JVM下篇(三、JVM监控及诊断工具-GUI篇)
JVM_JVM监控及诊断工具-GUI篇
提示: 本材料只做个人学习参考,不作为系统的学习流程,请注意识别!!!
JVM
- JVM_JVM监控及诊断工具-GUI篇
- 三、JVM监控及诊断工具-GUI篇
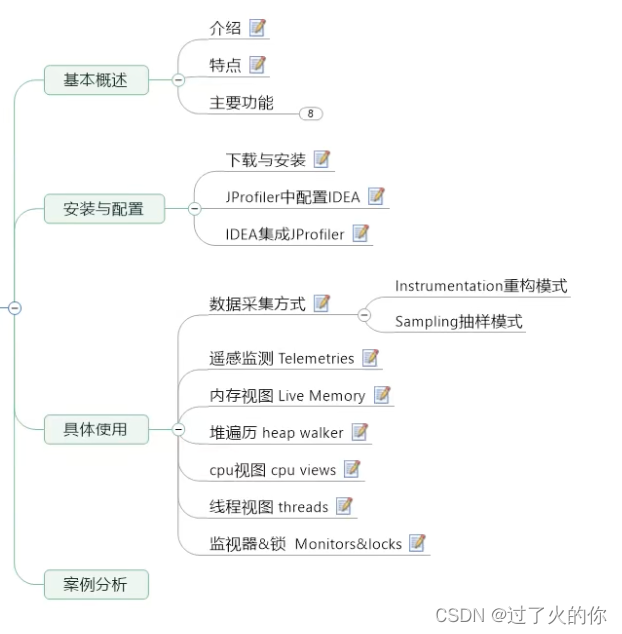
- 3.1 工具概述
- 3.2 jConsole
- 3.2.1 基本概述
- 3.2.2 启动
- 3.2.3 三种连接方式
- 3.2.4 测试示例
- 3.3 Visual VM
- 3.3.1 基本概述
- 3.3.2 插件的安装
- 3.3.3 连接方式
- 3.3.4 主要功能
- 3.4 eclipse MAT
- 3.4.1 基本概述
- 3.4.2 获取堆Dump文件
- ⭐️⭐️⭐️基本使用案例
- 3.4.3 分析堆Dump文件
- ⭐️⭐️⭐️基本分析
- ⭐️⭐️⭐️MAT的支配树
- ⭐️⭐️⭐️MAT的使用案例
- 3.4.4 案例: Tomcat堆溢出分析
- 3.4.5 内存泄露补充
- 3.4.6 支持使用OQL语言查询对象信息
- 3.5 JProfiler
- 3.5.1 基本概述
- 3.5.2 安装与配置
- 3.5.3 具体使用
- 3.6 Arthas
- 3.6.1 基本使用
- 3.6.2 安装与启动
- 3.6.3 相关诊断指令
- 3.7 Java Mission Control
- 3.8 其他工具
- 3.8.1 Flame Graphs(火焰图)
- 3.8.2 Tprofiler
- 3.8.3 Btrace
三、JVM监控及诊断工具-GUI篇
3.1 工具概述
使用上一章命令行工具或组合能帮您获取目标Java应用性能相关的基础信息,但它们存在
下列局限:
- 无法获取方法级别的分析数据,如方法间的调用关系、各方法的调用次数和调用时间等(这对定位应用性能瓶颈至关重要)
- 要求用户登录到目标 Java 应用所在的宿主机上,使用起来不是很方便。
- 分析数据通过终端输出,结果展示不够直观。
为此,JDK提供了一些内存泄漏的分析工具,如jConsole, jvisualvm等,用于辅助开发人员定位问题,但是这些工具很多时候并不足以满足快速定位的需求。所以这里我们介绍的工具相对多一些、丰富一些
图形化综合诊断工具
1. JDK自带的工具
- jconsole:JDK自带的可视化监控工具。查看Java应用程序的运行概况、监控堆信息、永久区(或元空间)使用情况、类加载情况等。
位置:jdkibinljconsole.exe
-
Visual VM:Visual VM是一个工具,它提供了一个可视界面,用于查看Java虚拟机上运行的基于Java技术的应用程序的详细信息。
-
JMC:Java Mission Control,内置Java Flight Recorder。能够以极低的性能开销收集Java虚拟机的性能数据。
2. 第三方工具
- MAT:MAT (Memory Analyzer Tool)是基于Eclipse的内存分析工具,是一个快速、功能丰富的Java heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗。
Eclipse的插件形式
- JProfiler:商业软件,需要付费。功能强大。
与visualvM类似
- Arthas:Alibaba开源的Java诊断工具。深受开发者喜爱。
- Btrace:Java运行时追踪工具。可以在不停机的情况下,跟踪指定的方法调用、构造函数调用和系统内存等信息。
3.2 jConsole
3.2.1 基本概述
- 从Java5开始,在jdk中自带的java监控和管理控制台。
- 用于对JVM中内存、线程和类等的监控,是一个基于JMX(java management extensions)的GUI性能监控工具。
3.2.2 启动
jdk/bin目录下,启动jconsole.exe命令即可,不需要使用jps命令来查询。
mac下执行jconsole即可
3.2.3 三种连接方式
-
Local:使用jConsole连接一个正在本地系统运行的JVM,并且执行程序和运行jConsole的需要时同一个用户。jConsole使用文件系统的授权是通过RMI连接器连接到平台的MBean服务器上。这种从本地连接的监控能力只有Sun的JDK具有。
-
