利用可用资源。与最先进的单模态方法相比,我们的方法在文本事件论元角色标记和视觉事件抽取方面获得了4.0%和9.8%的绝对F-score增益。与最先进的多媒体非结构化表示相比,我们在多媒体事件抽取和论元角色标记方面分别获得了8.3%和5.0%的绝对F-score增益。通过使用图像,我们比传统的纯文本方法多抽取21.4%的事件提及。
1、简介
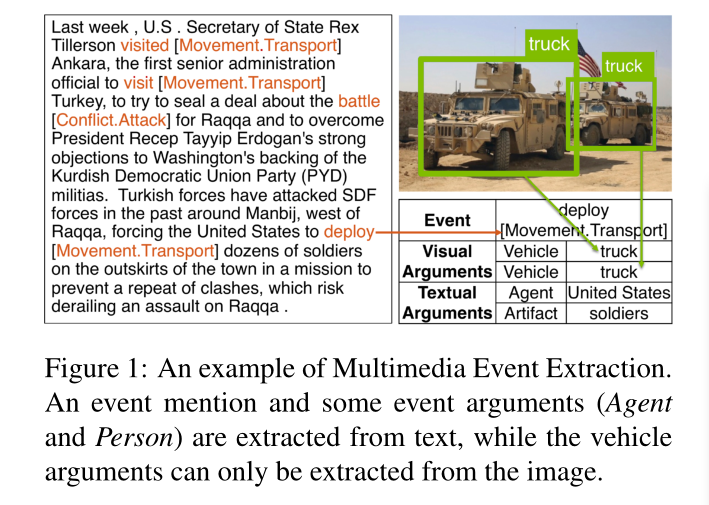
传统的事件抽取方法针对单一的模态,如文本(Wadden et al, 2019)、图像(Yatskar et al, 2016)或视频(Ye et al, 2015;Caba Heilbron et al, 2015;Soomro等人,2012)。然而,当代新闻的实践(Stephens, 1998)通过多媒体传播新闻。通过从美国之音(VOA)中随机抽取100篇多媒体新闻文章,我们发现文章中33%的图像包含作为事件论元的视觉对象,而文本中没有提及。以图1为例,我们可以从文本中抽取Movement.Transport事件的Agent和Person论元,但只能从图像中抽取Vehicle论元。然而,事件抽取在计算机视觉(CV)和自然语言处理(NLP)中是独立研究的,在任务定义、数据领域、方法和术语方面存在重大差异。基于多媒体数据的互补性和整体性,我们提出了多媒体事件抽取(M2E2),这是一项旨在从多种模式中联合抽取事件论元的新任务。我们为此任务构建了第一个基准测试和评估数据集,其中包括245篇完全标注的新闻文章。
我们提出了第一种方法,弱对齐结构化嵌入(WASE),用于从多种模式中抽取事件和论元。现有的多媒体表示方法还没有涵盖复杂的事件结构(Wu等人,2019b;法格里等人,2018;Karpathy and Fei-Fei, 2015),因此我们提出学习一个结构化的多媒体嵌入空间。更具体地说,给定一个多媒体文档,我们将每个图像或句子表示为一个图,其中每个节点表示一个事件或实体,每条边表示一个论元角色。节点和边缘嵌入在多媒体公共语义空间中表示,因为它们被训练来解决跨模式的事件共同引用,并将图像与相关句子匹配。这使我们能够联合分类来自两种模式的事件和论元角色。一个主要的挑战是缺乏多媒体事件参数标注,由于标注的复杂性,获取这些标注的成本很高。因此,我们提出了一个弱监督框架,该框架利用带标注的单模态语料库分别学习视觉和文本事件抽取,并使用图像字幕数据集来对齐模式。
我们对M2E2新任务的WASE进行了评估。与最先进的单模态方法和多媒体平面表示相比,我们的方法在所有设置下都显著优于事件抽取和论元角色标记任务。此外,它抽取的事件提及量比纯文本基线多21.4%。训练和评估是在来自多个来源、领域和数据模式的异构数据集上完成的,展示了所提出模型的可伸缩性和可移植性。综上所述,本文做出了以下贡献:
- 我们提出了一个新任务,多媒体事件抽取,并构建了第一个带标注的新闻数据集作为基准,以支持跨媒体事件的深度分析。
- 我们开发了一个弱监督训练框架,利用现有的单模态标注语料库,并在没有跨模态标注的情况下实现联合推理。
