厦大纪老师chatgpt相关讲座3.7
在线更新数据,迭代学习训练,进而提高模型性能。
比较明显的是API部分,这一步学习的就是intruction,实现人机写作的复杂系统工程

数据充足,维基类似于百度百科
transformer结构更有优势,预测下一个字,模型越大,则condition的range大。
模型遗忘是当模型做一个新任务时,就会忘记旧的任务,而模型足够大,就不会发生这种作用。
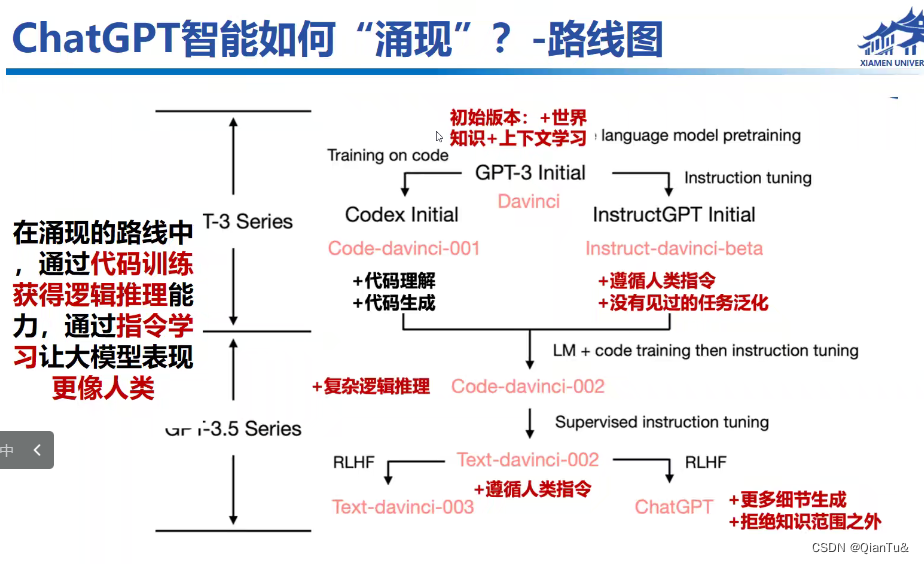
大的数据+大的模型——chatgpt

**
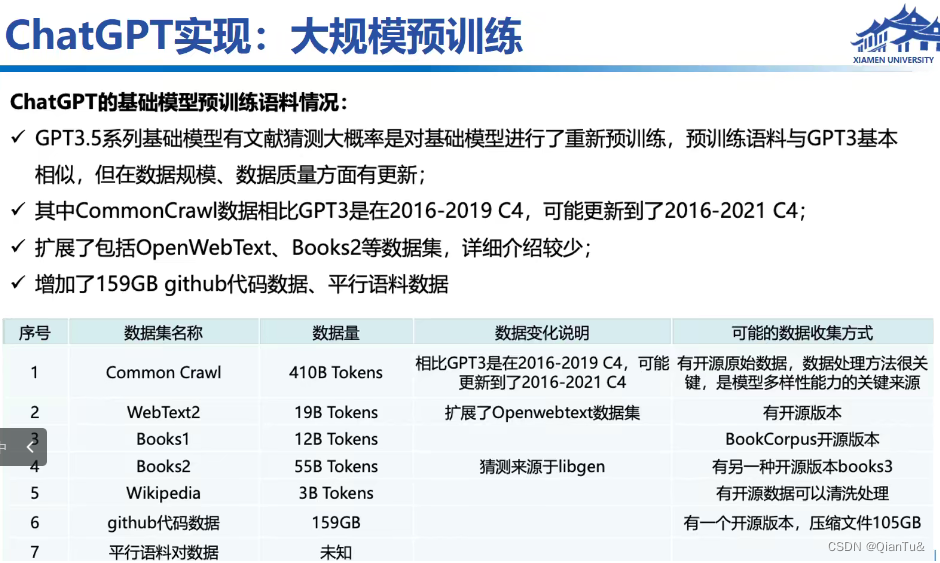
下图中的数据,多为猜测。
数据的搜集过程,无法复制?
论文中给出了标注数据集类型,有QA等等,需要给出提示
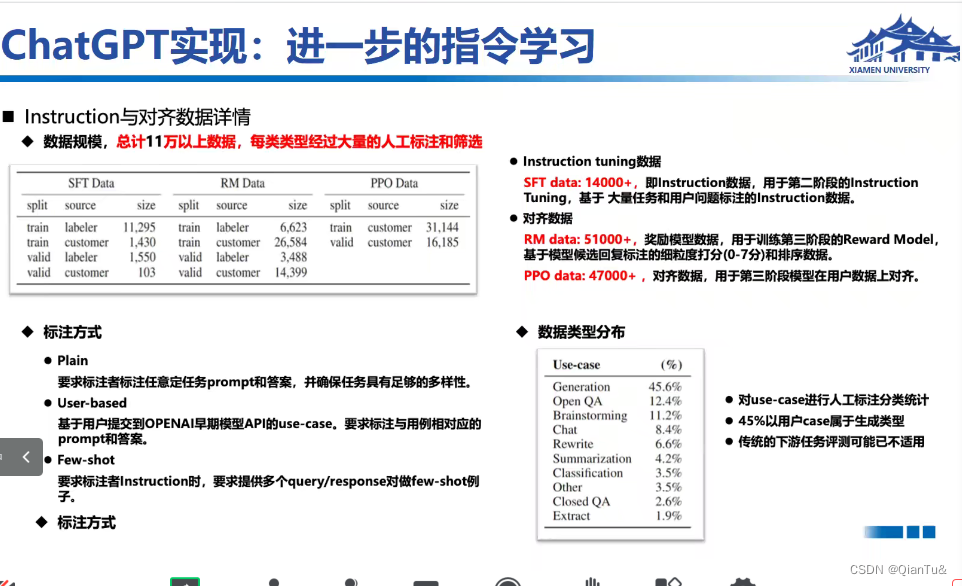