Remote:使用下面的URL通过RMI连接器连接到一个JMX代理service:jmx:rmi:///jndi/rmi://hostName:portNum/jmxrmi, hostName填入主机名称, portNum为JMX代理启动时指定的端口。jConsole为了建立连接,需要在环境变量中设置mx.remote.credentials来指定用户名和密码,从而进行授权。
参考资料:https://blog.csdn.net/qq_41633199/article/details/120777327
- Advanced:使用一个特殊的URL链接JMX代理。一般情况使用自己定制的连接器而不是RMI提供的连接器来连接JMX代理,或者是一个使用JDK1.4的实现了JMX和JMX Remote的应用。
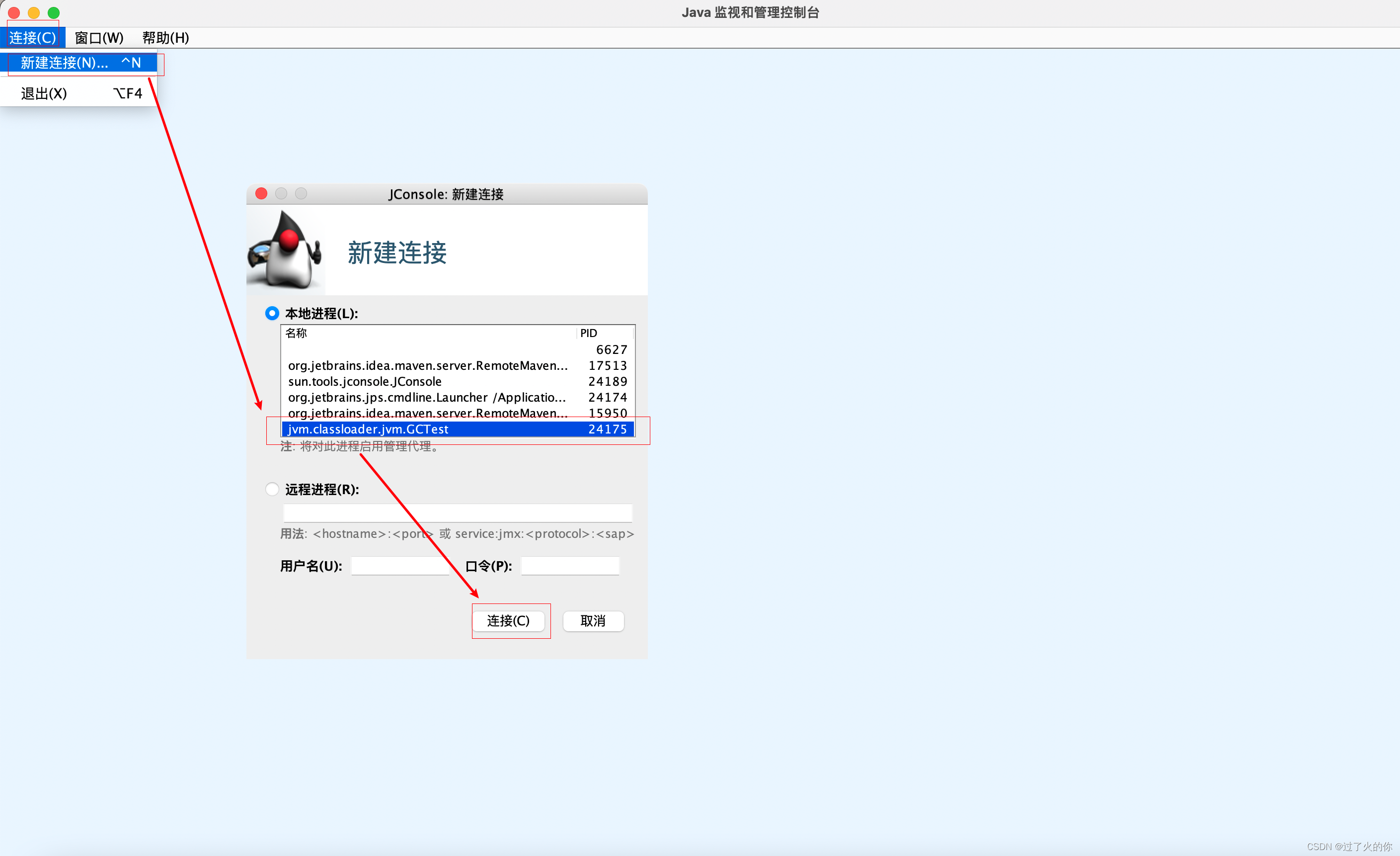
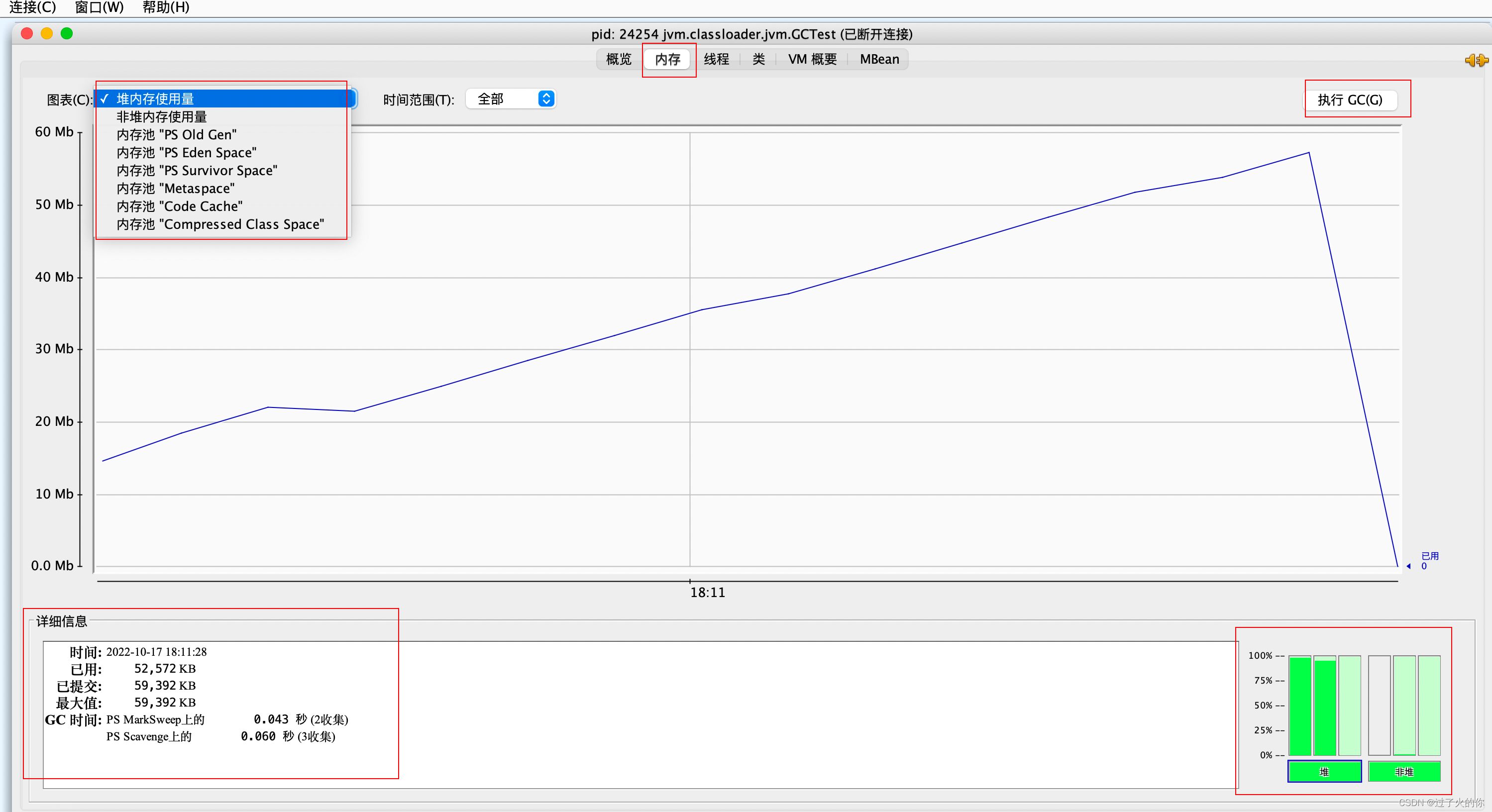
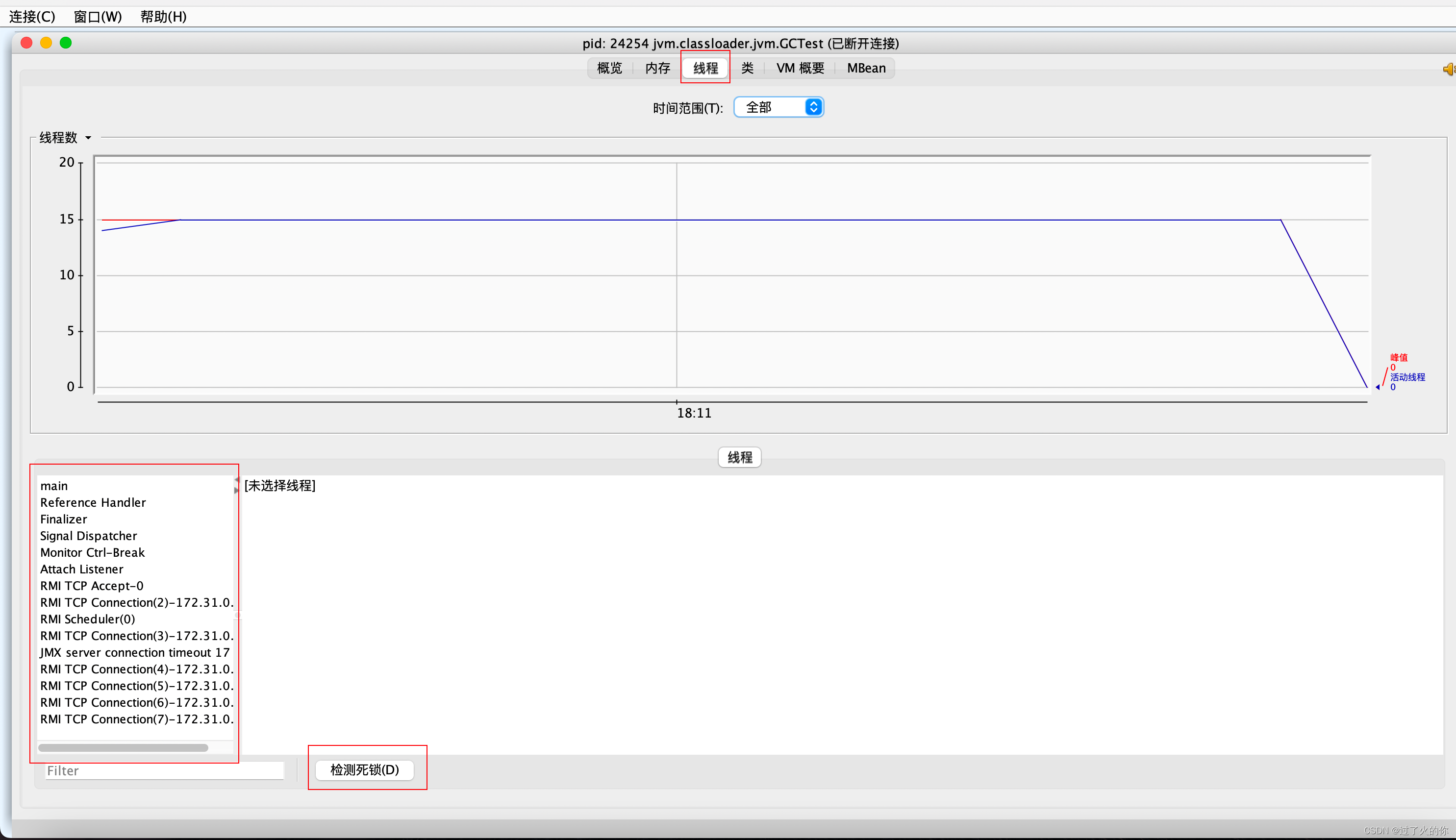
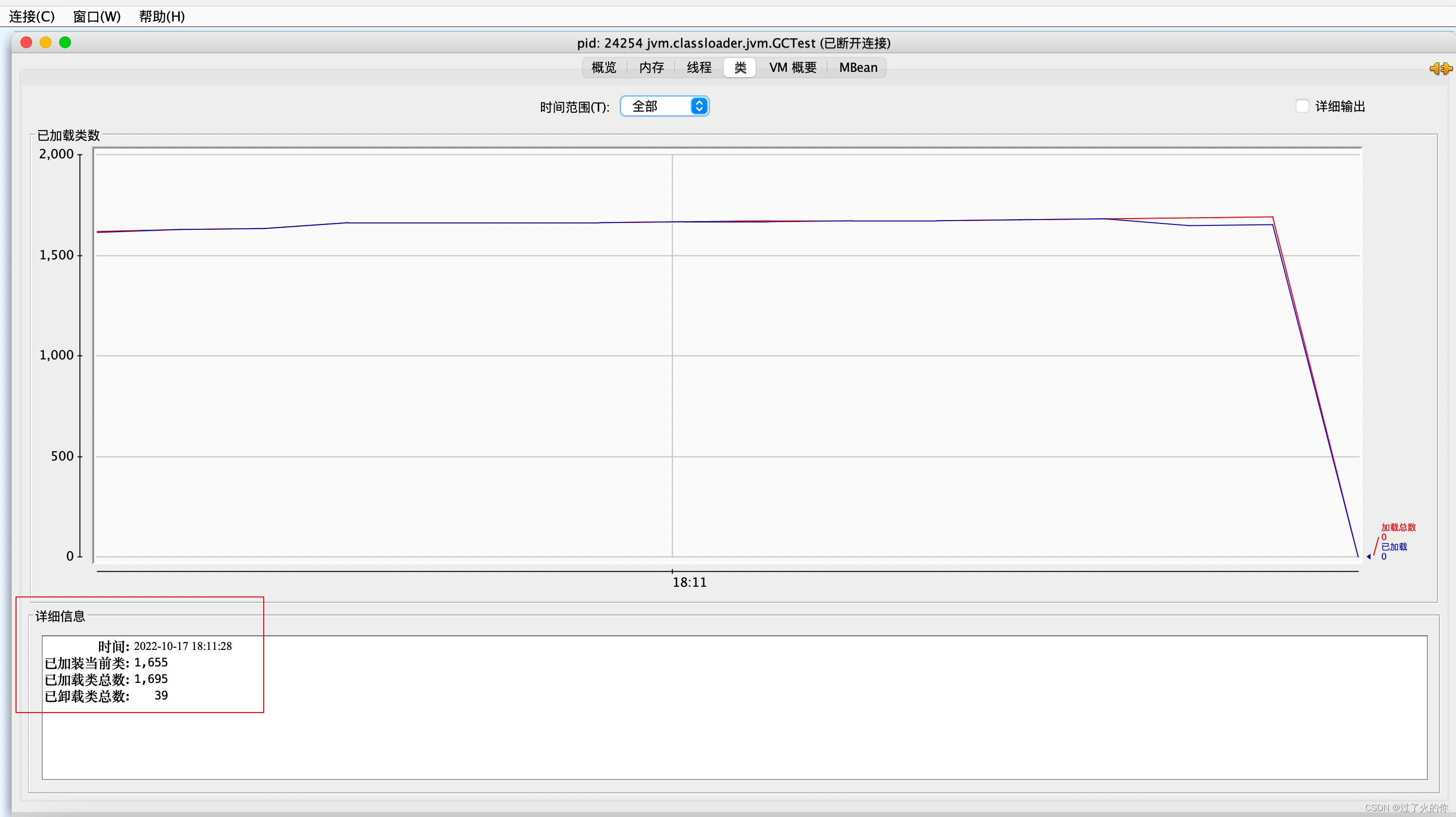
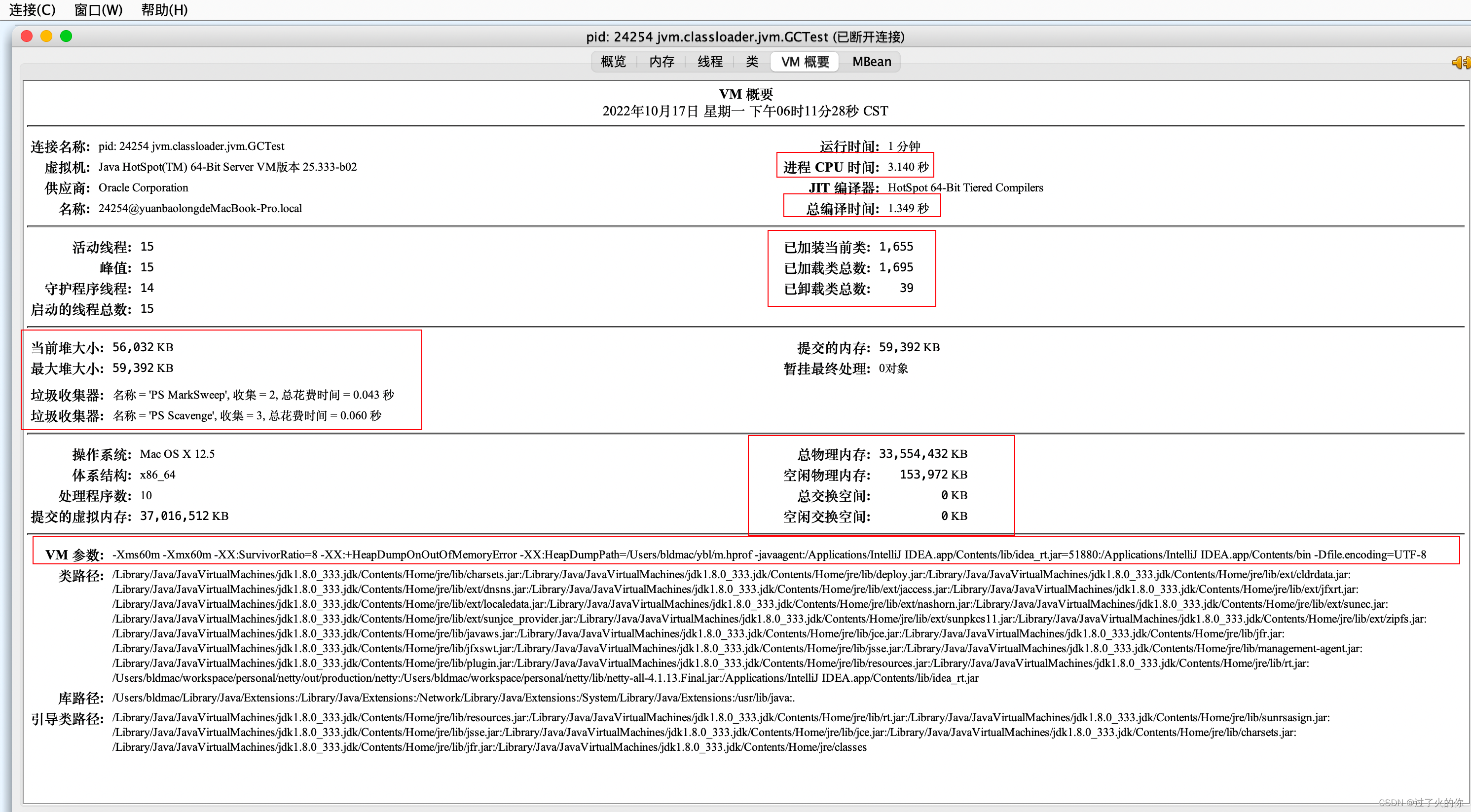
3.2.4 测试示例
测试代码
package jvm.classloader.jvm;import java.util.ArrayList;/*** -Xms60m -Xmx60m -XX:SurvivorRatio=8*/
public class GCTest {public static void main(String[] args) {ArrayList list = new ArrayList<>();for (int i = 0; i < 1000; i++) {byte[] arr = new byte[1024 * 100];//100kblist.add(arr);try {Thread.sleep(120);} catch (Exception e) {e.printStackTrace();}}}
}
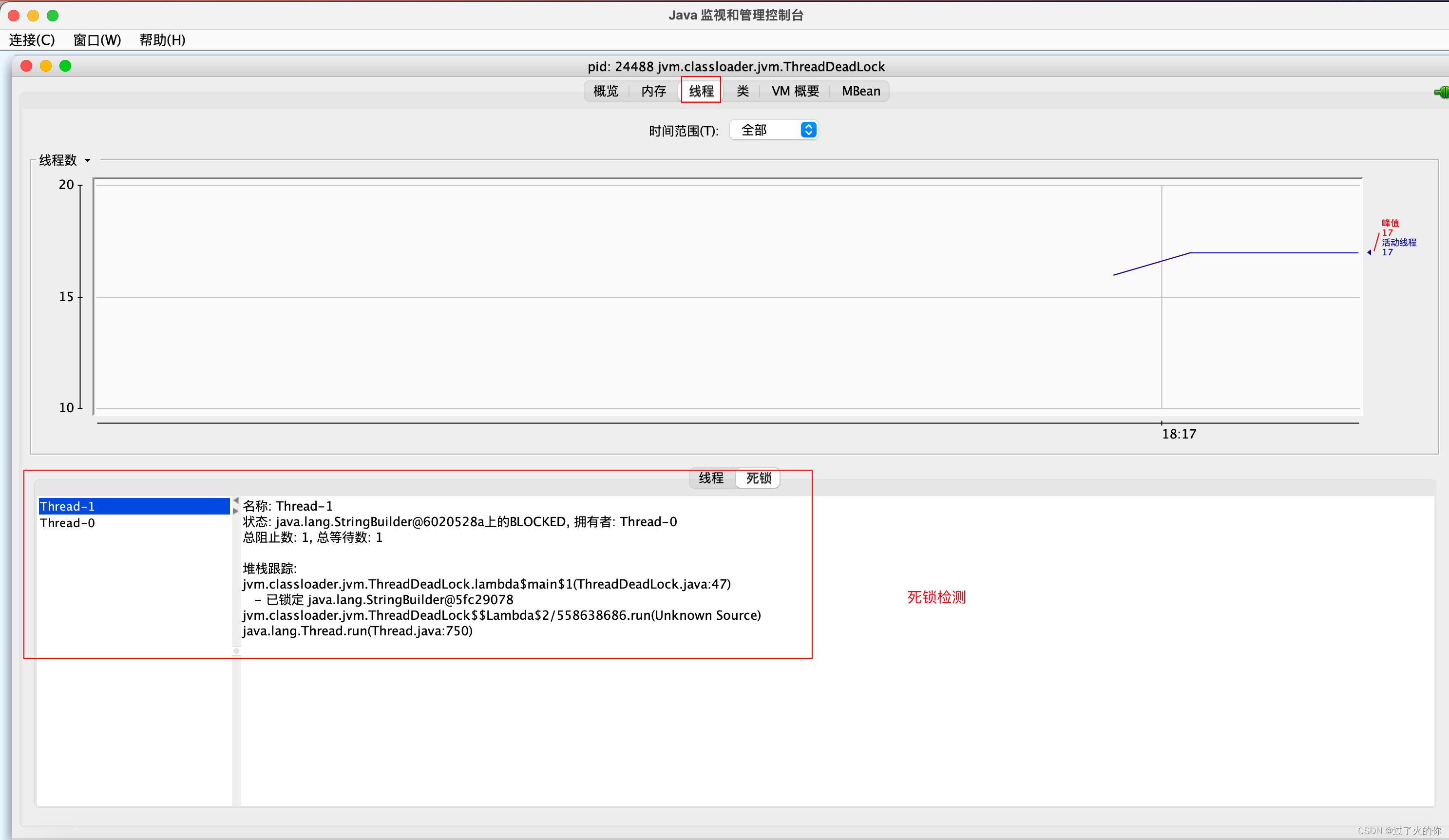
死锁测试代码
package jvm.classloader.jvm;/*** 死锁测试*/
public class ThreadDeadLock {public static void main(String[] args) {StringBuilder s1 = new StringBuilder();StringBuilder s2 = new StringBuilder();new Thread(() -> {synchronized (s1) {s1.append("a");s2.append("1");try {Thread.sleep(100);} catch (InterruptedException e) {throw new RuntimeException(e);}synchronized (s2) {s1.append("b");s2.append("2");System.out.println(s1);System.out.println(s2);}}}).start();new Thread(() -> {synchronized (s2) {s1.append("c");s2.append("3");try {Thread.sleep(100);} catch (InterruptedException e) {throw new RuntimeException(e);}synchronized (s1) {s1.append("d");s2.append("4");System.out.println(s1);System.out.println(s2);}}}).start();}
}
3.3 Visual VM
3.3.1 基本概述
- Visual VM是一个功能强大的多合一故障诊断和性能监控的可视化工具。
- 它集成了多个JDK命令行工具,使用Visual VM可用于显示虚拟机进程及进程的配置和环境信息(jps、jinfo),监视应用程序的CPU、GC、堆、方法区以及线程的信息(jstat、jstack)等,甚至代替JConsole。
- 在JDK6 Update 7以后,Visual VM便作为JDK的一部分发布(Visual VM在JDK/bin目录下),完全免费。
- Visual VM也可以作为独立的软件安装。
3.3.2 插件的安装