- 我们提出的方法WASE是第一个利用结构化表示和基于图的神经网络进行多媒体公共空间嵌入的方法。
2、任务定义
2.1 问题描述
每个输入文档由一组图像M={m1,m2,…}\mathcal{M} = \{m_1, m_2,\ldots \}M={m1,m2,…}和一组句子S={s1,s2,…}\mathcal{S} = \{s_1, s_2,\ldots\}S={s1,s2,…}。每个句子sss可以表示为一个符号序列s=(w1,w2,…)s = (w_1, w_2,\ldots)s=(w1,w2,…),其中wiw_iwi是来自文档词汇表www的一个token。输入还包括一组实体T={t1,t2,…}\mathcal{T} = \{t_1, t_2,\ldots\}T={t1,t2,…}从文档文本中抽取。实体是现实世界中单独的唯一对象,例如人、组织、设施、位置、地缘政治实体、武器或交通工具。M2E2的目标有两个:
事件抽取:给定一个多媒体文档,抽取一组事件提及,其中每个事件提及eee的类型为yey_eye,并且基于文本触发词www或图像mmm或两者兼有,
e=(ye,{w,m})e=(y_e,\{ w,m \}) e=(ye,{w,m})
注意,对于一个事件,www和mmm可以同时存在,这意味着可视事件提到和文本事件提到指向同一个事件。例如,在图1中,deploy表示相同的Movement.Transport事件作为图像。如果事件eee只包含文本提及www,则将其视为纯文本事件;如果事件eee只包含视觉提及mmm,则将其视为纯图像事件;如果事件www和mmm同时存在,则将其视为多媒体事件。
论元抽取:第二项任务是抽取事件提及eee的一组论元。每个论元aaa都有一个论元角色类型yay_aya,并且基于一个文本实体ttt或一个图像对象ooo(表示为边界框),或两者兼有,
a=(ya,{t,o})a=(y_a,\{t,o\}) a=(ya,{t,o})
如果视觉事件和文本事件提到的论元指向同一个现实世界事件,那么它们将被合并,如图1所示。
2.2 M2E2数据集
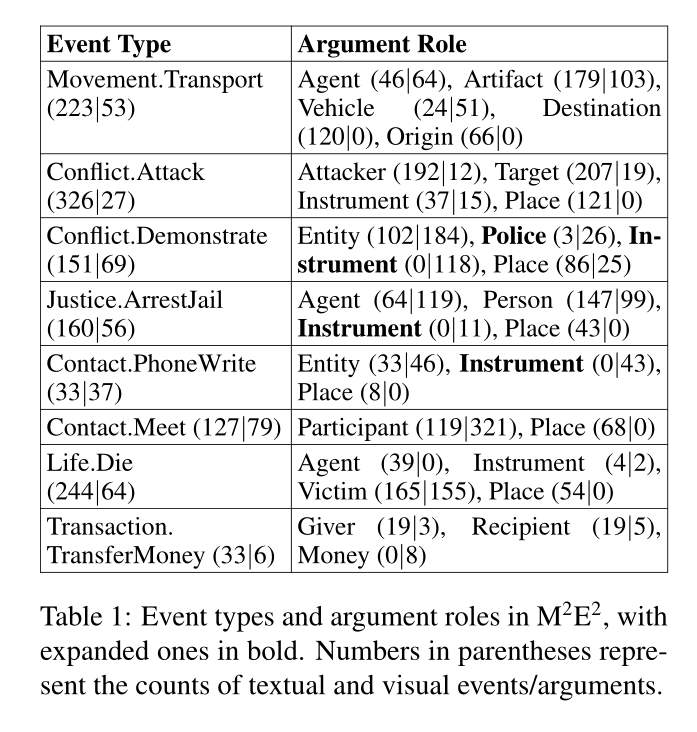
我们通过在新闻领域(ACE2)的NLP社区中的事件本体和通用领域(imSitu (Yatskar et al, 2016)的CV社区中的事件本体之间的所有映射来定义多媒体新闻价值事件类型。它们涵盖了每个社区最大的训练资源。表1显示了所选择的完整交集,其中包含8种ACE类型(即所有ACE类型的24%),映射到98种imSitu类型(即所有imSitu类型的20%)。我们通过添加来自imSitu的可视化论元来扩展ACE事件角色集,例如表1中粗体显示的instrument。该集合包含新闻语料库中52%的ACE事件,这表明所选的8种类型在新闻域中是显著的。我们重用这些现有的本体,因为它们使我们能够为两种模式训练事件和论元分类器,而不需要联合多媒体事件论元作为训练数据。
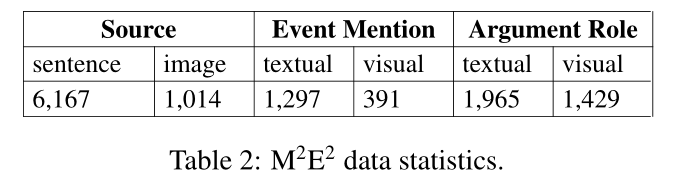