不仅给出了答案,还给出推理chain。
无监督预训练:文本语料570g,代码:159g
有监督:12万个训练集,1653个测试集,集合的意思,不是数据集量

2、国产大模型硬件基础
不大指望企业,指望国家实验室
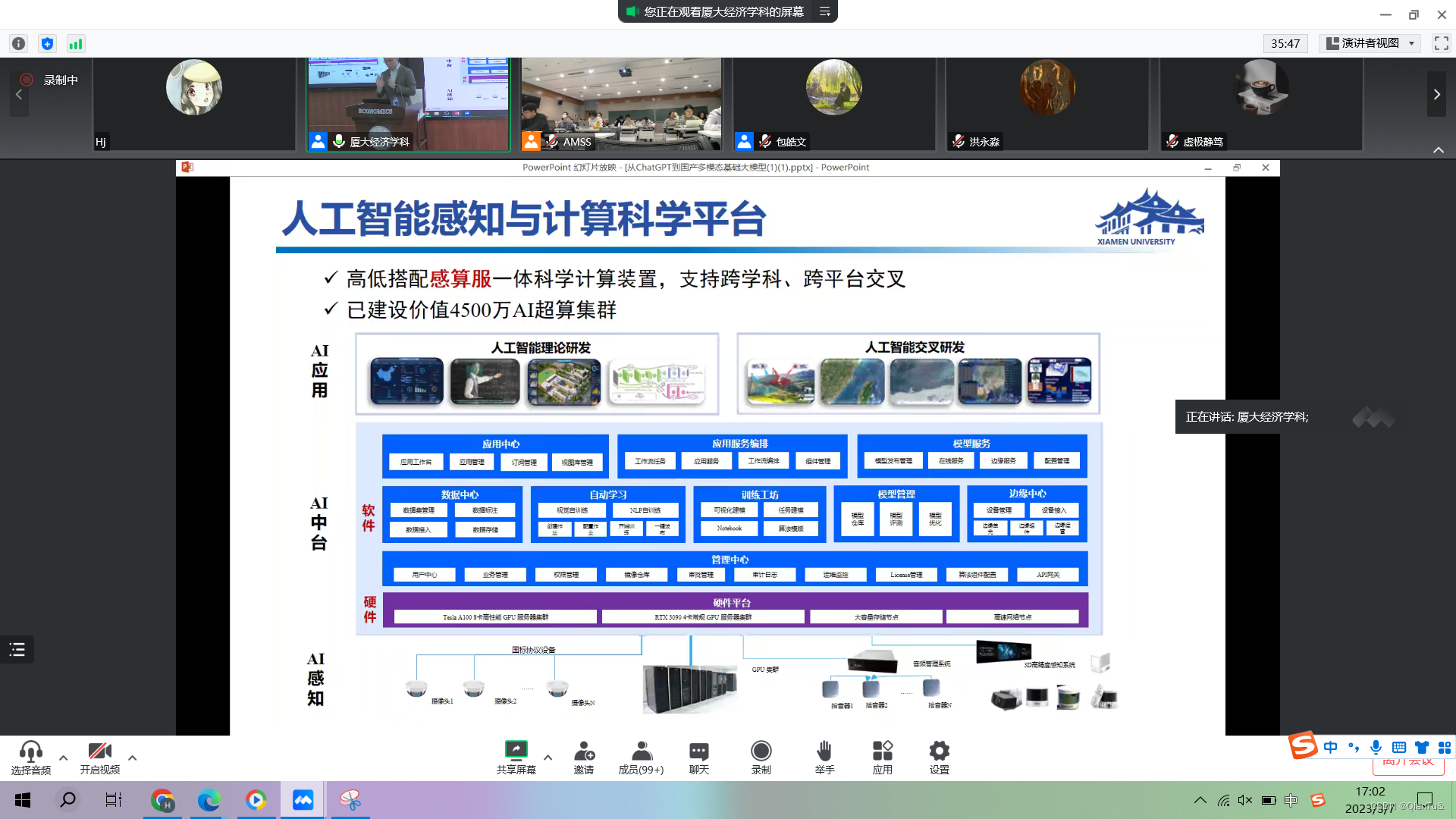