- Visual VM的一大特点就是支持插件扩展,并且插件安装非常方便,我们既可以通过离线下载插件文件*.nbm,然后再Plugin对话框的已下载页面下,添加已下载的插件。也可以再可用插件页面下,在线安装。(建议安装:VisualGC)插件地址:https://visualvm.github.io/pluginscenters.html
- Mac安装VisualVM
- IDEA安装VisualVM Launcher插件
Preferences —> Plugins —> 搜索VisualVM Launcher,安装重启即可。
3.3.3 连接方式
- 本地连接:监控本地Java进程的CPU、类、线程等。
- 远程连接:
- 确定远程服务器的ip地址
- 添加JMX(通过JMX技术具体监控远程服务器哪个Java进程)
- 修改bin/catalina.sh文件,连接远程的tomcat
- 在…/conf中添加jmxremote.access和jmxremote.password文件
- 将服务器地址改为公网ip地址
- 设置阿里云安全策略和防火墙策略
- 启动tomcat,查看tomcat启动日志和端口监听
- JMX中输入端口号、用户名、密码登陆
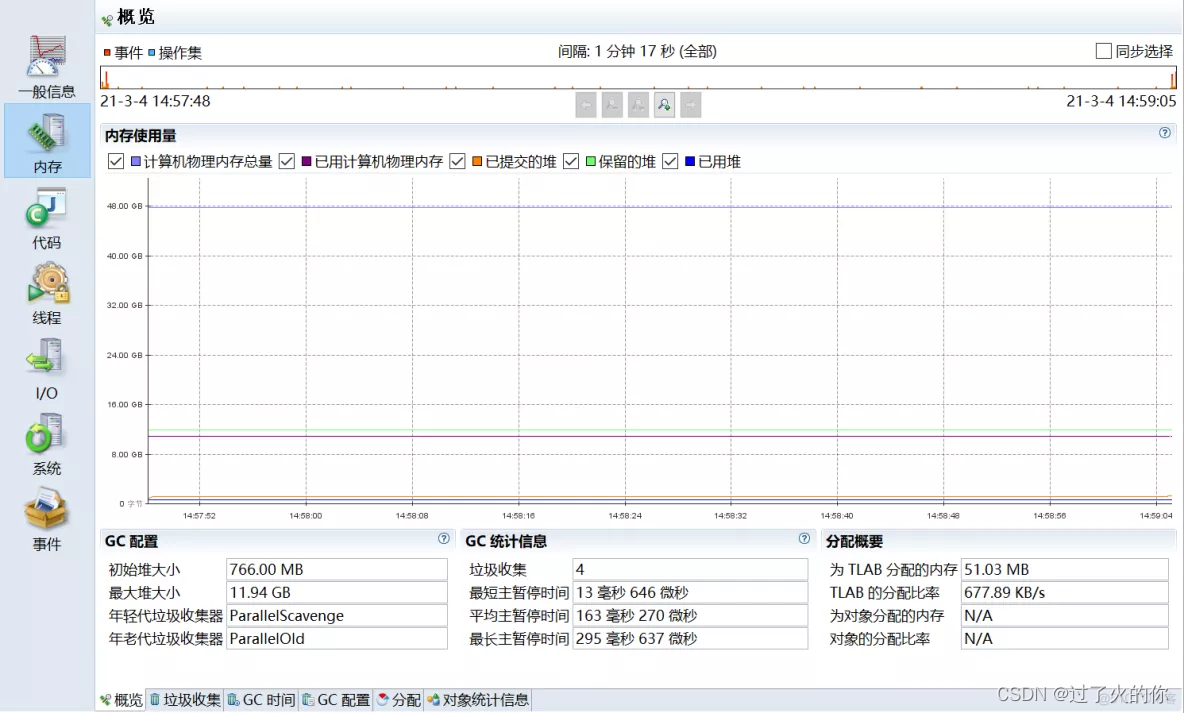
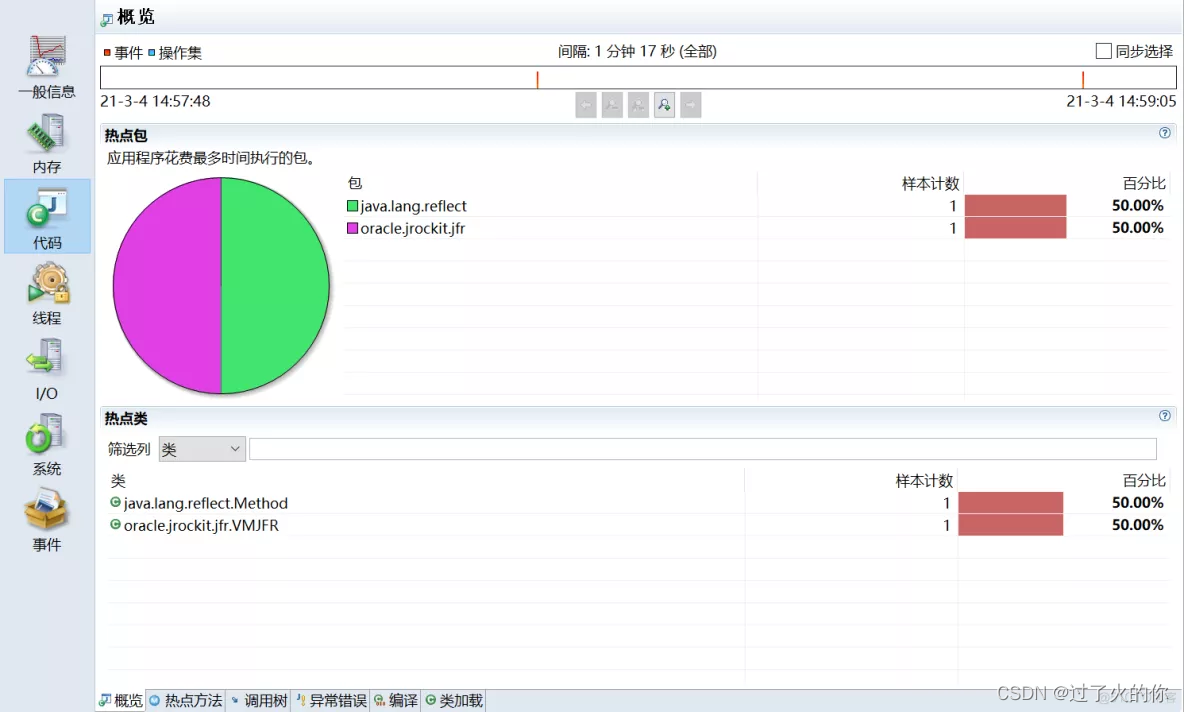
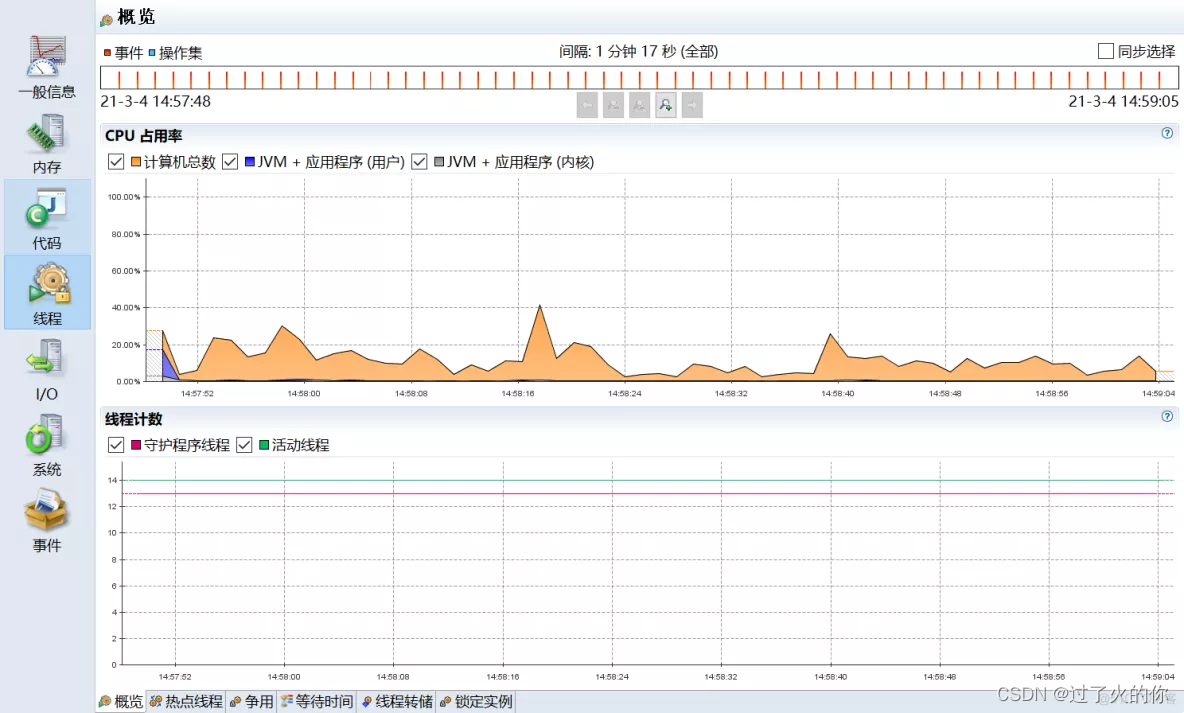
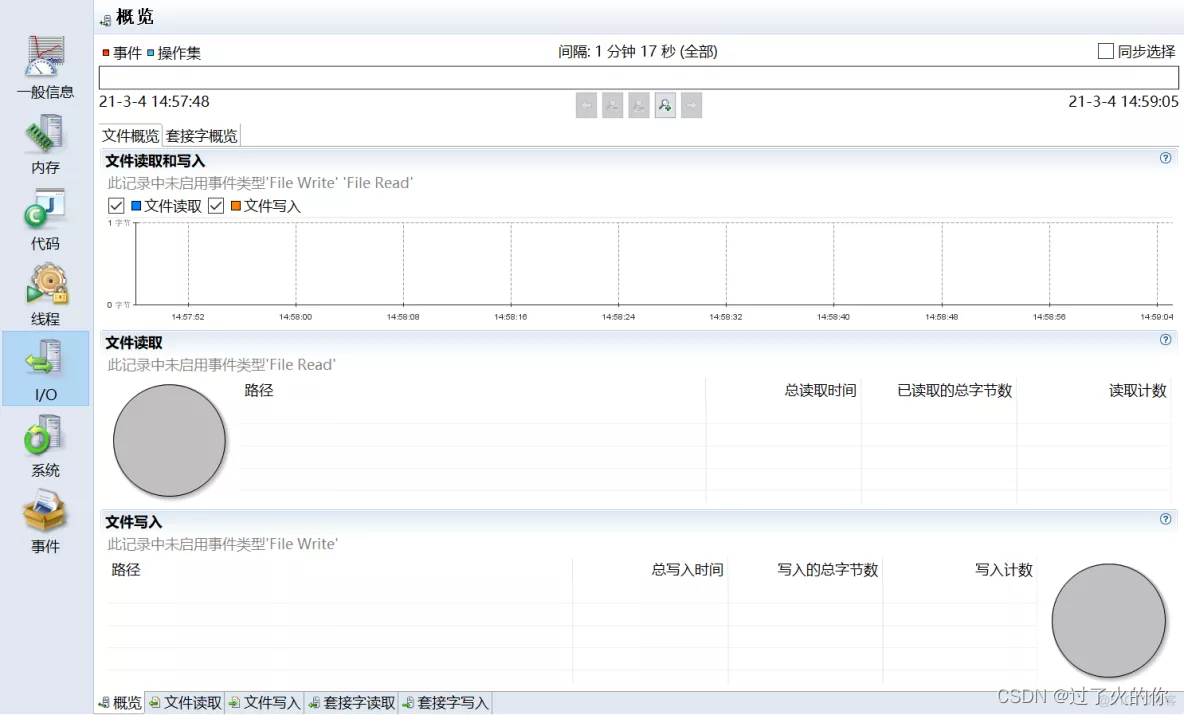
3.3.4 主要功能
中文界面
英文界面
采样器

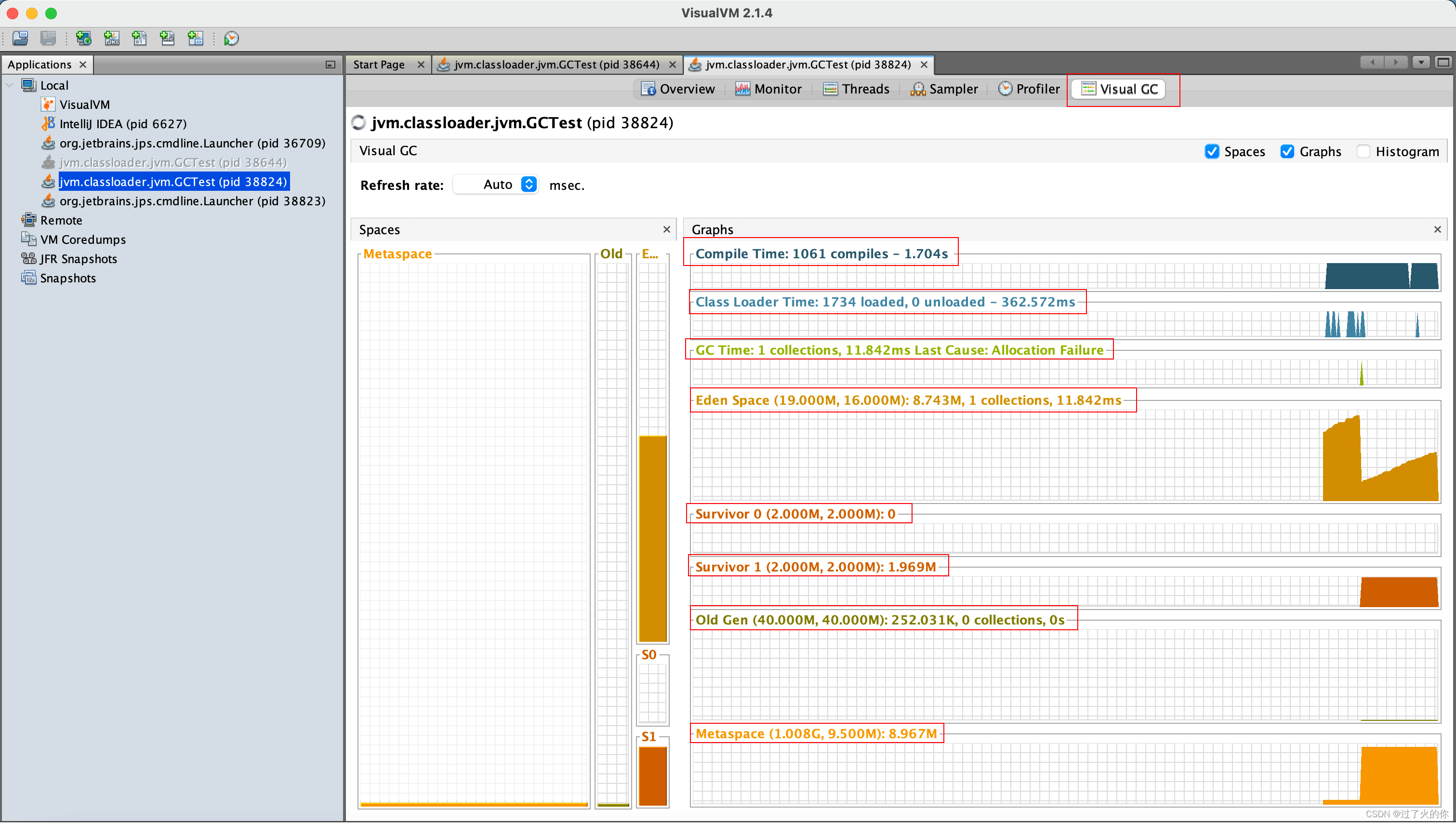
Visual GC
- 生成读取对堆内存快照
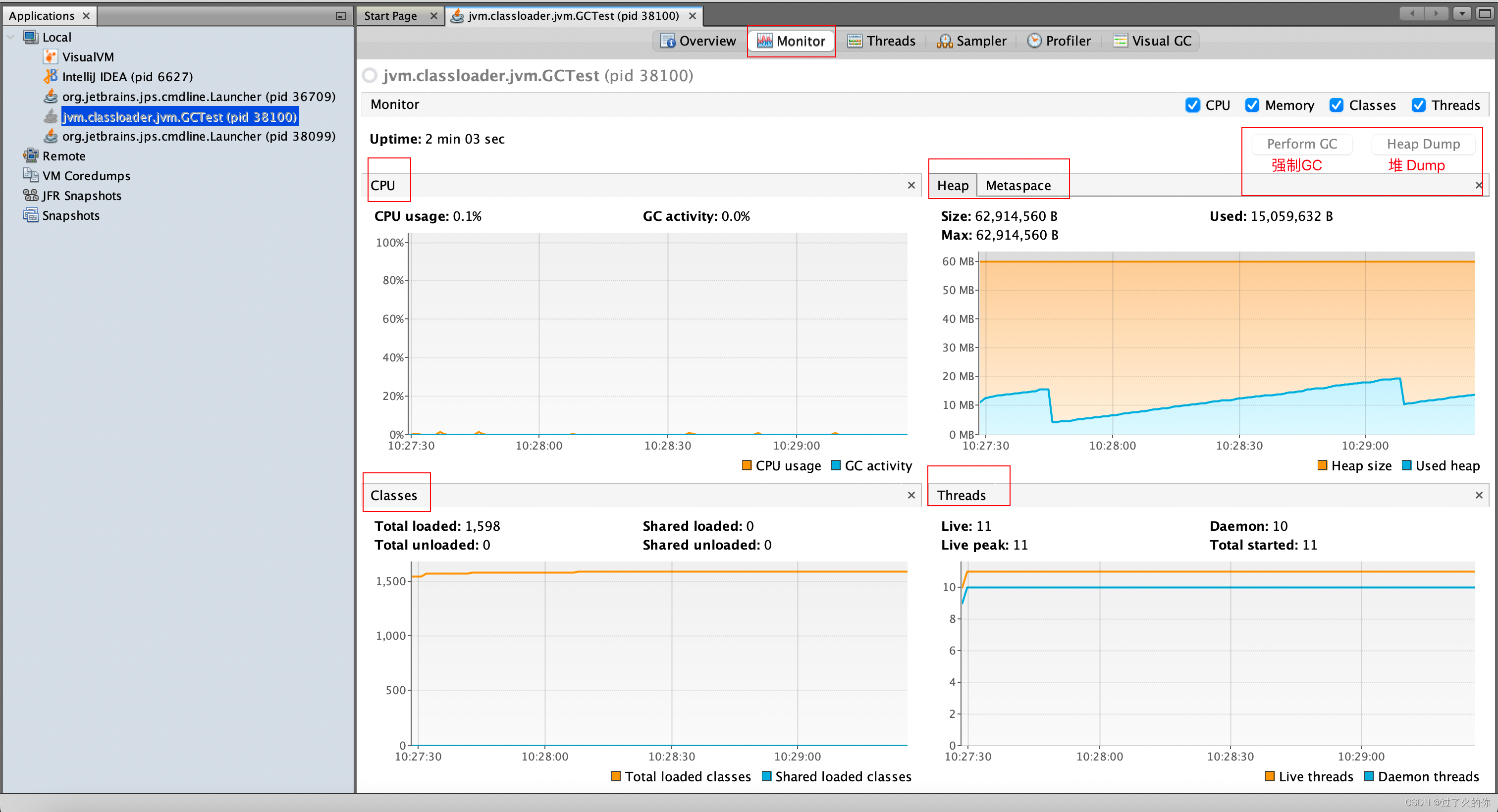
监视
生成Dump文件
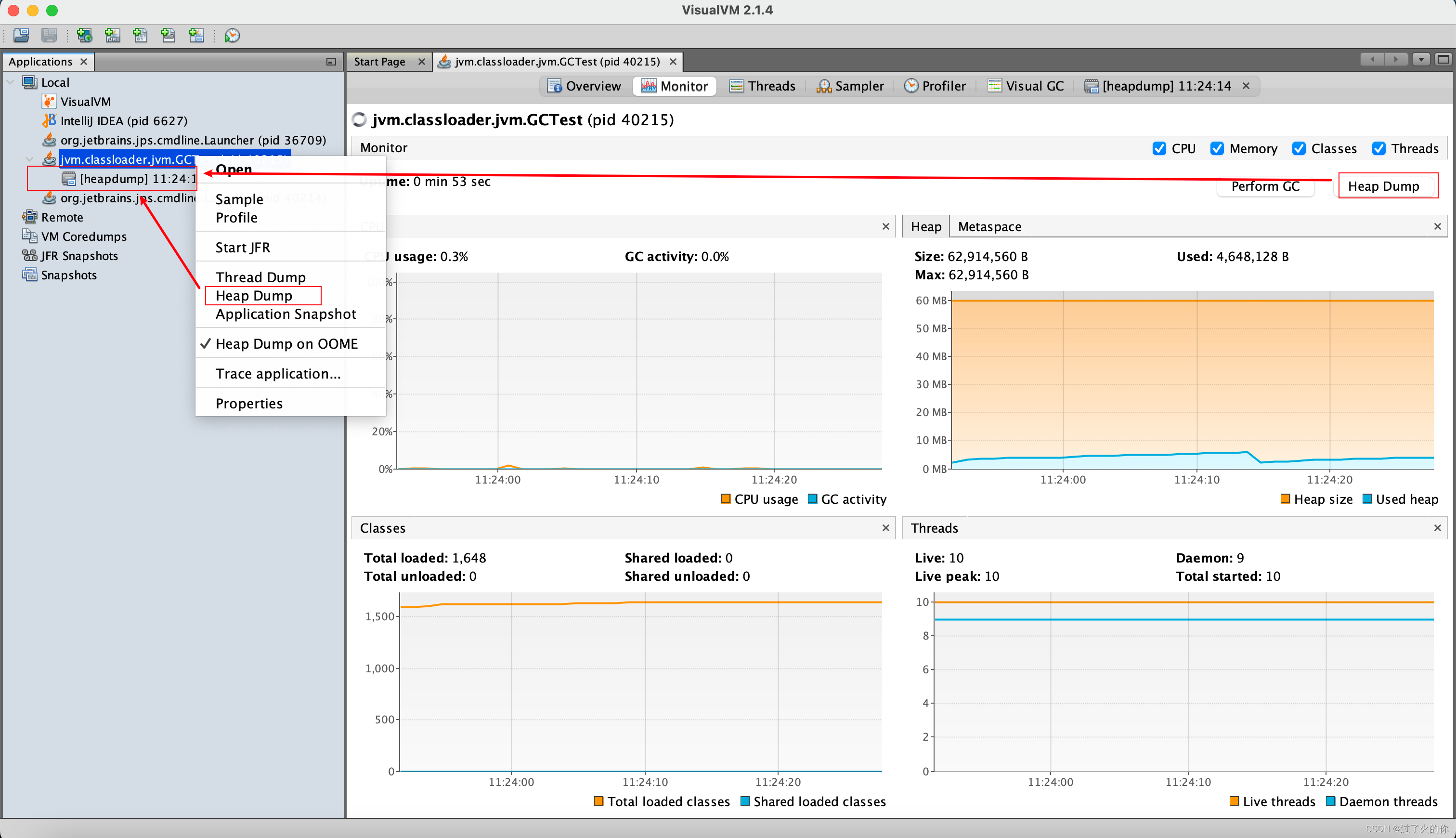
保存Dump文件

读取Dump文件
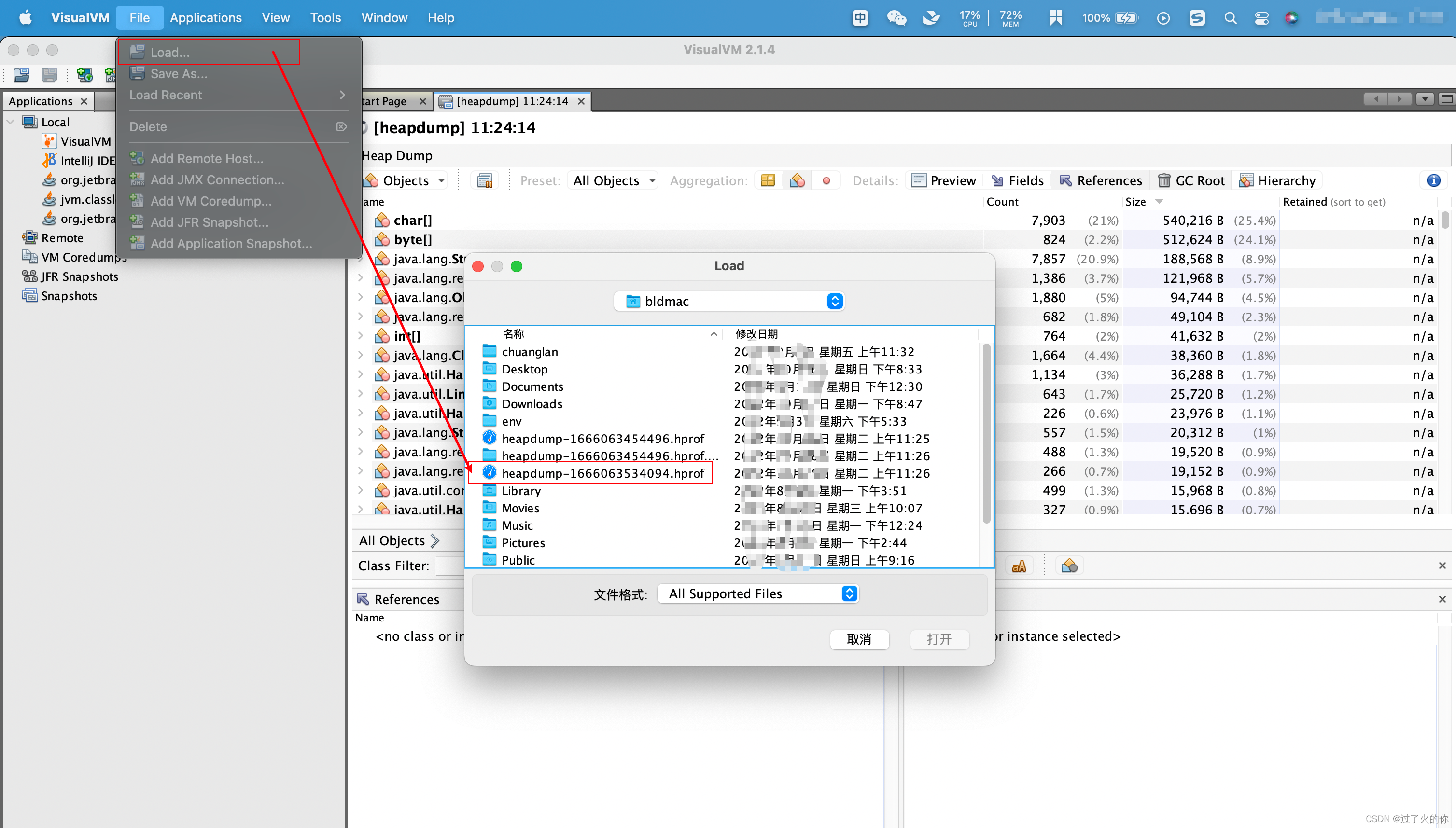
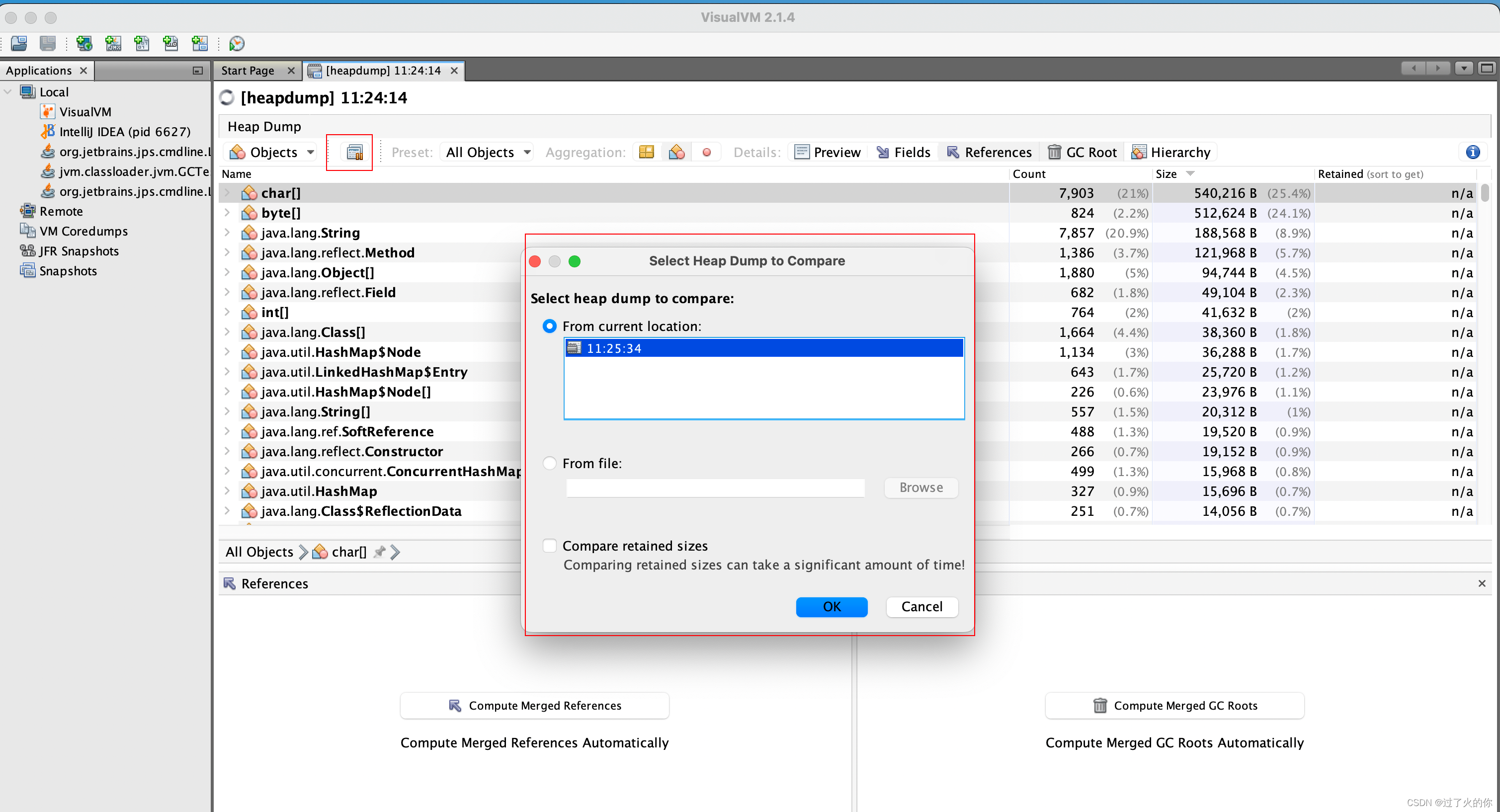
堆Dump文件比较
2. 查看JVM参数和系统属性
概述
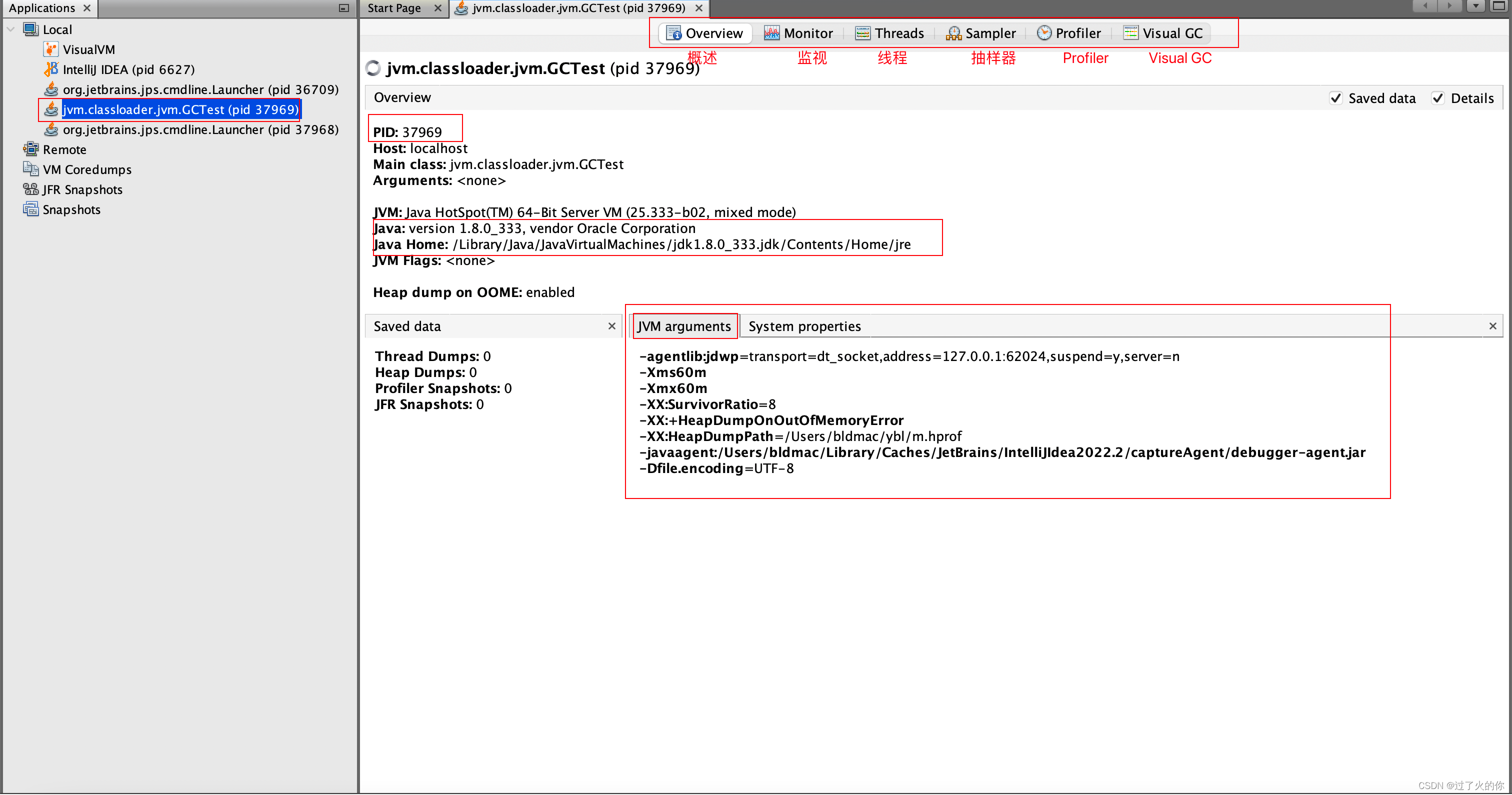
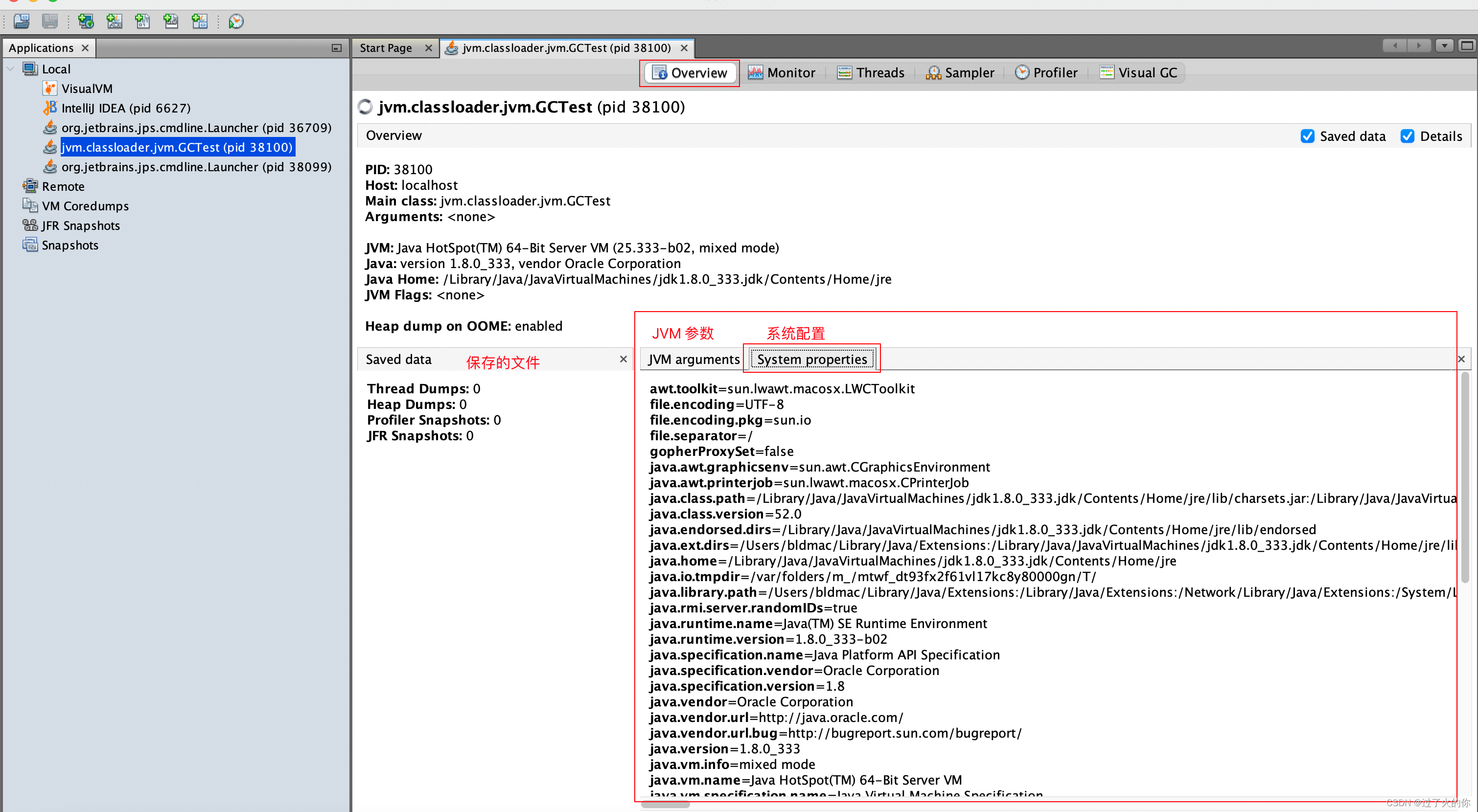
-
查看运行中的虚拟机进程
-
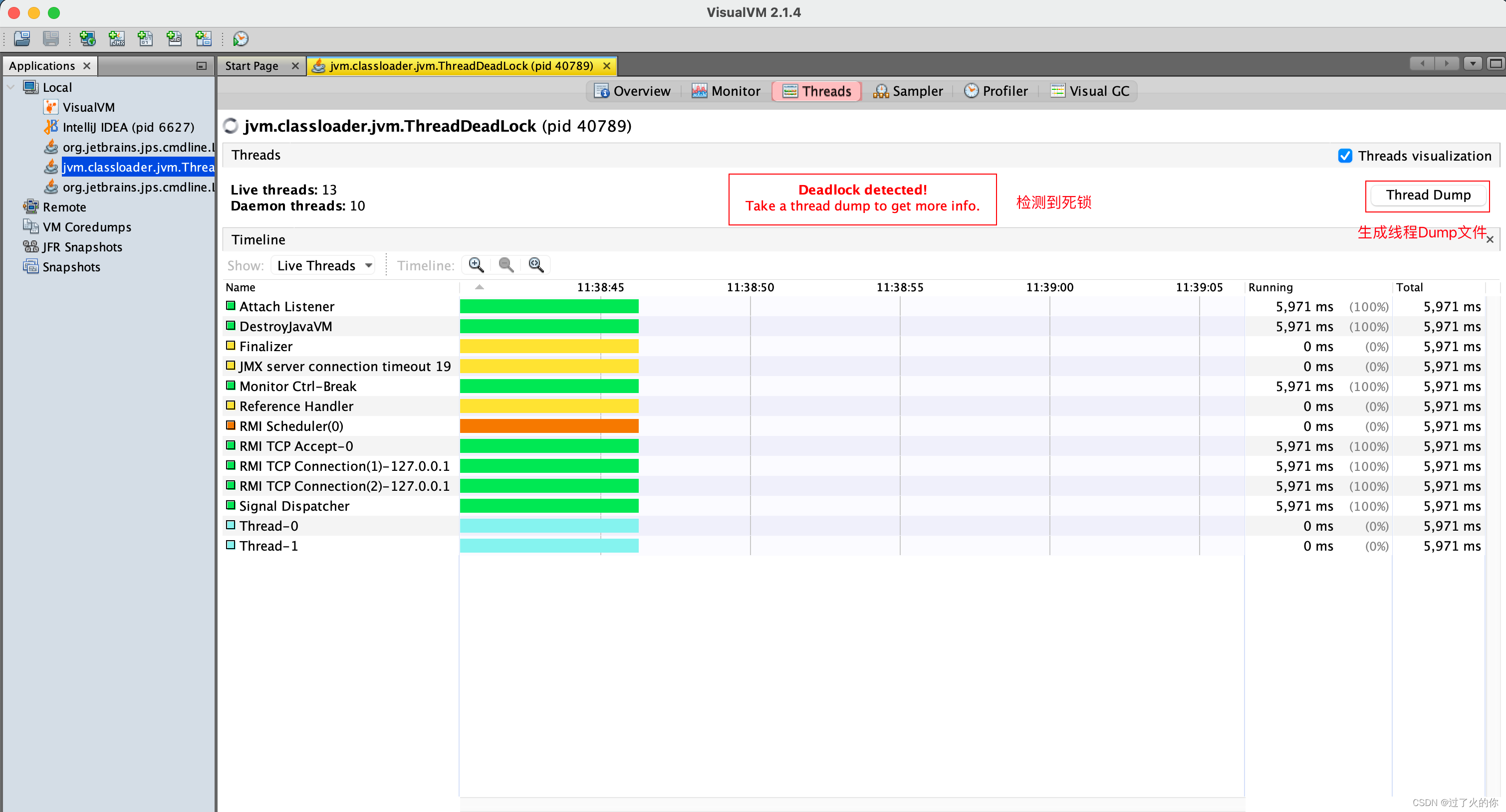
生成/读取线程快照
线程
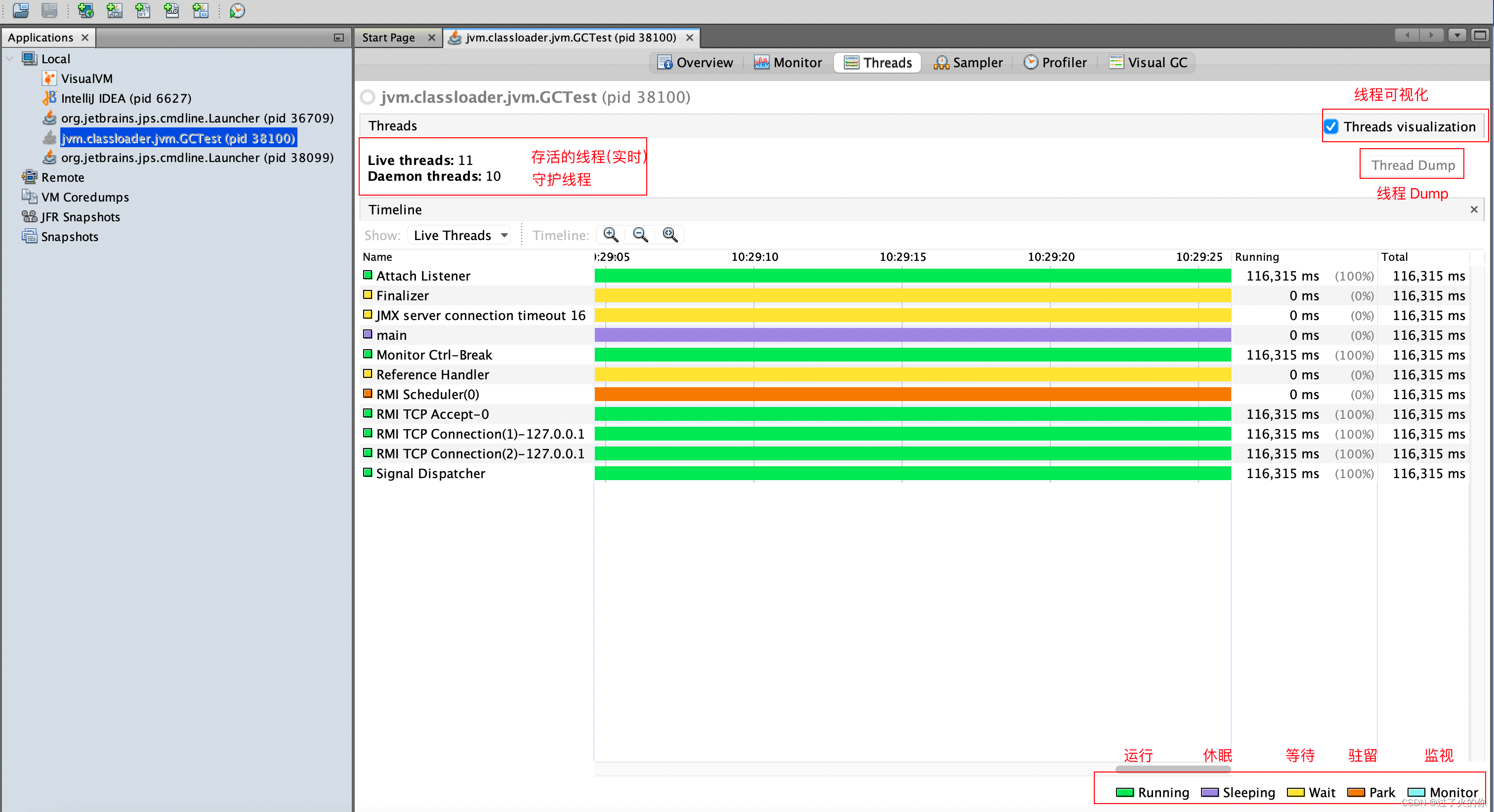
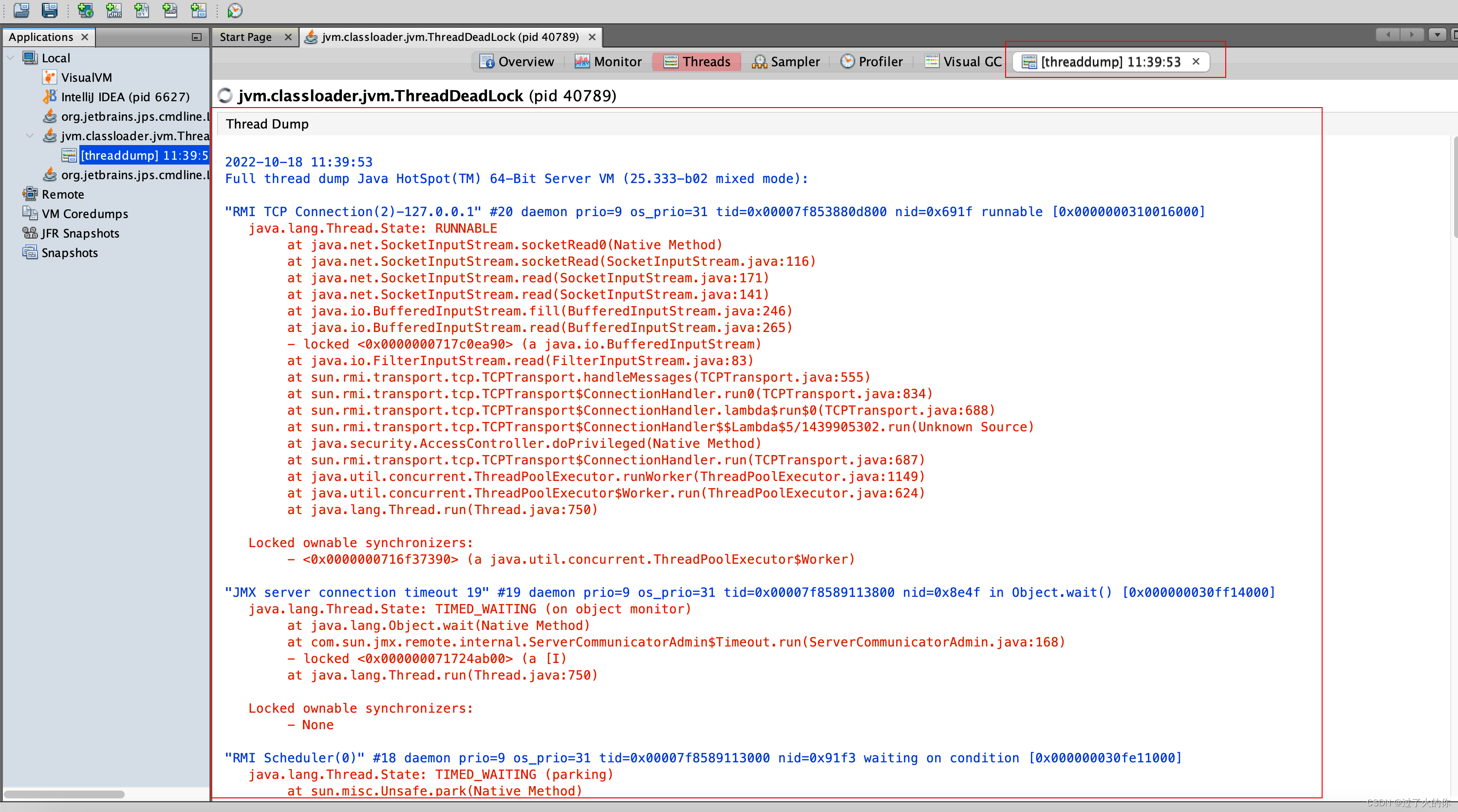
生成线程Dump文件
保存线程Dump文件与读取线程Dump文件和堆Dump类似。
- 程序资源的实时监控
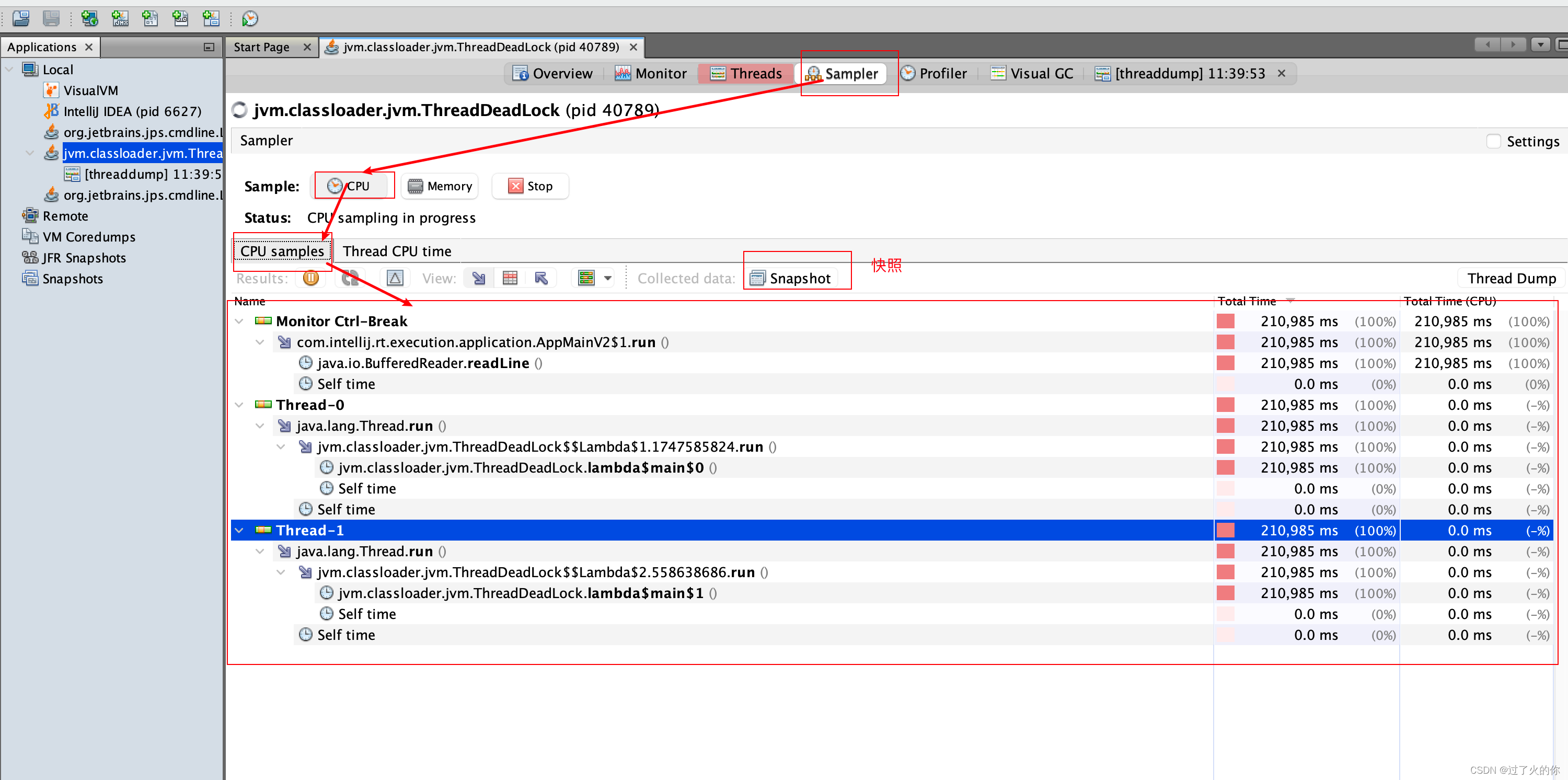

- 其他功能
- JMX代理连接
- 远程环境监控
- CPU分析和内存分析
3.4 eclipse MAT
3.4.1 基本概述
MAT(Memory Analyzer Tool)工具是一款功能强大的Java堆内存分析器。可以用于查询内存泄露以及查看内存消耗情况。
MAT是基于Eclipse开发的,不仅可以单独使用,还可以作为插件的形式嵌入到Eclipse中使用。是一款免费的性能分析工具,使用起来非常方便。
下载地址:http://www.eclipse.org/mat/downloads.php
只要确保机器上装有JDK并配置好相关的环境变量,MAT就可以正常启动,还可以在Eclipse中以插件的方式安装。
3.4.2 获取堆Dump文件
- Dump文件内容
MAT可以分析heap dump文件,在进行内存分析的时候,只要获取了反映当前设备内存映像的hprof文件,通过MAT打开就可以直观的看到当前的内存信息。
一般来说,这些内容包含:
- 所有的对象信息,包括对象实例、成员变量、存储于栈中的基本类型值和存储于堆中的其他对象的引用值。
- 所有的类信息,包括classloader、类名称、父类、静态变量等。
- GCRoots到所有的这些对象的引用路径。
- 线程信息,包括线程的调用栈及此线程的线程局部变量(TLS)
- 两点说明
- MAT不是一个万能的工具,它并不能处理所有类型的堆存储文件。但是比较主流的厂家和格式,比如:Sun、HP、SAP所采用的hprof二进制堆存储文件,以及IBM和PHD堆存储文件等都能被很好的解析。