我们从美国之音(VOA)网站2006-2017年收集了108,693篇多媒体新闻,涵盖了军事、经济、健康等广泛的有新闻价值的话题。我们选取245篇文献作为标注集,依据三个标准:(1)信息量:事件提及次数较多的文章;(2)插画:图片较多的文章(> 4);(3)多样性:不考虑真实频率而平衡事件类型分布的文章。数据统计如表2所示。在所有这些事件中,192个文本事件提及和203个视觉事件提及可以对齐为309个跨媒体事件提及对。该数据集可以分为1105个纯文本事件提及,188个纯图像事件提及和395个多媒体事件提及。
我们遵循ACE事件标注指南(Walker et al, 2006)用于文本事件和论元标注,并设计了用于多媒体事件标注的标注指南。
多媒体事件标注中一个独特的挑战是在复杂场景中本地化可视论元,其中图像包括一群人或一组物体。这很难使用一个标注框去区分它们每一个。为了解决这个问题,我们定义了两种类型的边界框:(1)联合边界框:对于每个角色,我们标注涵盖所有成分的最小边界框;和(2)实例边界框:对于每个角色,我们标注了一组边界框,其中每个框是覆盖单个参与者(例如,人群中的一个人)的最小区域,遵循VOC2011标注指南。图2显示了一个示例。8名NLP和CV研究人员以两次独立通过的方式完成了标注工作,并达成了81.2%的Inter-Annotator Agreement (IAA)。两名专家标注员执行裁决。

3、方法
3.1 方法总览
如图3所示,训练阶段包含三个任务:文本事件抽取(章节3.2)、视觉情境识别(章节3.3)和跨媒体对齐(章节3.4)。我们学习了一个跨媒体共享编码器,一个共享事件分类器和一个共享论元分类器。在测试阶段(章节3.5),给定一篇多媒体新闻文章,我们将句子和图像编码到结构化的公共空间中,并联合抽取文本和视觉事件和论元,然后进行跨模态共指解析。

3.2 文本事件抽取
文本结构表征:如图4所示,我们选择抽象语义表示(AMR) (Banarescu et al, 2013)来表示文本,因为它包含丰富的150个细粒度语义角色集。为了对每个文本句子进行编码,我们运行CAMR解析器(Wang等人,2015b,a, 2016),基于斯坦福CoreNLP的命名实体识别和词性(POS)标注结果生成AMR图(Manning等人,2014)。为了表示句子sss中的每个单词www,我们连接它的预训练Glove字嵌入,POS嵌入,实体类型嵌入和位置嵌入。然后,我们将单词序列输入到双向长短期记忆(Bi-LSTM) (Graves等人,2013)网络中,对词序进行编码,并得到每个单词www的表示。给定AMR图,我们应用图卷积网络(GCN) (Kipf和Welling, 2016)对以下图上下文信息进行编码(Liu等人,2018a):
wi(k+1)=f(∑j∈N(i)gij(k)(WE(i,j)wj(k)+bE(i,j)(k)))w_i^{(k+1)}=f(\sum_{j \in \mathcal{N}(i)} g_{ij}^{(k)} (W_{E(i,j)} w_j^{(k)} +b_{E(i,j)}^{(k)})) wi(k+1)=f(j∈N(i)∑gij(k)(WE(i,j)wj(k)+bE(i,j)(k)))