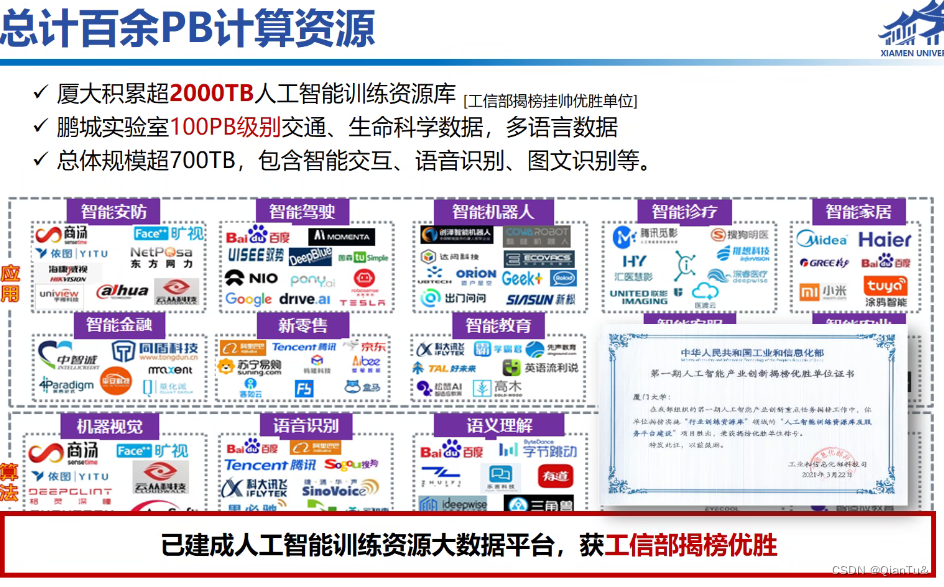
给标注数据和原始数据,他们把模型做出来。
给data,他们做模型

鹏程国家实验室不穷,很有钱
下边的模型花了27个亿
鹏程*神农——新冠预测的模型——4000张GPU卡。


国产大模型-神农模型