- MAT最吸引人的地方,还是能够快速的为开发人员生成内存泄露报表,方便定位问题和分析问题。虽然MAT有如此强大的功能,但是内存分析也没简单到一键完成的程度,很多内存问题还需要我们从MAT展现给我们的信息中通过经验和直觉来判断才能发现。
- 获取Dump文件
- 方法一:通过上一章介绍的jmap工具生成,可以生成任意一个java进程的dump文件。
- 方法二:通过配置JVM参数生成。
-XX:+HeapDumpOnOutOfMemoryError 或 -XX:+HeapDumpBeforeFullGC
-XX:HeapDumpPath=< 文件名.hprof >
对比:考虑到生产环境中几乎不可能在线对其进行分析,大都是采用离线分析,因此使用jmap+MAT根据是最常见的组合。
- 方法三:使用Visual VM导出堆dump文件
- 方法四:使用MAT既可以打开一个已有的堆快照,也可以通过MAT直接从活动Java程序中导出堆快照。该功能将借助jps列出当前正在运行的Java进程,以供选择并获取快照。
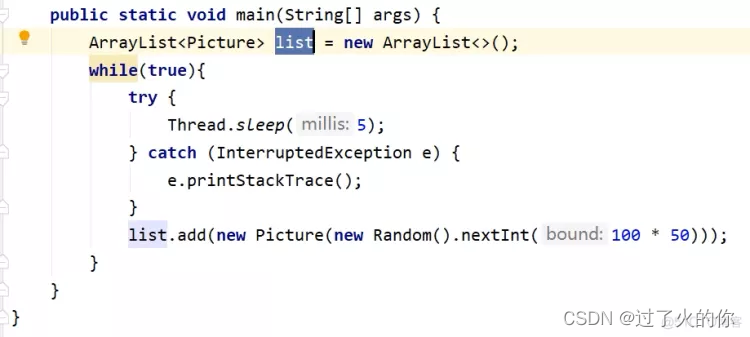
⭐️⭐️⭐️基本使用案例
import java.util.ArrayList;
import java.util.Random;/*** -Xms600m -Xmx600m -XX:SurvivorRatio=8*/
public class OOMTest {public static void main(String[] args) {ArrayList list = new ArrayList<>();while(true){try {Thread.sleep(5);} catch (InterruptedException e) {e.printStackTrace();}list.add(new Picture(new Random().nextInt(100 * 50)));}}
}class Picture{private byte[] pixels;public Picture(int length) {this.pixels = new byte[length];}
}
启动上面的代码,
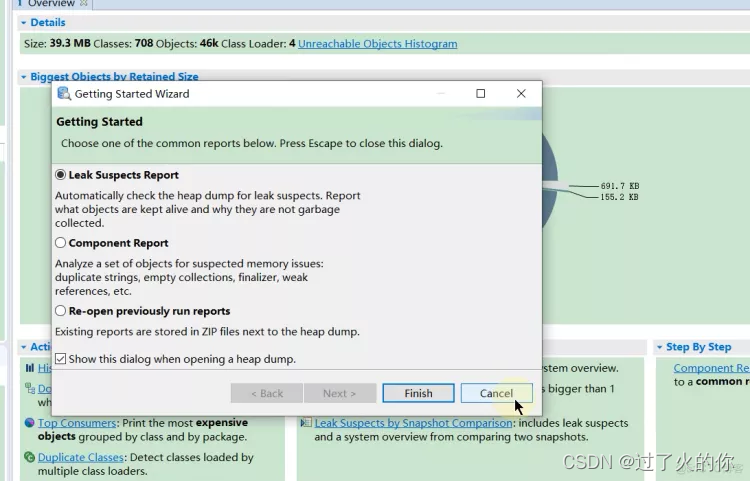
- 打开已经生成好的hprof文件
导出hprof文件

用eclipse的MAT插件打开,会出现下面的界面,直接点cancel就可以了,点finish也行
- 从进程中生成dump文件快照

根据进程号选择你要查看的进程
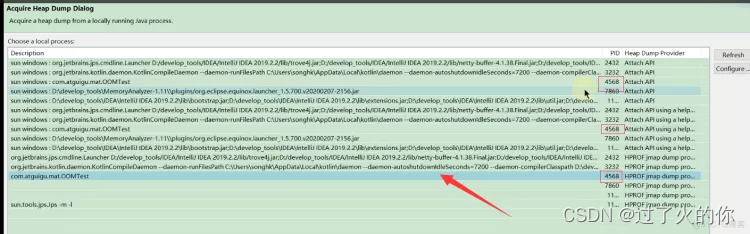
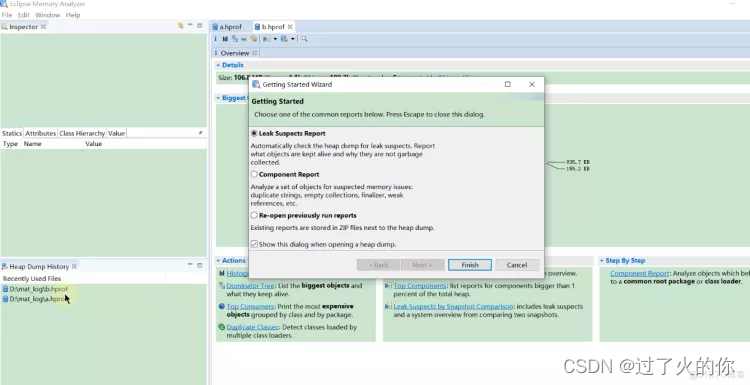
点击finish即可
- Getting Started Wizard介绍
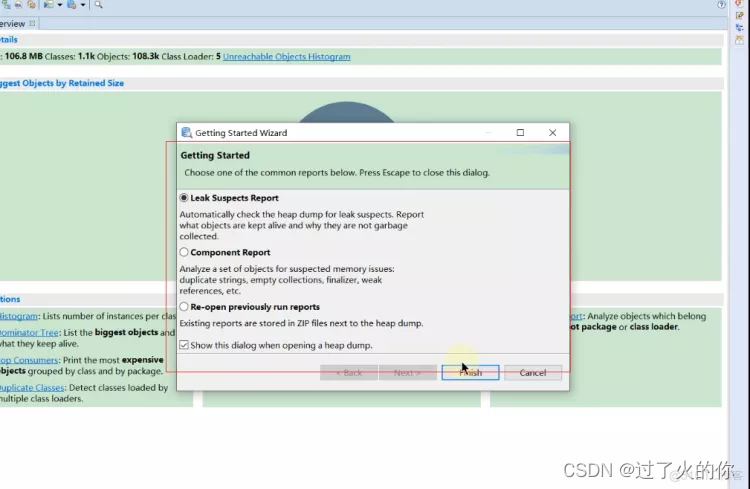
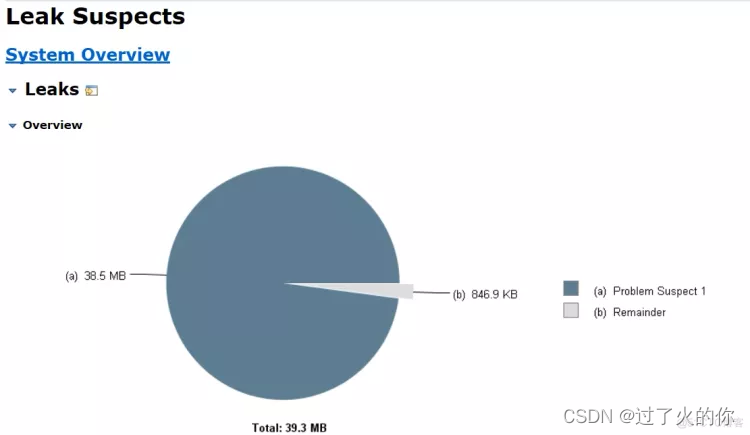
- leak suspects report 泄露的疑点报告
这个是mat会自动的检测dump文件,用于查看哪些是泄露的疑点,报告中会说明哪些对象还在存活,以及为什么没有被垃圾回收器收集。
内存泄露的问题非常关注这个,因为内存泄露就是对象不用了,但是为什么不能被垃圾回收器回收。
- Component Report 组件的报告
会分析对象的集合,找到相关的可疑的内存空间,比如说重复的字符串,空的集合容器,弱引用等等,这些都是我们认为可疑的内存。
- Re-open previously run reports 重新打开之前运行的 reports
之前存在的reports会和dump文件在同一个目录下的zip文件中
- MAT界面的主要功能
下面会依次介绍下面图片的意思
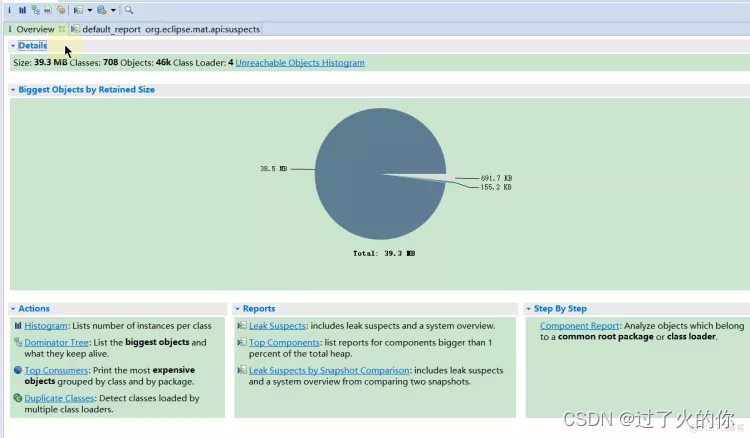
Size是当前dump文件的大小,
Classes是dump文件中加载的类的个数是708个,
Objects是dump文件中创建了46000个对象,46K就是46*1000,也就是46000
Class Loader是dump文件中使用的类加载器有四个
Unreadchable Objects Histogram 是不可达的对象的直方图
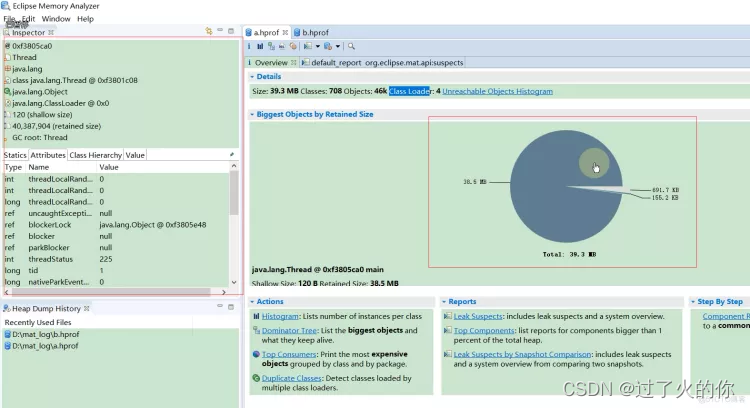
