category排序专辑
迪丽瓦拉
2024-05-30 03:28:48
0次
case1——对有限类型的字段按指定要求排序:
#学历分布
xueli_ts=df.pivot_table(index='学历',values='教师id',aggfunc='count',margins=True,margins_name='总计')
xueli_ts['占比']=np.round(xueli_ts['教师id']/xueli_ts.loc['总计','教师id'],2)
xueli_ts.reset_index(inplace=True)xueli_ts['学历']=xueli_ts['学历'].astype('category')list_xueli=['未知','专科','本科','硕士','博士','总计']
xueli_ts['学历'].cat.reorder_categories(list_xueli,inplace=True)
xueli_ts.sort_values('学历',inplace=True)
xueli_ts.set_index('学历',inplace=True)
print(xueli_ts)输出结果为:

- reorder_catgories()方法使用时要求新的categories和dataframe中的categories的元素个数和内容必须一致,只是顺序不同。
case2——若指定的list所包含元素比Dataframe中需要排序的列的元素多,怎么办?
可以使用 set_categories()方法来实现。新的list可以比dataframe中元素多。

case3——若指定的list所包含元素比Dataframe中需要排序的列的元素少,怎么办?
- 这种情况下,set_categories()方法还是可以使用的,只是没有的元素会以NaN表示
注意下面的list中没有元素“b”
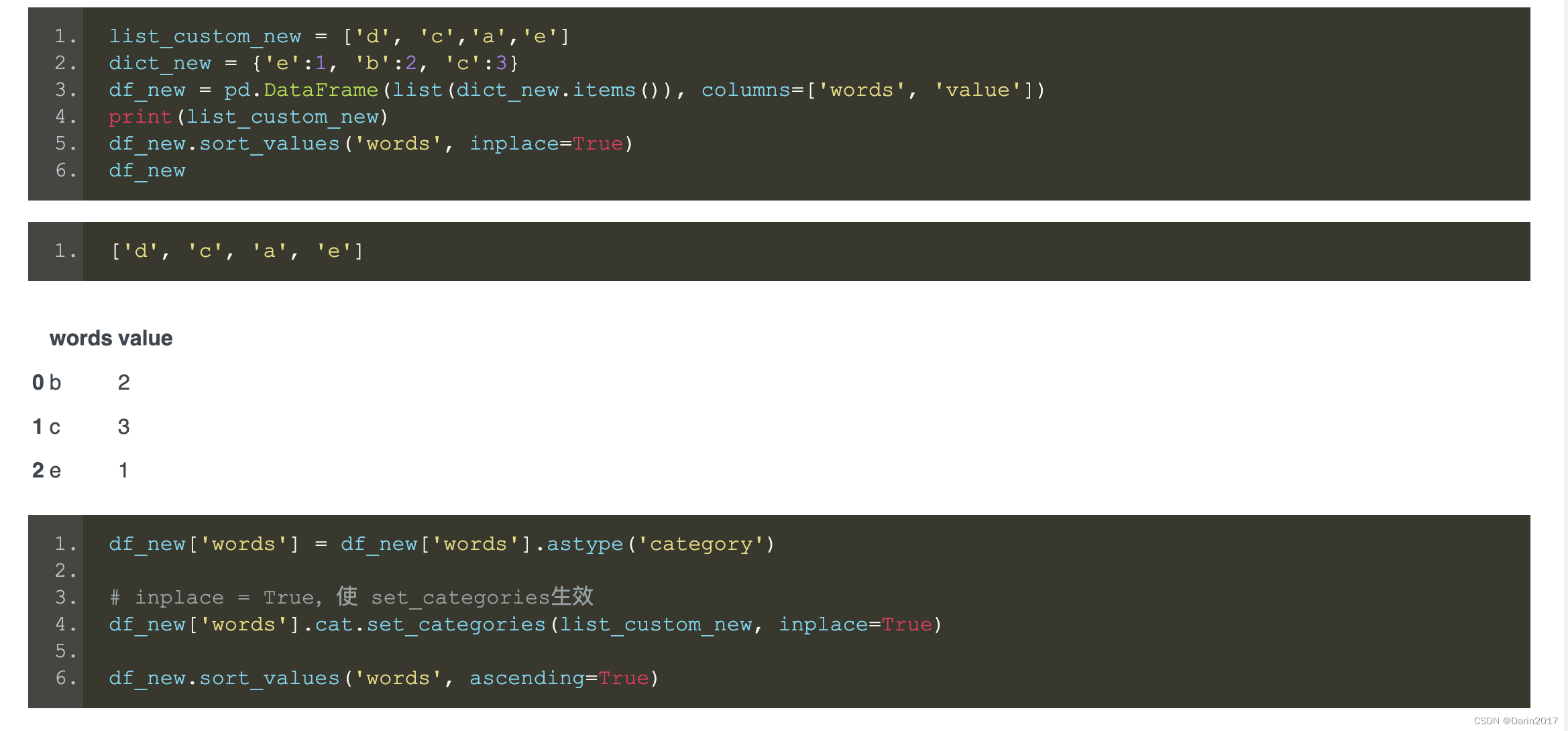

总结
根据指定的list所包含元素比Dataframe中需要排序的列的元素的多或少,可以分为三种情况:
- 相等的情况下,可以使用 reorder_categories和 set_categories方法;
- list的元素比较多的情况下, 可以使用set_categories方法;
- list的元素比较少的情况下, 也可以使用set_categories方法,但list中没有的元素会在DataFrame中以NaN表示。
相关内容
热门资讯
Linux-scheduler...
四、调度域 SDTL结构 linux内核使用SDTL结构体来组织CPU的层次关系 struct sc...
leetcode - 2379...
Description You are given a 0-indexed string block...
Retinanet网络与foc...
参考代码:https://github.com/yhenon/pytorch-reti...