**用户需求:**蛋白的RDB区域是否病变
**研究动机:**提前预测病毒变异类型


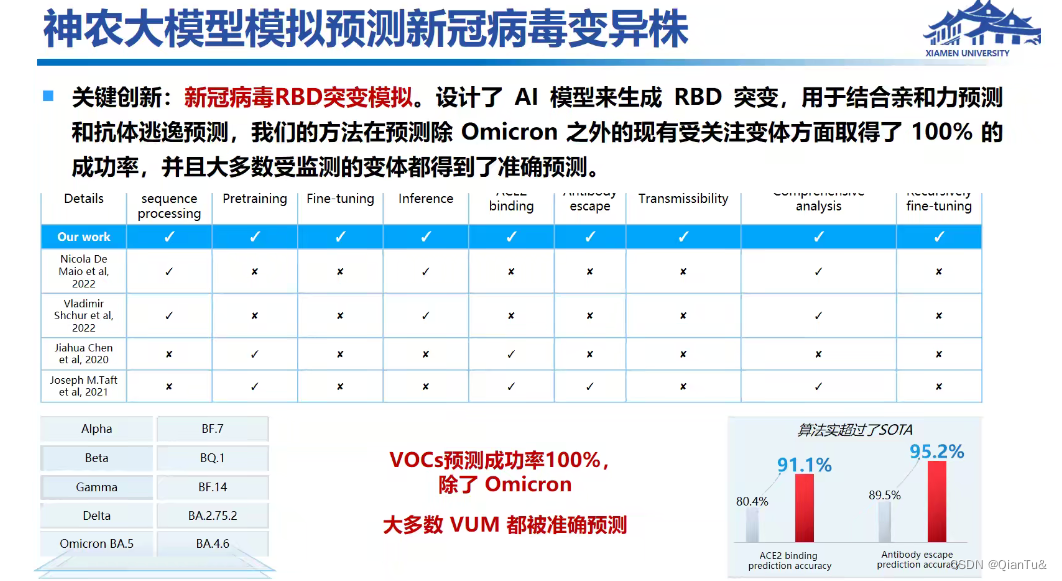
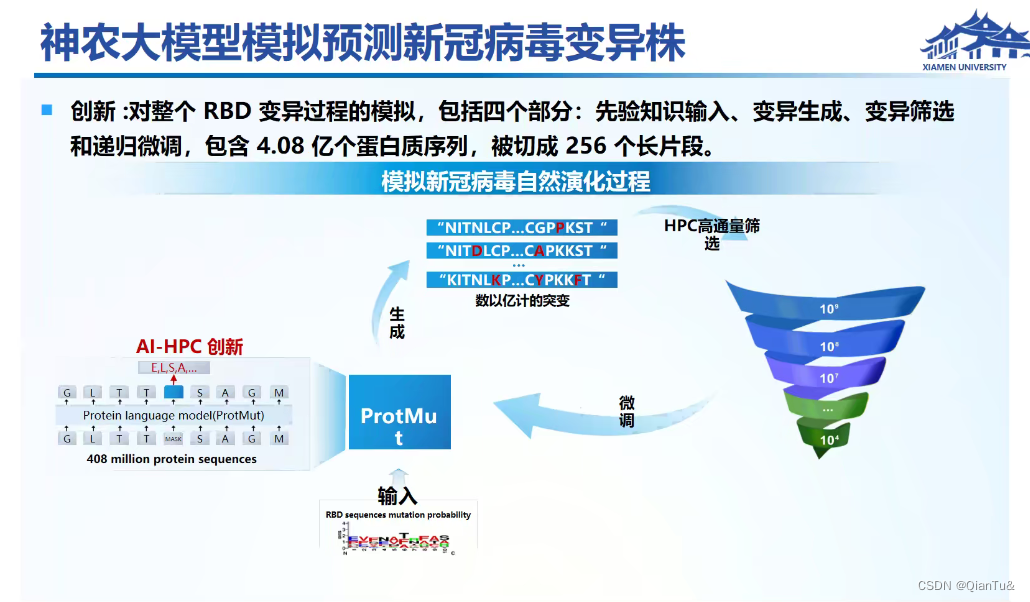
蓝色表示结合亲力上升,月蓝色月可能发生变异

新颖的多任务损失函数,是什么?新在哪?