这个是保留的堆快照中内存中最大的对象是多少,你把鼠标点在哪里,然后左边Inspector就显示啥
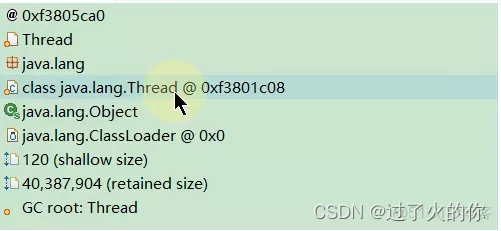
第一行: 是当前线程的编号
第二行: 不知道
第三行: class java.lang.Thread 就是当前的线程,0xf3801c08是当前线程的编号
第四行: java.lang.Object是父类的信息
第五行:
第六行: shallow 是浅堆
第七行: retained 是深堆
第八行:
堆文件的Overview:


第一行: dump文件的大小
第二行:对象的个数
第三行:类的个数
第四行:类加载器的个数
第五行:Gc roots 对象个数
第六行: 文件的类型
3.4.3 分析堆Dump文件
⭐️⭐️⭐️基本分析
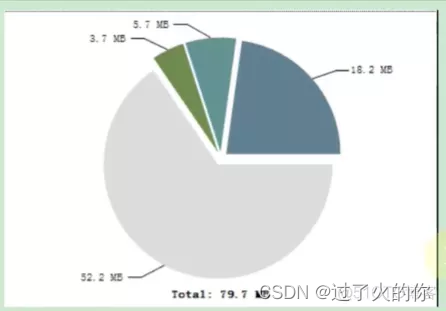

一般分析饼状图的时候先从最大的查看,当然也有可能这个最大的就是我们希望保存在堆里面的数据,那么我们就接着看饼状图第二大的数据,或者第三大的数据,这样就根据自己的项目情况看看哪个是有内存泄露的疑点的,分析出来之后,然后解决一下就完了。
- MAT中Histogram的功能演示
具体内容:
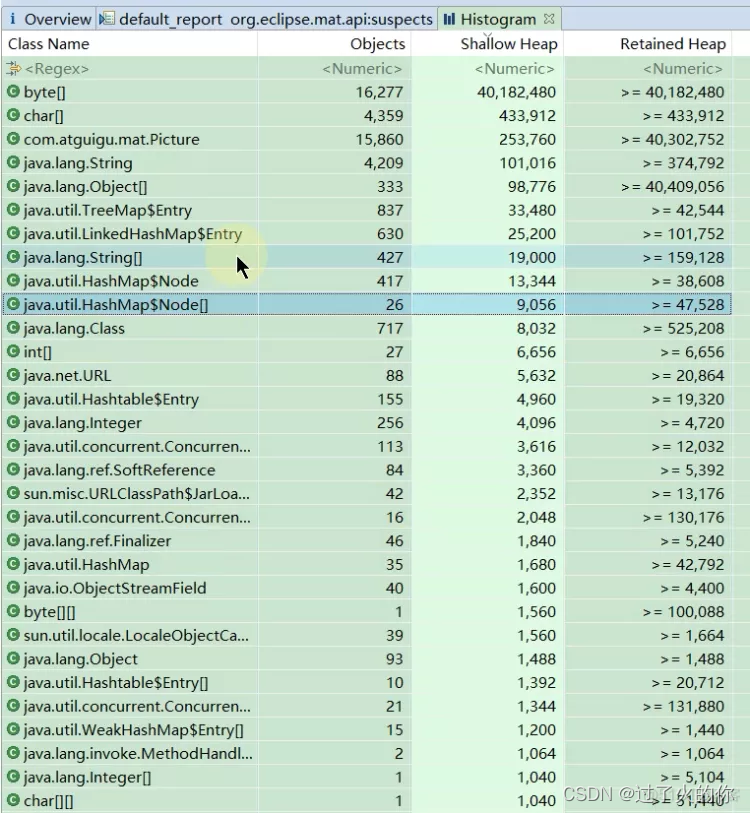
内存中加载的类,Objects是对象的个数,Shallow Heap是占用的浅堆大小,Retained Heap 是占用的深堆的大小。
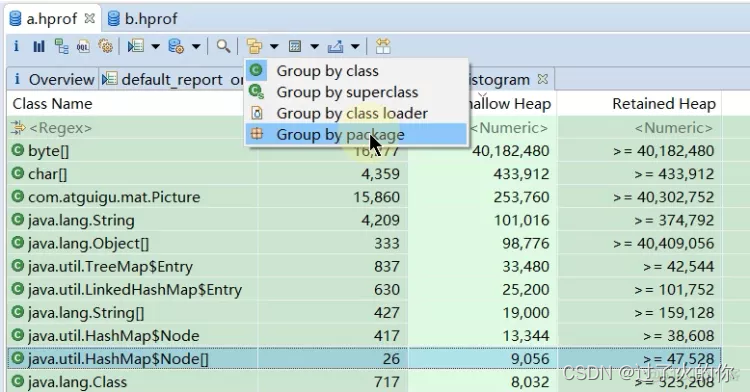
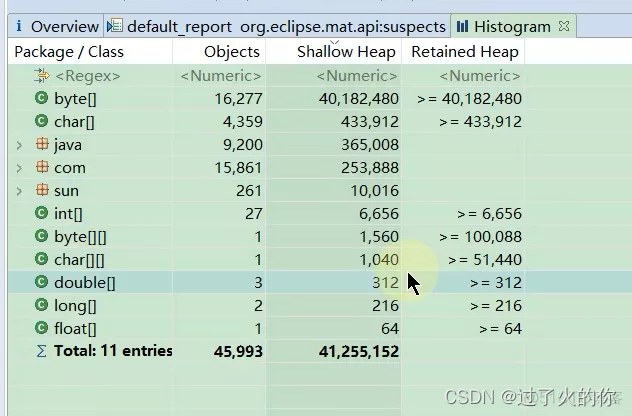
- 包分组
如果显示的类过多的话,也可以用根据包名来分组,分组完了查看就更方便看了。
- 查看目标的gc root
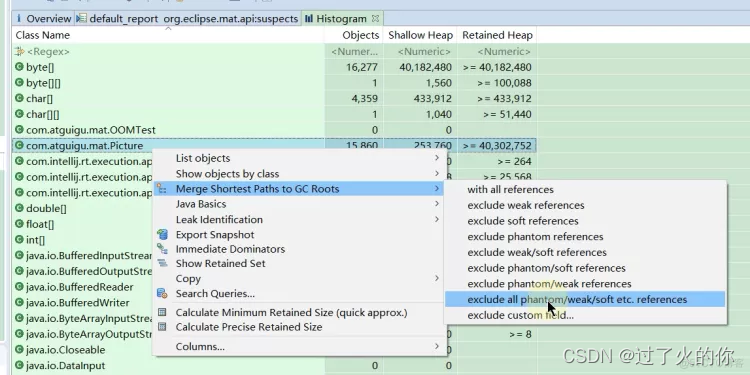
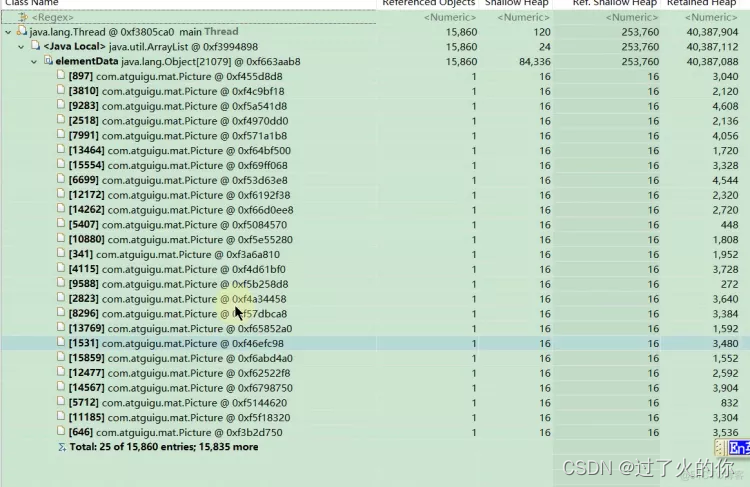
假如说我想看 picture 的gc root ,就可以用 Merge Shortest Paths to GC Roots,最右面可以排除 引用选项,点击查看,就能看到下面 ArrayList对象 0xf663aab8的对象引用了那么多Picture对象,然后你就需要进行分析这些引用是不是合理的,如果不合理的话就尝试着优化它。
- 对比两个hprof文件的 Histogram值
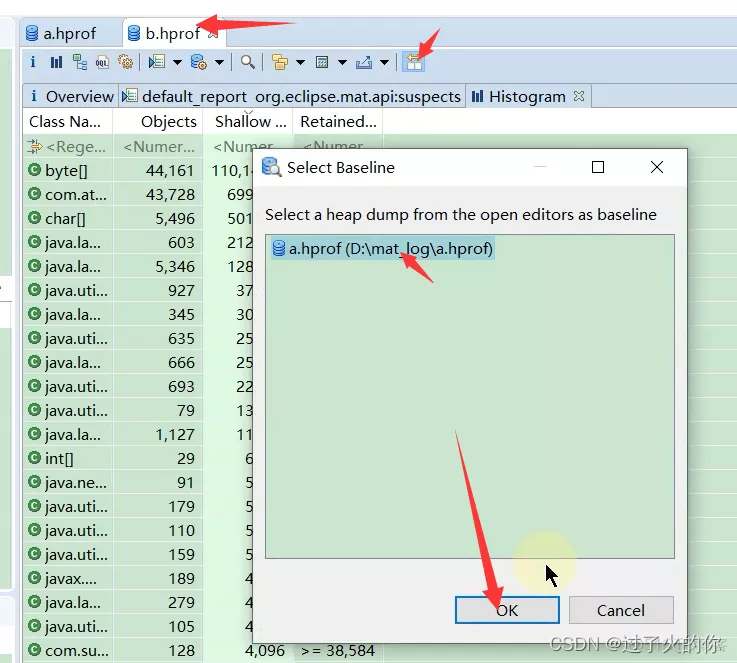
在b.hprof文件里面点击上面的操作,选择a.hprof文件,然后点ok。
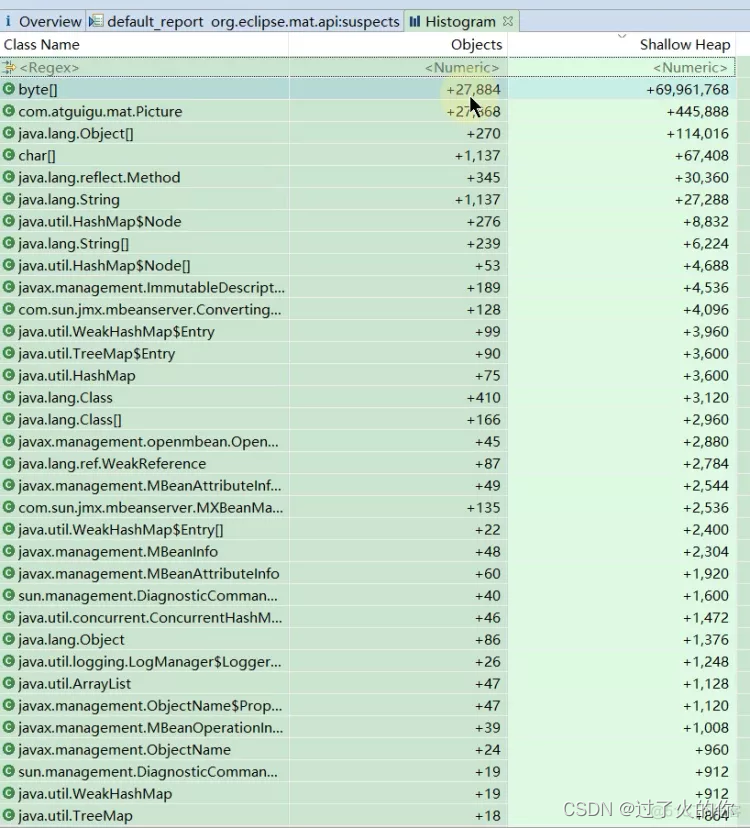
然后就基于b.hprof文件去看和a.hprof的区别,可以看到b.hprof比a.hprof多了很多对象信息 +号代表b.hprof比a.hprof多了。反之 减号 代表少。
比如说第一行byte[] +27884 的意思就是 b.hprof的byte[] 对象比 a.hprof的byte[] 的Objects多了27884个。
通过这个功能你就可以观察指定时间内哪个对象增长了多少,比如说下午三点导出a.hprof文件,然后下午四点导出b.hprof文件,然后通过对比来看看下午四点导出的hprof文件比下午三点导出的hprof文件里面哪个Class Name的指标增加的比较快,这个有可能就是我们要担心的可能会出现oom的类了。
- thread overview
展示线程的概述情况,我们可以查看当前进程中所有的Java的线程的情况,还可以查看当前的线程中栈祯里面保存的局部变量的信息。
点击图标:
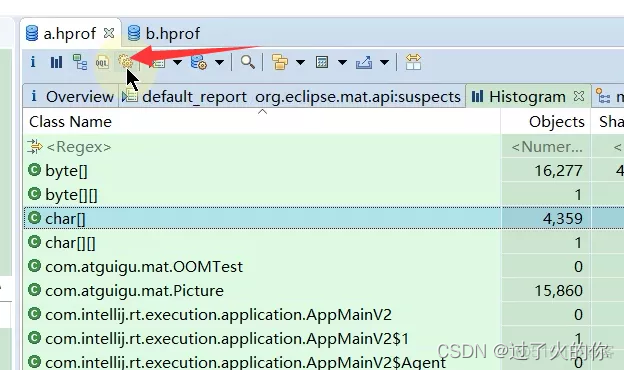
点击之后显示当前dump文件有六个线程
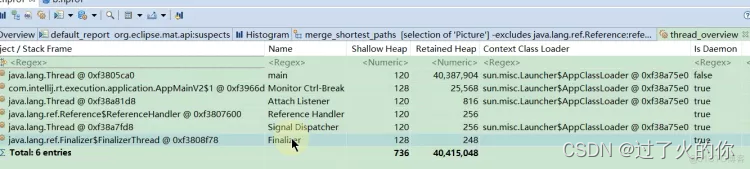
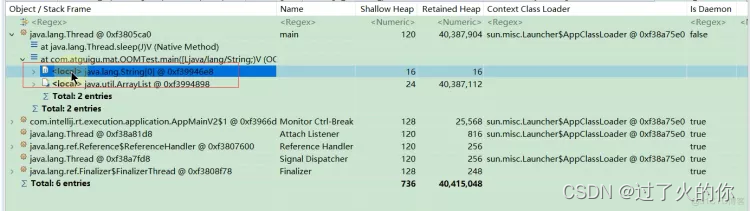
main方法下面的就是main方法在执行的时候的局部变量,局部变量有可能是对象也有可能是基本数据类型,我们就可以怀疑这些对象是否存在内存泄露的问题。
上图String 就是下面这个main方法的形参,ArrayList就是list对象
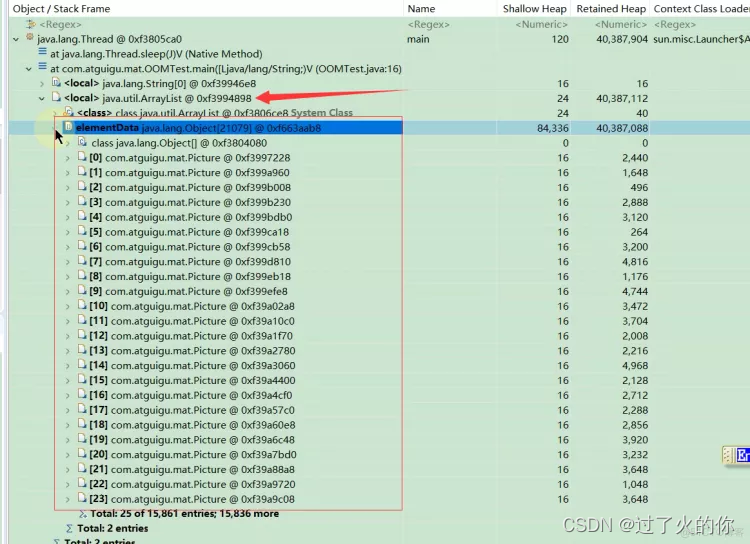
再点看ArrayList 就能看到ArrayList里面有个elementData ,这个elementData 是ArrayList源码里面存数据的数组容器,然后你就会发现elementData类型是Object[]类型,并且elementData里面有总共25个Picture对象。