其中N(i)\mathcal{N}(i)N(i)为AMR图中wiw_iwi的邻居节点,E(i,j)E(i, j)E(i,j)为wiw_iwi与wjw_jwj之间的边类型,gijg_{ij}gij为gate following(Liu et al, 2018a), kkk为GCN层数,fff为Sigmoid函数。WWW和bbb表示本文神经层的参数。我们将每个单词的最后一个GCN层的隐藏状态作为公共空间表示wCw^CwC,其中CCC代表公共(多媒体)嵌入空间。对于每个实体ttt,我们通过求其token嵌入的平均值来获得其表示tCt^CtC。
事件和论元分类器:我们将每个单词www分类为事件类型yey_eye,将每一个实体分类为论元。
P(ye∣w)=exp(WewC+be)∑e′exp(We′wC+be′),P(ya∣t)=exp(Wa[tC;wC]+ba)∑a′exp(Wa′[tC;wC]+ba′)P(y_e|w)=\frac{\exp(W_e w^C +b_e)}{\sum_{{e'}}\exp(W_{e'} w^C +b_{e'})},\\ P(y_a|t)=\frac{\exp(W_a [t^C;w^C] +b_a)}{\sum_{{a'}}\exp(W_{a'} [t^C;w^C] +b_{a'})} P(ye∣w)=∑e′exp(We′wC+be′)exp(WewC+be),P(ya∣t)=∑a′exp(Wa′[tC;wC]+ba′)exp(Wa[tC;wC]+ba)
我们在训练期间将ground truth文本实体提及作为输入(Ji和grihman, 2008),并使用命名实体抽取器获得测试实体提及(Lin等人,2019)。
3.3 图像事件抽取
图像结构表征:获得图像的结构类似于AMR图表,灵感来自场景识别(Yatskar等,2016),我们代表每个图像场景图,这是一个星形图如图4所示,在中央节点标记为一个动词vvv(例如,destroying),和你的邻居节点论元标记为{(n,r)}\{(n, r)\}{(n,r)},其中nnn是一个名词(例如,ship)源自WordNet同义词集(米勒,1995)来表示实体类型,和rrr表示角色(例如,item)由事件中的实体播放,基于FrameNet(Fillmore et al, 2003)。我们开发了两种方法来从图像中构建情况图,并使用imSitu数据集(Yatskar et al, 2016)进行训练,如下所示。

(1)基于目标的图:类似于抽取实体以获取候选论元,我们利用最相似的CV任务,目标检测,并获得由在开放图像(Kuznetsova et al, 2018)上训练的具有600种对象类型(类)的Faster R-CNN (Ren et al, 2015)模型检测到的对象边界框。我们使用VGG-16 CNN (Simonyan and Zisserman, 2014)抽取图像mmm的视觉特征,并使用另一个VGG-16边界框{oi}\{o_i\}{oi}进行编码。然后,我们应用多层感知器(MLP)来预测mmm的动词嵌入,并应用另一个MLP来预测每个oio_ioi的名词嵌入。