**
**
流感病毒能直接迁移吗?应该不行吧?流感应该不是看RBD吧?

可能的未来的方向
给一部电影,写成一本小说。
给一本小说,拍出来一步电影。

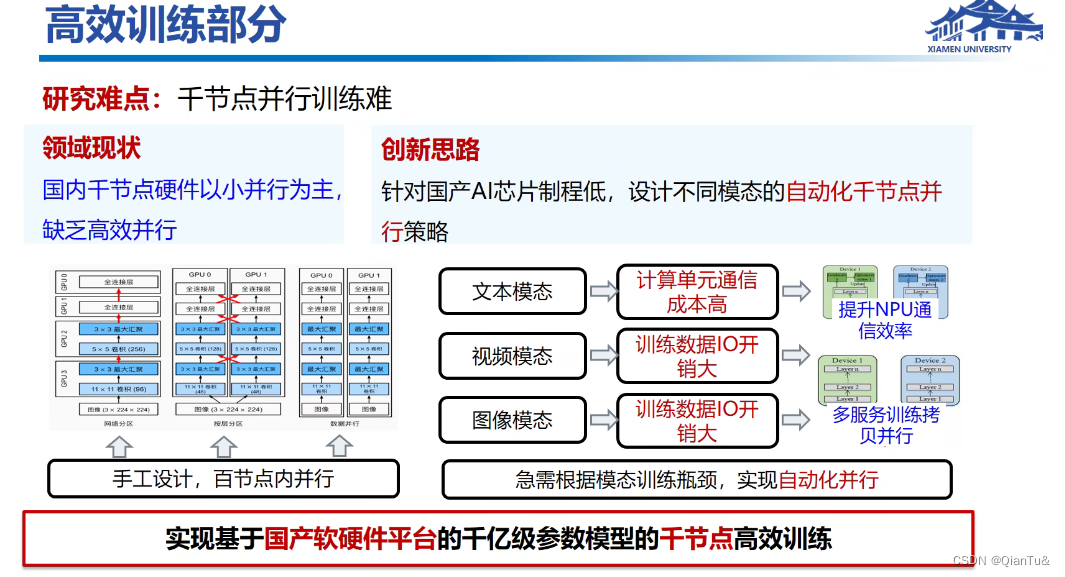
一轮300万,学生写的代码完蛋
土豪做法是数据或者任务线性排,没钱,做聚类’
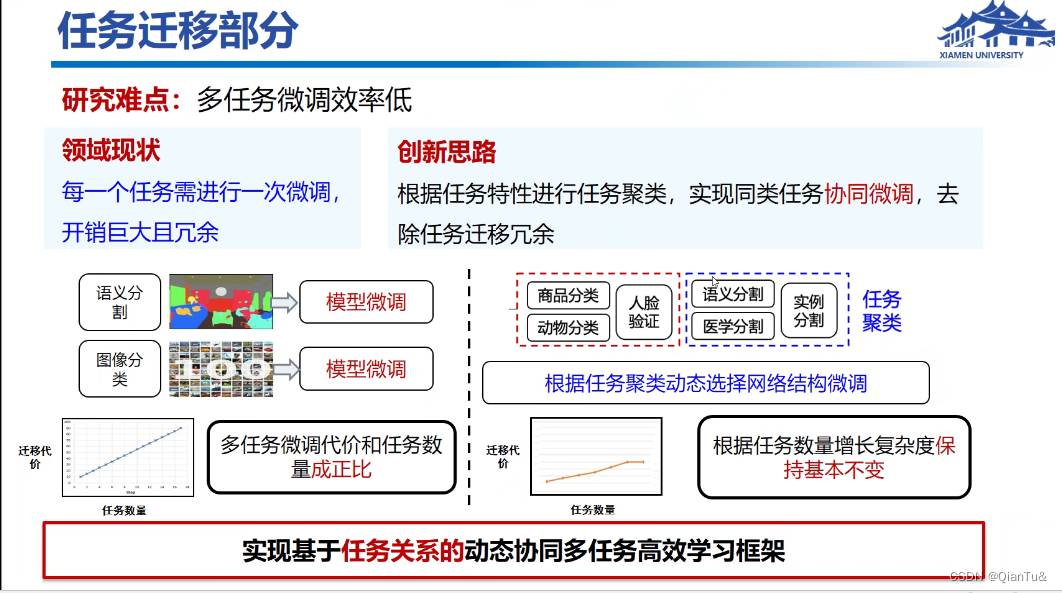