我们读线程局部变量数据的目的就是为了分析哪些手可能会有泄露的问题。
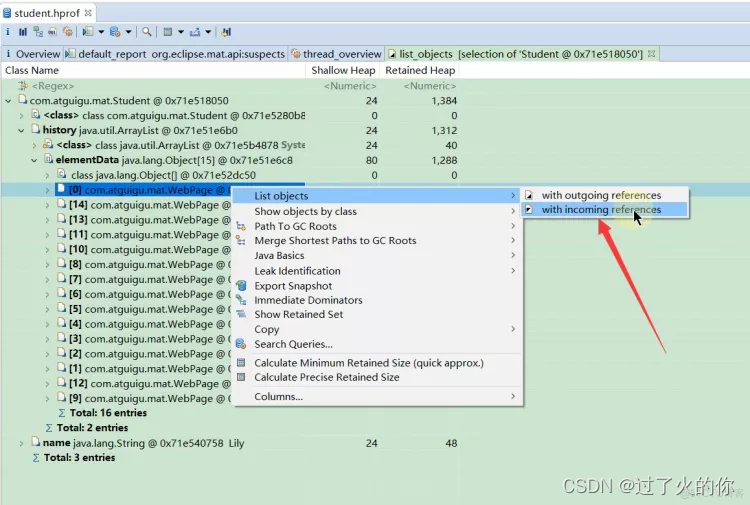
- 查看这个对象引用过谁 和 查看谁引用过这个对象
第一个是出引用(就是这个对象都引用过谁) 第二个是入引用(哪些对象引用过来的)

下面展示的是ArrayList引用了哪些对象
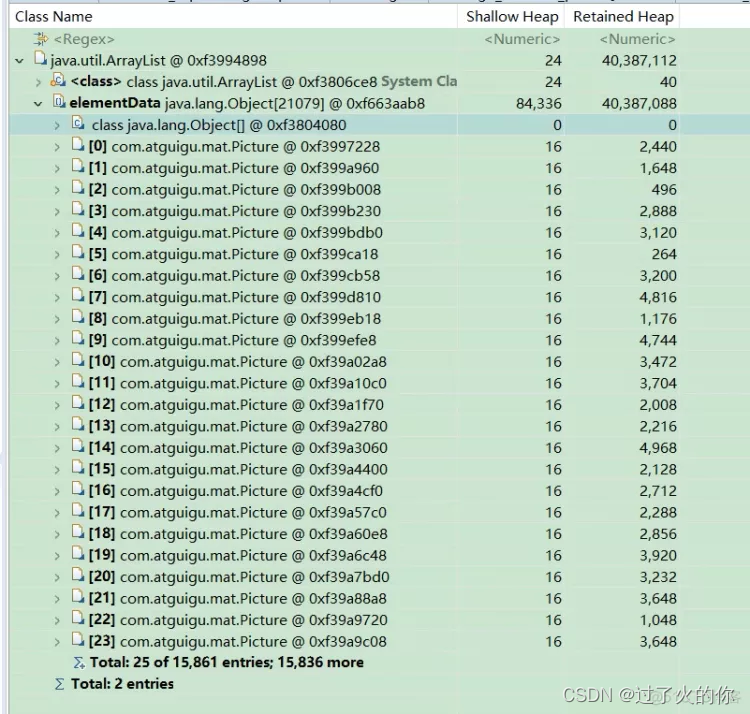
还可以接着看哪些对象引用了这个对象了,来确定为什么他还没被回收,我们就看看这个指针有没有必要存在,如果没有必要存在的话,就改成弱引用等等。
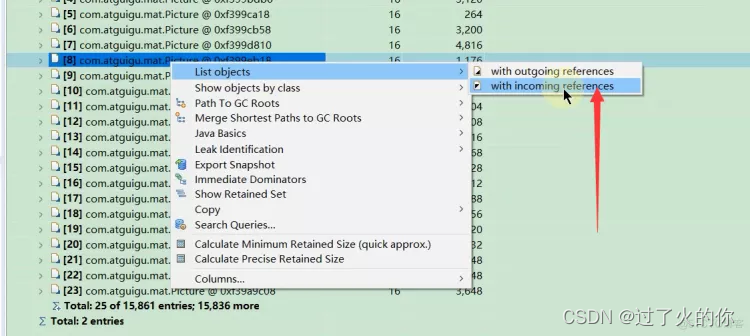
然后查看,只有ArrayList里面的elementData数组引用了这个Picture 0xf399eb18 指针了,这样就没事儿了,当然如果我们发现这个Picture对象除了被ArrayList引用了,还被别的对象引用了,那么我们就要担心了,可能会有内存泄露的问题了。

因为案例代码的ArrayList的生命周期挺短的,main方法执行完了,ArrayList就可以被回收了,只要ArrayList挂掉,那么ArrayList引用的这个Picture也会被挂掉。
当然下面的代码有while (true )死循环,实际情况下代码基本不会有while(true)这种缺心眼的写法,所以main方法结束了ArrayList就可以被回收了。
但是,如果你Picture对象还是被一个生命周期比较长的对象A引用了,ArrayList销毁了,但是这个对象A还在引用Picture对象,导致Picture无法被销毁回收,就会存在泄露。
如果必须要被对象A引用,那么你就可以考虑把这个生命周期比较长的对象A引用Picture对象的引用改成弱引用就可以了。
⭐️⭐️⭐️MAT的支配树
概念
MAT提供了一个称为支配树的对象图。支配树体现了对象实例之间的支配关系(支配关系就是我支配你,你是我管辖的,你做什么都要先经过我,那么就是我支配你。)在对象的引用图中,所有指向对象B的路径都经过对象A,则认为对象A支配对象B。
如果对象A是离对象B最近的一个支配对象,就认为对象A为对象B的直接支配者。
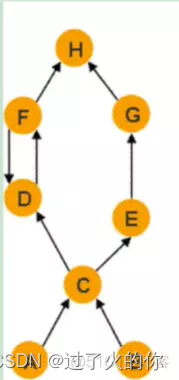
比如说这个H,我要访问H的话,必须要通过C,那么C就是支配者 ,F和G不是,因为你访问H的时候,你可以不经过F,直接去经过G,你访问H的时候,你也可以不经过G,直接经过F。
支配树是基于对象间的引用图所建立的,有下面的基本性质:
对象A的子树(所有被对象A支配(只有通过对象A才能访问的到)的对象集合)表示对象A的保留集(retained set),即深堆。
如果对象A支配对象B,那么对象A的直接支配者也支配对象B,因为对象A支配对象B,那么说明要想经过对象B,就必须要走对象A的链路,那么如果有对象C是对象A的直接支配者,走链路只走对象A,那么这个对象C也是只走对象B。
支配树的边与对象引用图的边不直接对应的。
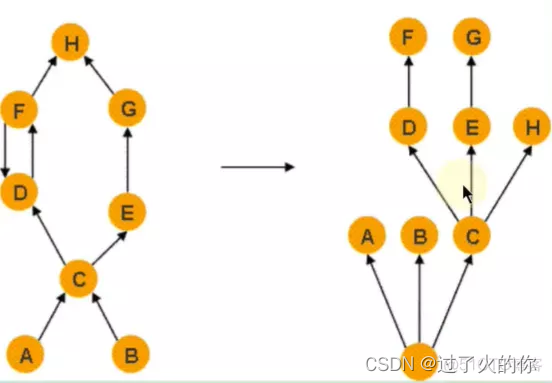
上图所示:左边图标识对象引用图,右边图标识左图所对应的支配树。对象A和B由根对象直接支配,由于在到对象C的路径中,可以经过A,也可以经过B。因此对象C的直接支配者也是根对象。对象F与对象D互相引用,因为到对象F的所有路径必然经过对象D,因此,对象D是对象F的直接支配者。而到对象D的所有路径中,必然经过对象C,即使是从对象F到对象D的引用,从根节点触发,也要经过对象C的,所以对象D的直接支配者为对象C。
同理,对象E支配对象G,到达对象Hd可以通过对象D,也可以通过对象E,因此对象D和E都不能支配对象H,而经过对象C既可以到达D也可以到达E,因此对象C为对象H的直接支配者。
注意:
跟随我一起来理解如何从“对象引用图 —> 支配树”,首先需要理解支配者(如果要到达对象B,毕竟经过对象A,那么对象A就是对象B的支配者,可以想到支配者大于等于1),然后需要理解直接支配者(在支配者中距离对象B最近的对象A就是对象B的直接支配者,你要明白直接支配者不一定就是对象B的上一级,然后直接支配者只有一个),然后还需要理解支配树是怎么画的,其实支配树中的对象与对象之间的关系就是直接支配关系,也就是上一级是下一级的直接支配者,只要按照这样的方式来作图,肯定能从“对象引用图—》支配树”.