m^=MLPm(m),o^i=MLPo(oi)\hat m=\text{MLP}_m(m),\hat o_i =\text{MLP}_o (o_i) m^=MLPm(m),o^i=MLPo(oi)
我们将预测的动词嵌入与imSitu分类法中的所有动词vvv进行比较,以便对动词进行分类,并类似地将每个预测的名词嵌入与所有imSitu名词nnn进行比较,从而得出概率分布:
P(v∣m)=exp(m^v)∑v′exp(m^,v′),P(n∣oi)=exp(o^in)∑n′exp(o^in′),P(v|m)=\frac{\exp(\hat m v)}{\sum_{v'}\exp(\hat m,v')},\\ P(n|o_i)=\frac{\exp(\hat o_i n)}{\sum_{n'}\exp(\hat o_i n')}, P(v∣m)=∑v′exp(m^,v′)exp(m^v),P(n∣oi)=∑n′exp(o^in′)exp(o^in),
其中vvv和nnn是用GloVE初始化的词嵌入(Pennington et al, 2014)。我们使用另一个带有一个隐藏层的MLP,后面跟着Softmax(σ)来对每个对象oio_ioi的角色rir_iri进行分类:
P(ri∣oi)=σ(MLPr(o^i))P(r_i|o_i)=\sigma(\text{MLP}_r(\hat o_i)) P(ri∣oi)=σ(MLPr(o^i))
给定一幅图像(来自imSitu语料库)的动词v∗v^∗v∗和角色-名词(ri∗,ni∗r^∗_i, n^∗_iri∗,ni∗)标注,定义场景损失函数:
Lv=−logP(v∗∣m),Lr=−log(P(ri∗∣oi)+P(ni∗∣oi))L_v=-\log P(v^*|m),\\ L_r=-\log(P(r_i^*|o_i)+P(n_i^*|o_i)) Lv=−logP(v∗∣m),Lr=−log(P(ri∗∣oi)+P(ni∗∣oi))
(2)基于注意力的图:最先进的对象检测方法只覆盖有限的对象类型集,例如Open Images中定义的600种类型。许多突出的物体,如炸弹、石头和担架,都没有包括在这些本体中。因此,我们提出了一种开放词汇表来替代基于对象的图构造模型。为此,我们构建了一个角色驱动的注意力图,其中每个论元节点由一个以角色rrr为条件的空间分布注意力(热图)派生。更具体地说,我们使用VGG-16 CNN为每个图像mmm抽取7×7卷积特征图,可视为7×7局部区域的注意力的key kik_iki。接下来,对于情景识别本体中定义的每个角色rrr(例如agent),我们将角色嵌入rrr与图像特征mmm串联起来作为上下文,构建注意力查询向量qrq_rqr,并应用一个全连接层:
qr=Wq[r;m]+bqq_r=W_q[r;m]+b_q qr=Wq[r;m]+bq