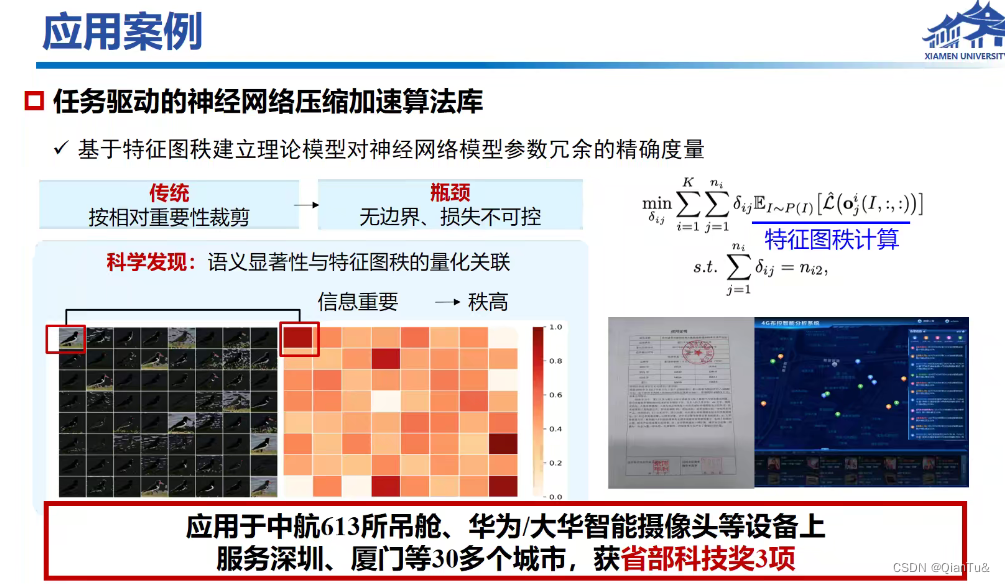
模型压缩
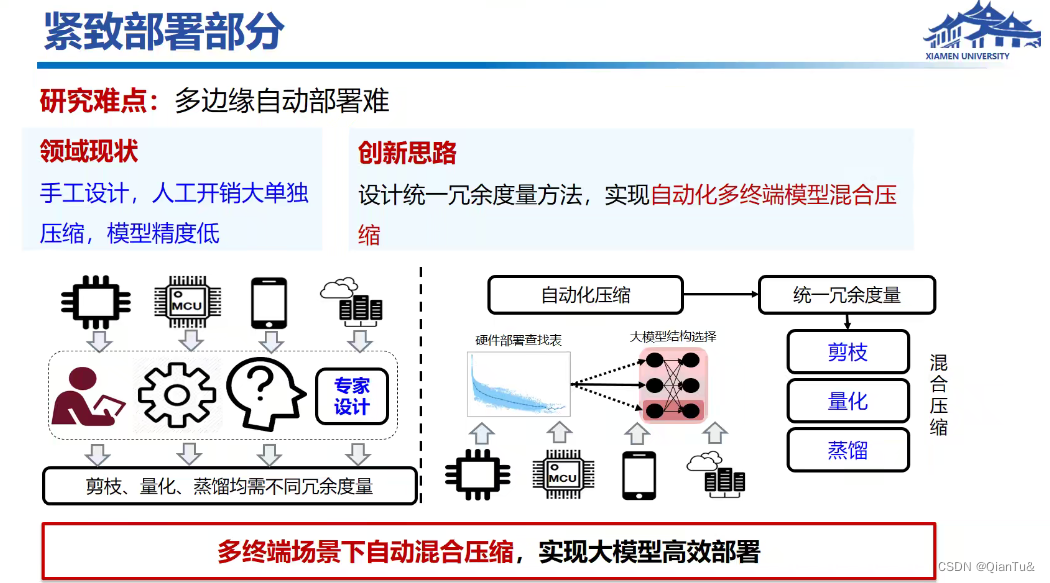
洪永淼:
AI领域的问题:
确定性问题(当输入和输出是确定的)
确定性答案
明确的,可控的情况下做模型。
数据量和标注数据的质量有关。
优化算法中,凸优化问题,怎么更新上万个参数?
梯度更新
上一篇:ArrayList集合底层原理
下一篇:计算机网络学习中