在Eclipse MAT工具中如何查看支配树:
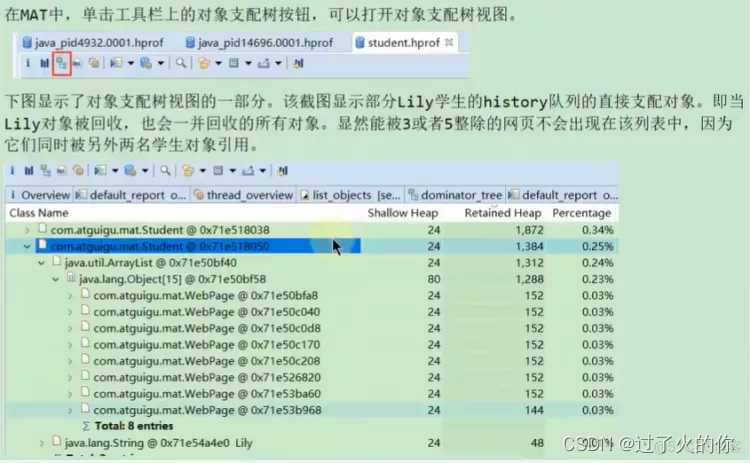
上图中Object数组里面只有8个对象,原因是因为8个对象是这个Student对象自己独有的,如果这个Student对象被垃圾回收了,那么支配树下面的Object数组里面的8个对象也会被垃圾回收掉。
⭐️⭐️⭐️MAT的使用案例
- 执行main方法
启动的时候执行,虚拟机参数添加: -XX:+HeapDumpBeforeFullGC -XX:HeapDumpPath=d:\student.hprof
/*** 有一个学生浏览网页的记录程序,它将记录 每个学生访问过的网站地址。* 它由三个部分组成:Student、WebPage和StudentTrace三个类* 启动的时候执行,虚拟机参数添加: -XX:+HeapDumpBeforeFullGC -XX:HeapDumpPath=d:\student.hprof*/
public class StudentTrace {static List webpages = new ArrayList();public static void createWebPages() {for (int i = 0; i < 100; i++) {WebPage wp = new WebPage();wp.setUrl("http://www." + Integer.toString(i) + ".com");wp.setContent(Integer.toString(i));webpages.add(wp);}}public static void main(String[] args) {createWebPages();//创建了100个网页//创建3个学生对象Student st3 = new Student(3, "Tom");Student st5 = new Student(5, "Jerry");Student st7 = new Student(7, "Lily");for (int i = 0; i < webpages.size(); i++) {if (i % st3.getId() == 0)st3.visit(webpages.get(i));if (i % st5.getId() == 0)st5.visit(webpages.get(i));if (i % st7.getId() == 0)st7.visit(webpages.get(i));}//清理掉webpages.clear();//触发gc垃圾回收System.gc();}
}class Student {private int id;private String name;private List history = new ArrayList<>();public Student(int id, String name) {super();this.id = id;this.name = name;}public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public List getHistory() {return history;}public void setHistory(List history) {this.history = history;}public void visit(WebPage wp) {if (wp != null) {history.add(wp);}}
}class WebPage {private String url;private String content;public String getUrl() {return url;}public void setUrl(String url) {this.url = url;}public String getContent() {return content;}public void setContent(String content) {this.content = content;}
}
- 导入hprof文件开始分析
选择第一个,生成怀疑泄漏的报告
- 查看线程概述
打开hprof文件后点击下面图片的图标来查看线程概述

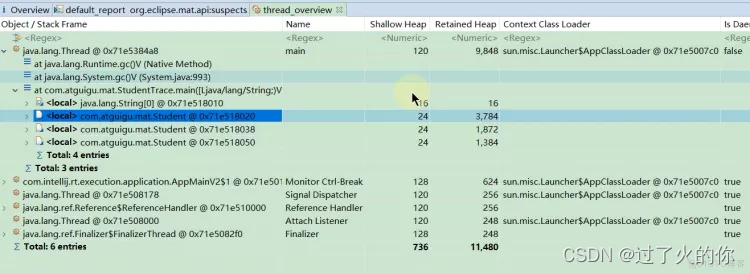
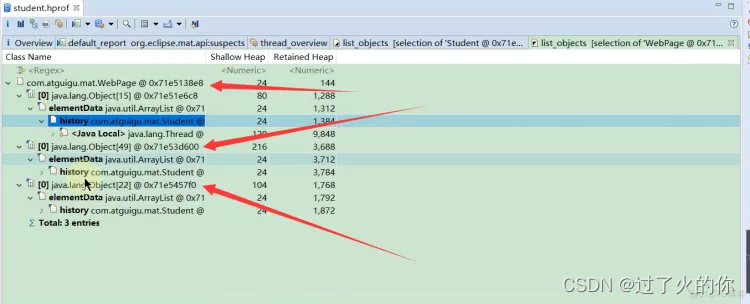
能看到main方法方法里面3个Student对象,三个student的shallow heap(浅堆)大小都是24,但是三个对象的retained heap (深堆)都是不一样的。
第一个student对象如果被回收的话,就会回收3784个字节
第二个student对象如果被回收的话,就会回收1872个字节
第三个student对象如果被回收的话,就会回收1384个字节
为什么从第一个student对象到第三个student对象深堆会越来越少呢???,,因为示例代码往三个student对象里面设置值,因为不同的分支条件不一样,进入第一个分支的多进入第二个分支的稍微少点,进入第三个分支的更少,所以第一个student对象深堆就大, 第二个student对象就稍微少点,第三个student对象就更少了。
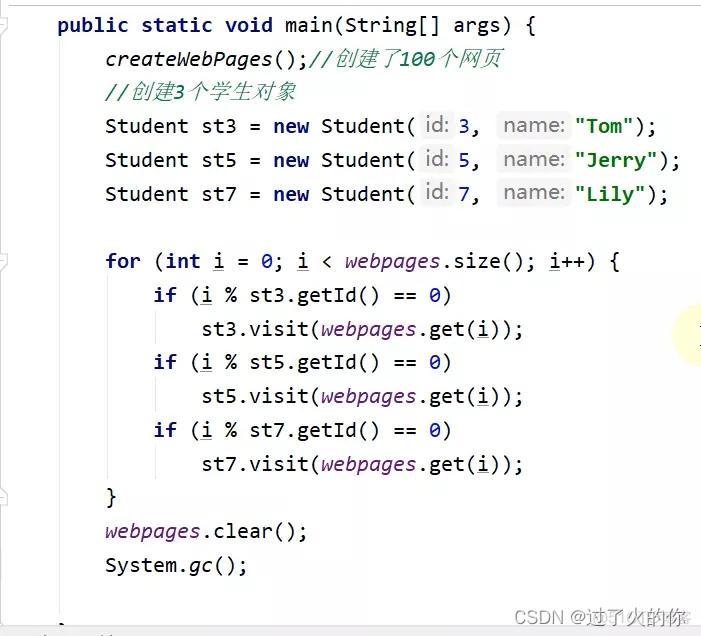
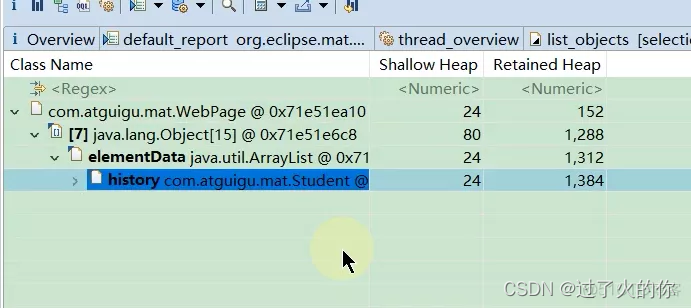
- 深堆数量是怎么算出来的
以最下面的student对象为例子,history深堆大小是1288,打开history这个ArrayList之后,发现ArrayList内部的elementData数组有一堆元素,再打开elementData数组之后,就能看到elementData这个数组里面有一堆WebPage对象了。
elementData数组的浅堆是80个字节,而elementData数组中的所有WebPage对象的深堆之和是1208个字节,所以加在一起就是elementData数组的深堆之和,也就是1288个字节。
如果elementData数组要是被回收的话,只能回收掉1288个字节,原因是有一些WebPage还被别的student所引用,15个WebPage对象,每个对应152字节, 15*152=2280字节,即2280位elementData的实际大小,但是为什么elementData的深堆是1288呢?
因为能被7整除且能被3整除,以及能被5整除的数值有: 0 21 35 42 63 84 70 ,总共七个数,这七个数儿对应的WebPage不只是被这个student独享,还被其它的student对象引用了,这些是不能计算深堆里面的,,7*152就是1064个字节 。
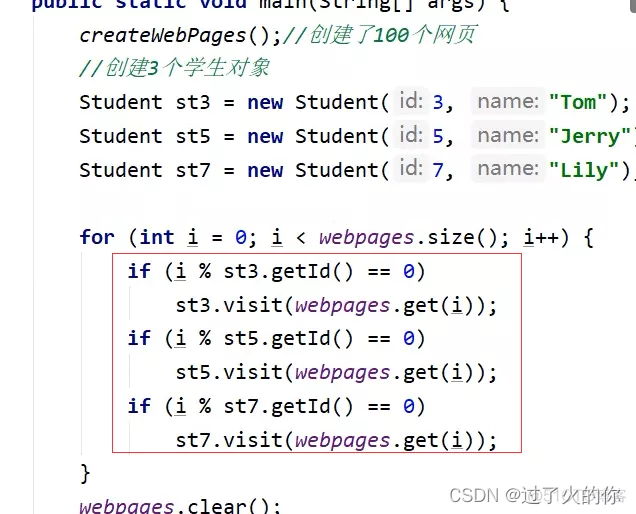
2280-1064 =1216 , 是1216这个数字,但是1216和显示的1288还是不一样,为什么这样呢?还差72个字节,这72个字节是什么呢? 因为elementData这个Object的数组引用也要占据一些空间

虽然elementData存了15个元素,但是不代表elementData数组长度就是15。数组默认长度是10,如果装不下了就扩容成1.5倍,就变成了15了,数组长度15就能被第三个student对象装得下。
15个elementData的元素,每个元素占用4个字节,15*4 = 60字节。
60+8个对象头的字节数+数组自己长度计数(4个字节) = 72字节
所以这就匹配上了。
因为第三个student对象在触发gc的时候只能有8个对象被回收掉,每个占用152个字节,8个就是1216。
1216再加上elementData元素的字节+对象头的字节数+数组自己长度计数 就是 1288个字节。
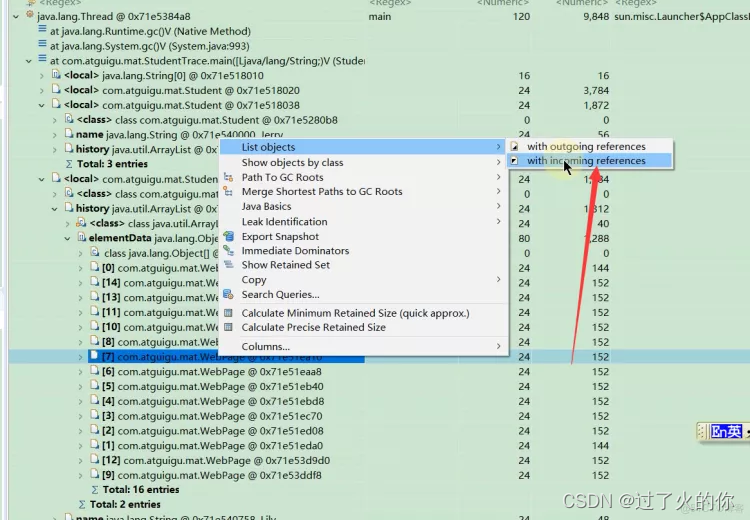
- 查看某个对象是否被别的对象引用
通过这个功能可以查看某个对象是否能被GC清理掉,是否存在内存泄露问题
结果发现这个对象被三个对象引用了。
那么我们查看另外一个对象还有没有被其它对象引用
下图发现只有他自己引用了这个对象,那么当他自己被回收了之后,这个对象也会被回收
3.4.4 案例: Tomcat堆溢出分析
说明
tomcat是最常用的Java Servlet 容器之一,同时也可以单独做为web服务器使用,tomcat本身是用Java语言实现的,并且运行在Java虚拟机之上,在大规模请求时,tomcat有可能会因为无法承受压力而发生内存溢出错误。
这里根据一个被压垮的tomcat堆快照文件,来分析tomcat在奔溃时候的内部情况。
导入hprof文件
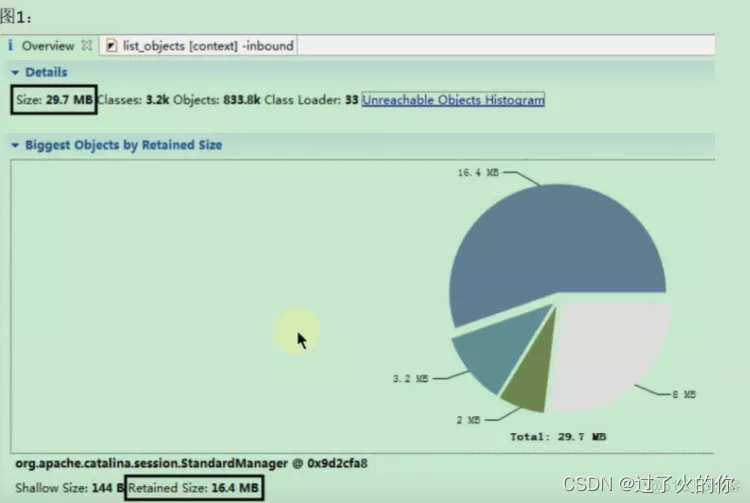
堆大小有29.7MB,类一共有3.2K个,对象个数有833.8K个,类加载器有33个。
org.apache.catalina.session.StandardManager@0x6d2cfa8 这对象占用了16.4MB空间,0x6d2cfa8 的对象这个就是我们所谓的最大的对象
分析oom内存溢出的话,首先就是要分析占用最大对象,

鼠标左键查看这个最大的对象引用了哪些结构
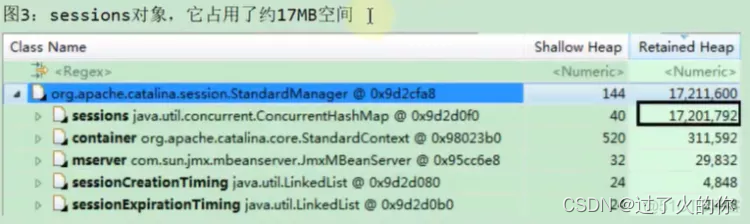
发现 StandardManager里面有个sessions占用了17mb大概,占用很大
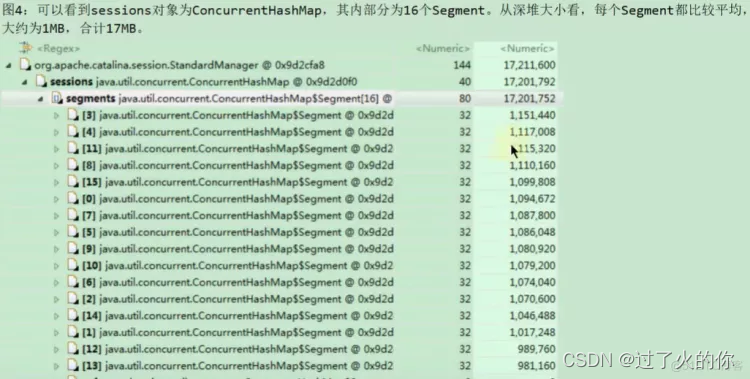
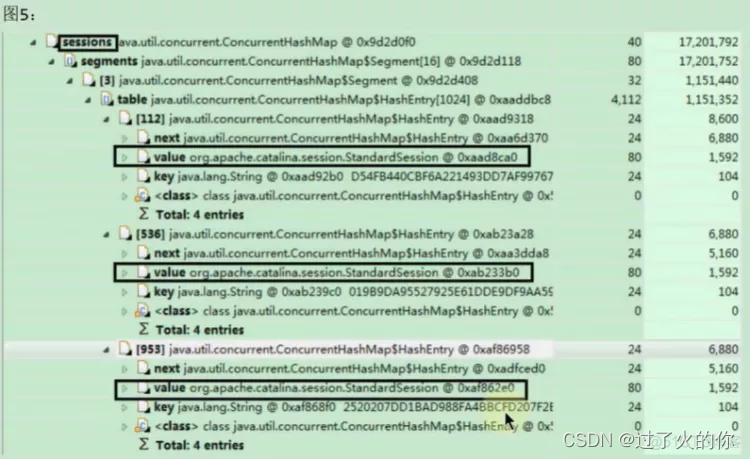
发现有那么多StandardSession,怀疑是tomcat短期之内收到了大量的Session导致的
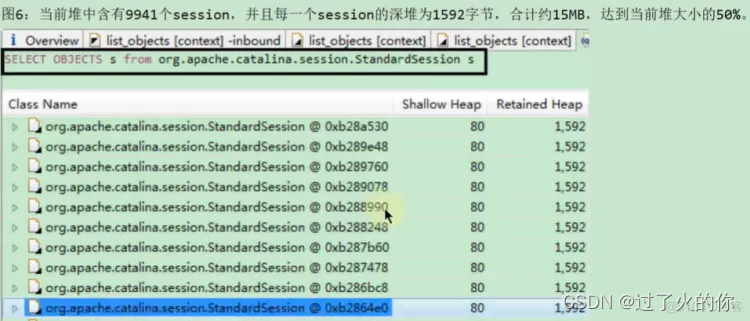
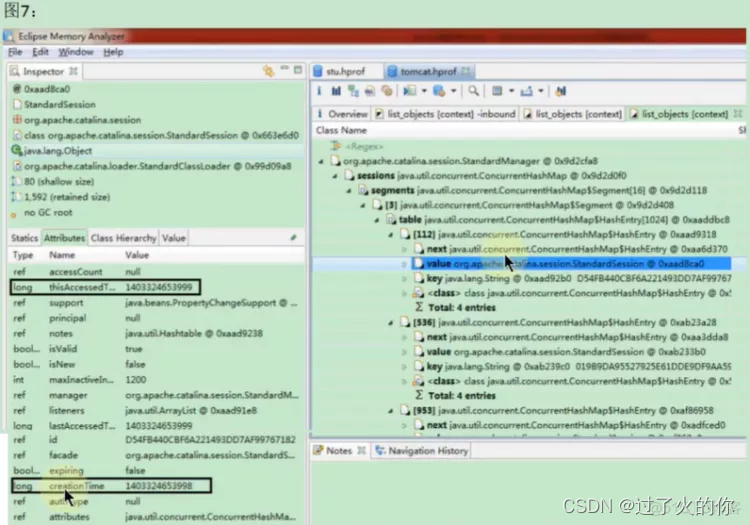
随便选一个session对象,查看左边的信息,上面是创建时间,下面是结束的时间,这两个时间做一个差值,就相当于这个session对象在内存中出现的时间了。
这两个时间就相差了一毫秒,通过这两个时间就能获取到相关的信息了。
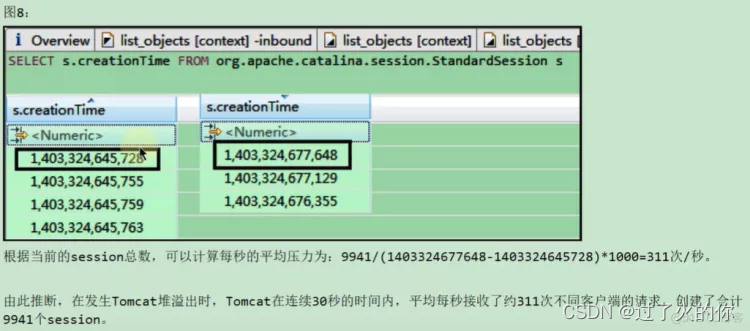
写OQL语句,查看StandardSession,发现第一个StandardSession的创建时间和最后一个StandardSession的创建时间的差值,右边的减去左边的,再 *1000 , 然后再被9941个session对象除掉,结果发现一秒得到311个对象。
由此推断,tomcat发生堆溢出时,tomcat在连续的30秒内,平均每秒接收了大概311次不同的客户端请求,导致创建了9941个session,结果导致tomcat发生了堆溢出了。
3.4.5 内存泄露补充
- 内存泄露理解(Memory leak)与分类
何为内存泄露?
