Photon Vectorized Engine 学习记录
迪丽瓦拉
2024-05-26 14:57:47
0次
Photon Hash Aggregation Vectorization
Photon Hash Join 的向量化的要点是:使用开放地址法。步骤:
- 向量化计算 hash 值
- 基于 hash 向量化计算 bucket 下标,得到 bucket index 向量
- 基于 bucket index 向量中记录的下标找到 bucket,判定是否冲突,如果冲突则继续向下,直至找到正确 bucket,将正确 bucket 下标回填到 bucket index 向量中 (Not So Vectorized)。下图中绿色就是解决冲突后找到的 bucket 位置。
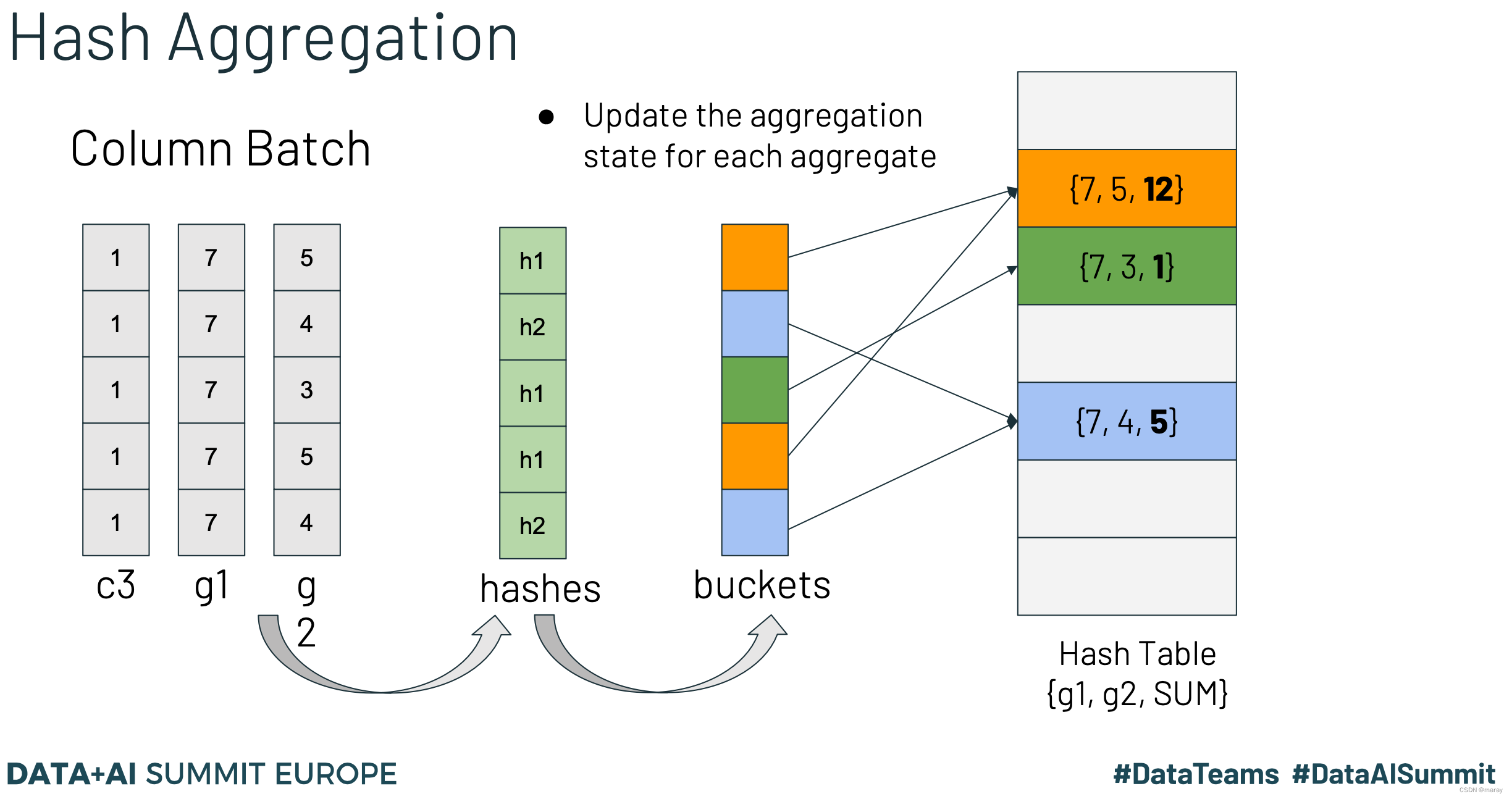
4. 向量化计算 Aggregate 值。伪代码如下:

可以看到,上面几个步骤里,除了 3 里面有一些不规整的操作,其余都是非常简单的 kernel 操作。
Photon 关于 Null 的考虑
Photon 测试发现,为了处理 Null,会付出 23+% 的开销。基于如下观察:
- 用户很少专门给列加上 Not Null 约束
- 很多场景里虽然没有指明 Not Null 约束,但实际数据中 Null 很少
所以,Photo 给每一个 batch 的数据都附带了一个 has_nulls() 标记,如果这一批数据里面一个 null 都没有,那么这一批数据的计算就可以使用 NotNullKernel,性能最佳;反之,就回退到使用 WithNullKernel,付出必要的代价。

注意:这里要强调 Batch,而不是全量数据。全量数据里有少许 Null,但其中大部分 Batch 里没有 Null,就能用上上述优化。
Photon 关于 Selector / Active Rows 考虑
考虑到存在 Filter,并且 Filter 可能会过滤掉大部分数据,Photon 为过滤后的数据创建了一个 Active Rows 结构,用于索引未被过滤的数据。
增加 Active Rows 概念后,后继所有数据访问都要通过 Active Rows 索引来定位,成为框架固有开销。
另一种实现思路是引入 Skip 数组,当行过滤时,Skip[i] 被设置为 1,否则为 0。访问过滤后的数据时,需要遍历整个 skip 数组。这么做的好处是(…内存好管理?),缺点是增加了不必要的判断。
相关内容
热门资讯
Linux-scheduler...
四、调度域 SDTL结构 linux内核使用SDTL结构体来组织CPU的层次关系 struct sc...
leetcode - 2379...
Description You are given a 0-indexed string block...
Retinanet网络与foc...
参考代码:https://github.com/yhenon/pytorch-reti...