然后,我们计算每个查询向量与所有键向量的点积,然后使用Softmax,在图像上形成热图hhh,即:
hi=exp(qrki)∑j∈7×7exp(qrkj)h_i=\frac{\exp(q_rk_i)}{\sum_{j \in 7 \times 7} \exp(q_r k_j)} hi=∑j∈7×7exp(qrkj)exp(qrki)
我们使用热图来获得特征图的加权平均值,以表示论元oro_ror在视觉空间中每个角色rrr:
or=∑ihimio_r=\sum_ih_im_i or=i∑himi
与基于对象的模型类似,我们将或oro_ror嵌入到o^r\hat o_ro^r中,并将其与imSitu名词嵌入进行比较,以定义一个分布,并定义一个分类损失函数。以与基于对象的方法相同的方式定义动词嵌入m^\hat mm^和动词预测概率P(v∣m)P(v|m)P(v∣m)和损失。
事件和触发词分类:我们使用基于对象或基于注意力的公式,并在imSitu数据集上对其进行预训练(Yatskar等人,2016)。然后,我们应用GCN来获得公共空间中每个节点的结构化嵌入,类似于等式3。这产生mCm^CmC和oiCo^C_ioiC。我们使用等式4中定义的相同分类器,使用公共空间嵌入对每个视觉事件和论元进行分类:
P(ye∣w)=exp(WewC+be)∑e′exp(We′wC+be′),P(ya∣o)=exp(Wa[oC;wC]+ba)∑a′exp(Wa′[oC;wC]+ba′)P(y_e|w)=\frac{\exp(W_e w^C +b_e)}{\sum_{{e'}}\exp(W_{e'} w^C +b_{e'})},\\ P(y_a|o)=\frac{\exp(W_a [o^C;w^C] +b_a)}{\sum_{{a'}}\exp(W_{a'} [o^C;w^C] +b_{a'})} P(ye∣w)=∑e′exp(We′wC+be′)exp(WewC+be),P(ya∣o)=∑a′exp(Wa′[oC;wC]+ba′)exp(Wa[oC;wC]+ba)
3.4 跨媒体联合训练
为了使事件和论元分类器在模态之间共享,图像和文本图应编码到相同的空间。然而,获取并行文本和图像事件标注的成本极高。因此,我们在单独的模态(即ACE和imSitu数据集)中使用事件和参数标注来训练分类器,同时使用VOA新闻图像和字幕对来对齐两种模态。为此,我们学习将每个图像图的节点嵌入到对应字幕图的节点附近,而远离无关字幕图中的节点。由于图像节点和字幕节点之间没有基本的真值对齐,我们使用图像和字幕对进行弱监督训练,以学习每个单词到图像对象的软对齐,反之亦然。
αij=exp(wiCojc)∑j′(wiCoj′C),βji=exp(wiCojc)∑j′(wi′CojC)\alpha_{ij}=\frac{\exp (w_i^C o_j^c)}{\sum _{j'} (w_i^C o_{j'}^C)}, \beta_{ji}=\frac{\exp (w_i^C o_j^c)}{\sum _{j'} (w_{i'}^C o_{j}^C)} αij=∑j′(wiCoj′C)exp(wiCojc),βji=∑j′(wi′CojC)exp(wiCojc)
其中wiw_iwi表示字幕句子sss中的第iii个单词,ojo_joj表示图像mmm的第jjj个对象。然后,我们计算其他模态中每个节点的软对齐节点的加权平均值,
wi′=∑jαijojC,oj′=∑iαjiwiC,w_i'=\sum_{j} \alpha_{ij}o_j^C,o_j'=\sum_{i} \alpha_{ji}w_i^C, wi′=j∑αijojC,oj′=i∑αjiwiC,
我们将图像字幕对的对齐成本定义为每个节点与其对齐表示之间的欧几里德距离,
我们使用三元组丢失来拉近相关的图像字幕对,同时将不相关的图像字幕对分开:
Lc=max(0,1+
其中m−m^−m−是不匹配sss的随机采样负图像。请注意,为了学习图像和触发词之间的对齐,我们在学习跨媒体对齐时将图像视为特殊对象。
公共空间使事件和论元分类器能够在模态之间共享权重,并通过最小化以下目标函数在ACE和imSitu数据集上联合训练:
Le=−∑wlogP(ye∣w)−∑mlogP(ye∣m),La=−∑tlogP(ya∣t)−∑ologP(ya∣o)L_e=-\sum_w \log P(y_e|w) - \sum_{m}\log P(y_e|m),\\ L_a=-\sum_t \log P(y_a|t) - \sum_{o}\log P(y_a|o) Le=−w∑logP(ye∣w)−m∑logP(ye∣m),La=−t∑logP(ya∣t)−o∑logP(ya∣o)
所有的任务损失为:
L=Lv+Lr+Le+La+LcL=L_v+L_r+L_e+L_a+L_c L=Lv+Lr+Le+La+Lc
3.5 跨媒体联合推理
在测试阶段,我们的方法采用一个多媒体文档,其中句子S={s1,s2,…}S=\{s_1,s_2,\ldots\}S={s1,s2,…},图像M={m1,m2,…}M=\{m_1,m_2,\ldots\}M={m1,m2,…}作为输入。我们首先为每个句子和每个图像生成结构化公共嵌入,然后计算成对相似度
wi′′=(1−γ)wi+γwi′w_i^{''}=(1-\gamma)w_i +\gamma w_i^{'} wi′′=(1−γ)wi+γwi′
γ=exp(−
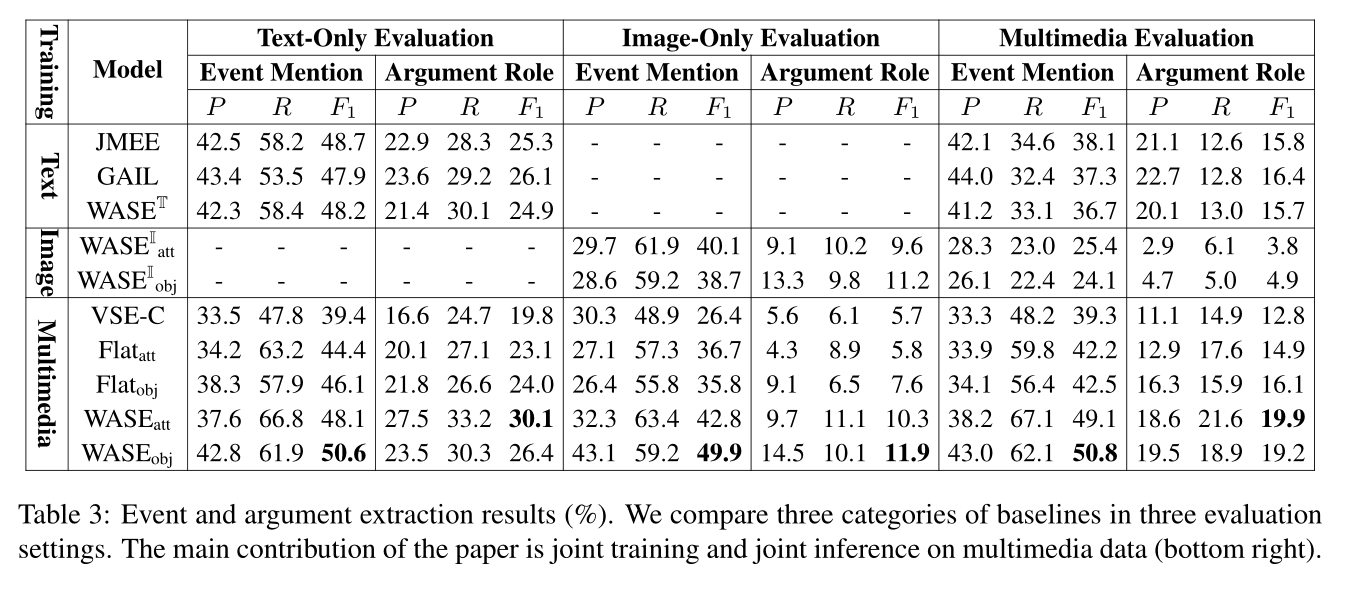
4、实验
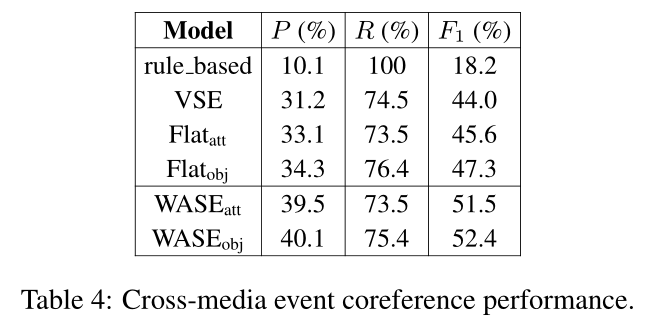


6、总结和相关工作
在本文中,我们提出了一个多媒体事件抽取的新任务,并建立了一个新的基准。我们还开发了一种新的多媒体结构化公共空间构建方法,以利用现有的图像字幕对和单模标注数据进行弱监督训练。实验证明,它是多媒体数据中事件语义理解的一个新步骤。未来,我们的目标是扩展我们的框架,从视频中抽取事件,并使其可扩展到新的事件类型。我们计划通过包括其他文本事件本体中的事件类型以及现有文本本体中没有的新事件类型来扩展标注。我们还将把我们的抽取结果应用于下游应用程序,包括跨媒体事件推断、时间线生成等。