可达性分析算法来判断对象是否是不在使用的对象,本质都是判断对象是否还被引用。那么对于这种情况下,由于代码的实现不同就会出现很多内存泄露问题。(让JVM误以为此对象还在引用中,无法回收,造成内存泄露)
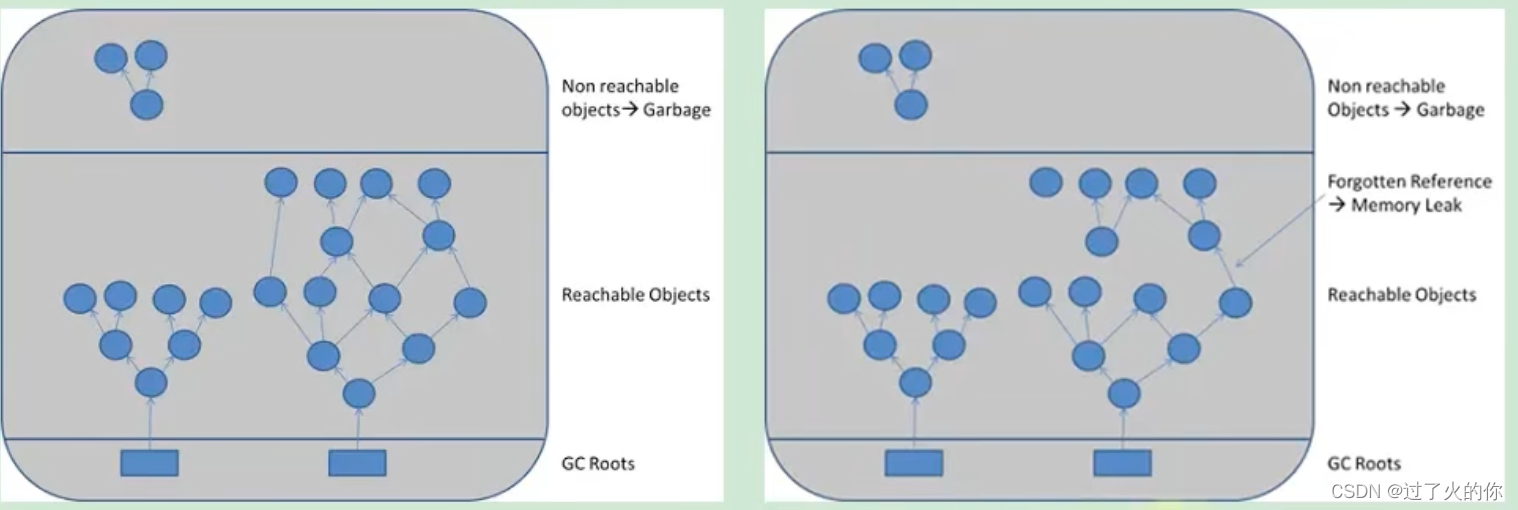
内存泄露的理解
严格来说,只有对象不会再被程序用到了,但是GC又不能回收他们的情况,才叫内存泄露。
但实际情况很多时候一些不太好的实践(或疏忽)会导致对象的生命周期变得很长甚至导致OOM,也可以叫做广泛意义上的内存泄露。
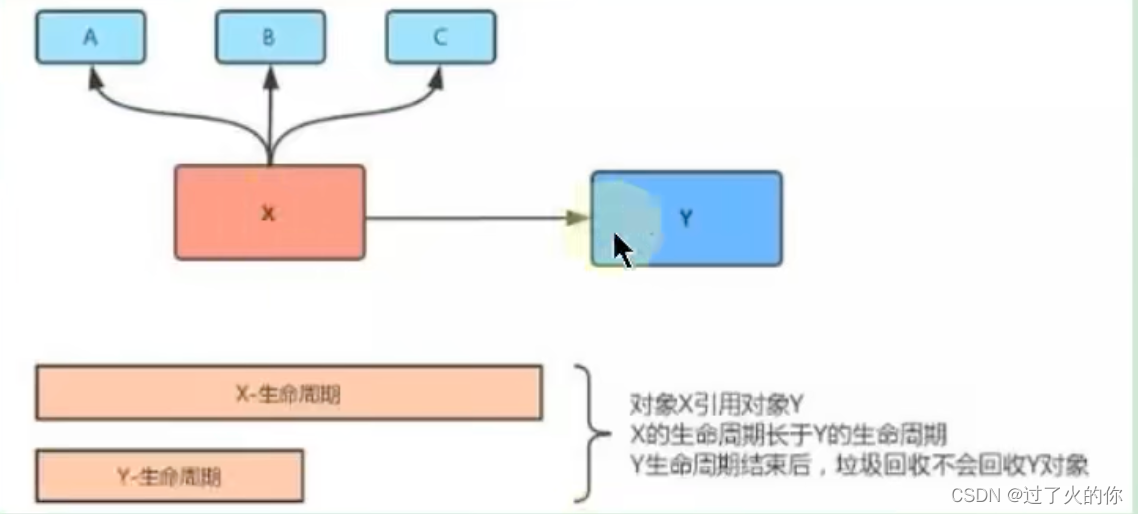
内存泄露与内存溢出的关系
- 内存泄露(memory leak)
申请了内存用完了不释放,通俗的讲就是【占着茅坑不拉屎】
- 内存溢出(out of memory)
申请内存时,没有足够的内存使用。
泄露的分类
- 经常发生:发生内存泄露的代码会被多次执行,每执行一次,泄露一块内存。
- 偶然发生:在某些特定的情况下才会发生。
- 一次性:发生内存泄露的方法只会执行一次。
- 隐式泄露:一直占着内存不释放,直到执行结束,严格的说这个不算内存泄露,因为最终释放掉了,但是如果执行时间特别长,也可能导致内存耗尽。
- 内存泄露8种情况
- 静态集合类
静态集合类,如HashMao、linkedList等,如果这些容器是静态的,那么他们的生命周期和JVM是一致的,则容器中的对象在程序结束之前将不能被释放,从而造成内存泄露。简单而言,长生命周期的对象持有短生命周期对象的引用,尽管短生命周期的对象不再使用,但是因为长生命周期对象持有它的引用而导致不能被回收。
package jvm.classloader.jvm;import java.util.ArrayList;
import java.util.List;public class MemoryLeak1 {private static List list = new ArrayList();public void oomTest() {Object obj = new Object();list.add(obj);}
}
- 单例模式
单例模式和静态集合导致的内存泄漏类似,因为单例的静态特性,它的生命周期和JVM的生命周期一样长,所以如果单例对象持有外部对象的引用,那么这个外部对象也不会被回收,那么就会造成内存泄露。
- 内部类持有外部类
内部类持有外部类,如果一个外部类的实例对象的方法返回了一个内部类的实例对象。这个内部类对象被长期引用了,即使那个外部类实例对象不再被使用,但是由于内部类持有外部类的实例对象,这个外部类对象就不会被垃圾回收,也会造成内存泄露。
- 各种连接,如数据库连接、网络连接和IO连接等
在对数据库进行操作的过程中,首先要建立与数据库之间的连接,需要调用close方法来释放与数据库之间的连接。只有连接被关闭后,垃圾回收器才会回收对应的对象。
否则如果在访问数据库的过程中,对Connection、Statement等不显性的关闭,将会造成大量对象无法被回收,从而造成内存泄露。
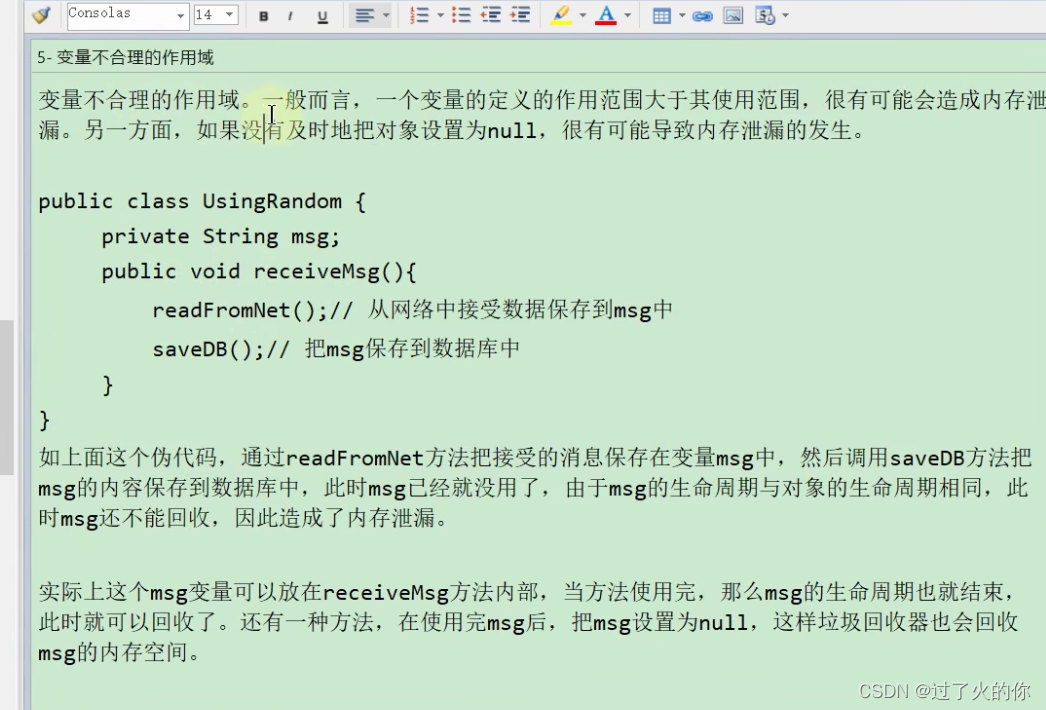
- 变量不合理的作用域
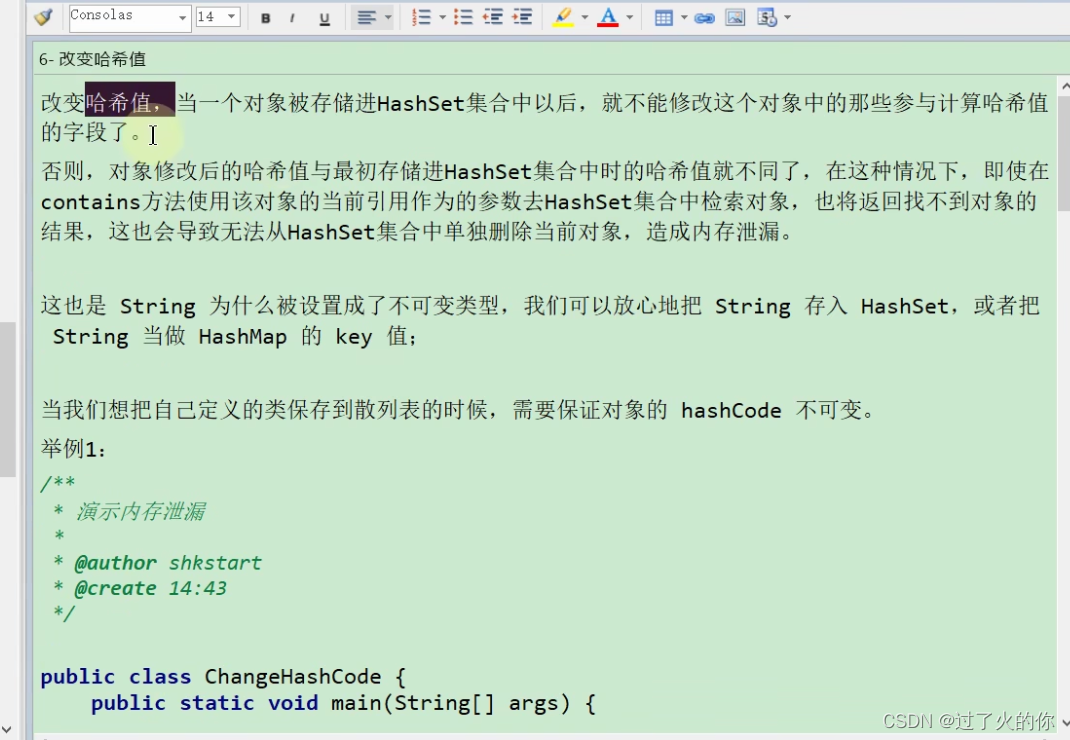
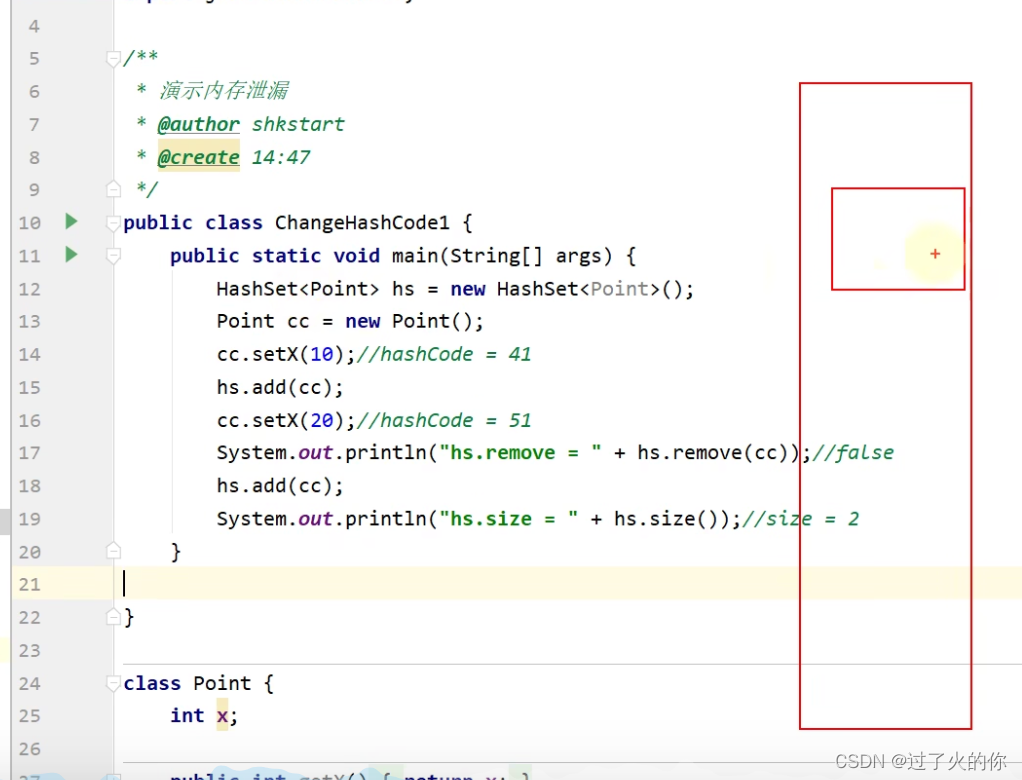
- 改变哈希值

- 缓存泄露
内存泄露的另一个常见的来源是缓存,一旦你把对象引用放入到缓存中,他就很容易被遗忘。比如:之前项目在一次上线的时候,应用启动极慢直到夯死,就是因为代码中会加载一个表中的数据到缓存(内存)中,测试环境只有几百条数据,但是生产环境有几百万的数据。
对于这个问题,可以使用WeakHashMap代替缓存,此Map的特点是,当除了自身有对key的引用外,此key没有其他引用,那么此map会自动丢弃此值。
package jvm.classloader.jvm;import java.sql.Time;
import java.util.HashMap;
import java.util.Map;
import java.util.WeakHashMap;
import java.util.concurrent.TimeUnit;public class MapTest {static Map wMap = new WeakHashMap<>();static Map map = new HashMap();public static void main(String[] args) {init();testWeakHashMap();testHashMap();}private static void init() {String ref1 = new String("object1");String ref2 = new String("object2");String ref3 = new String("object3");String ref4 = new String("object4");wMap.put(ref1, "cacheObject1");wMap.put(ref2, "cacheObject2");map.put(ref3, "cacheObject3");map.put(ref4, "cacheObject4");System.out.println("String 引用ref1,ref2,ref3,ref4 消失");}private static void testWeakHashMap() {System.out.println("WeakHashMap GC前");for (Object o : wMap.entrySet()) {System.out.println(o);}try {System.gc();TimeUnit.SECONDS.sleep(5);} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println("WeakHashMap GC后");for (Object o : wMap.entrySet()) {System.out.println(o);}}private static void testHashMap() {System.out.println("HashMap GC前");for (Object o : map.entrySet()) {System.out.println(o);}try {System.gc();TimeUnit.SECONDS.sleep(5);} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println("HashMap GC后");for (Object o : map.entrySet()) {System.out.println(o);}}}
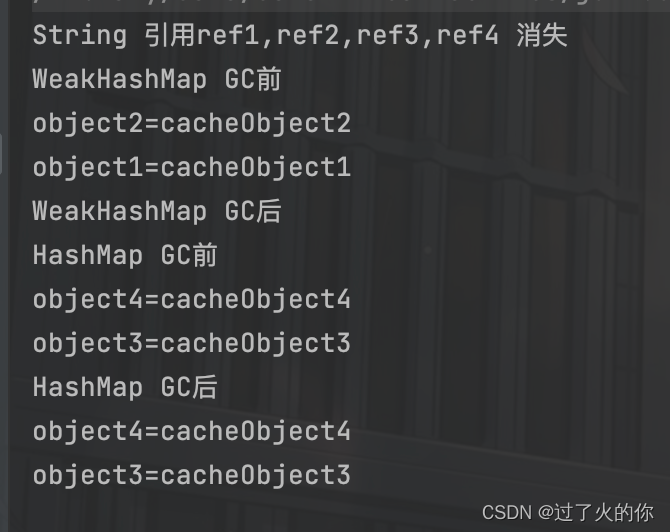
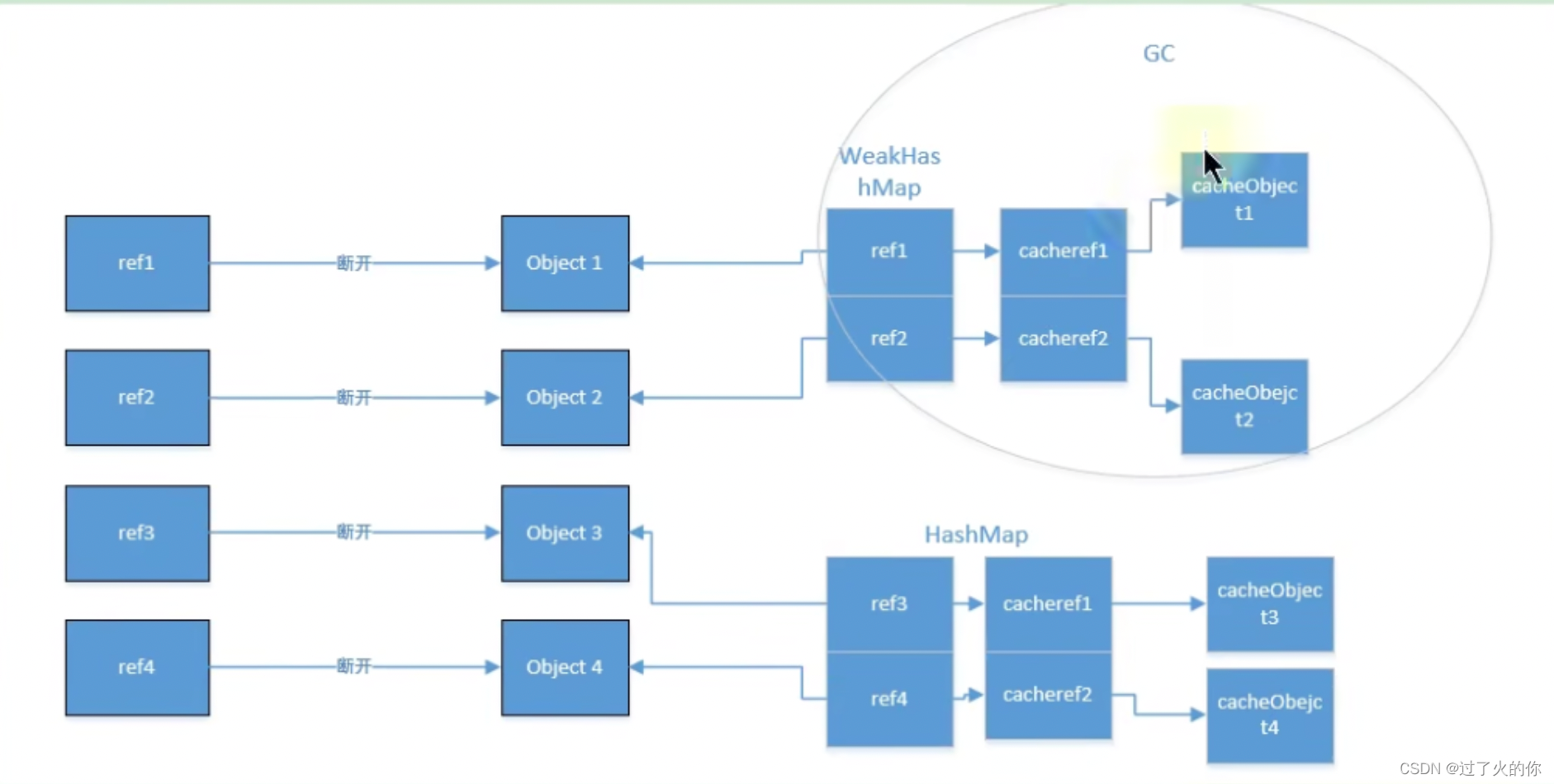
上面代码合图示主要演示了WeakHashMap如何自动释放缓存对象,当init函数执行完成后,局部变量字符串weakd1,weakd2,d1,d2都会消失,此时只有静态map中保存对字符串对象的引用,可以看到,GC之后,HashMap的没有被回收,而WeakHashMap里面的缓存被回收了。
- 监听器和回调
内存泄露另外常见来源是监听器和其他回调,如果客户端在你实现的API中注册回调,却没有显示的取消,那么就会聚集。
需要确保回调立即被当做垃圾回收的最佳方法是只保存它的弱引用,例如将它们保存成为WeakHashMap中的键。
- 内存泄露案例分析
package jvm.classloader.jvm;import java.util.Arrays;
import java.util.EmptyStackException;public class Stack {private Object[] elements;private int size = 0;private static final int DEFAULT_INITIAL_CAPACITY = 16;public Stack() {elements = new Object[DEFAULT_INITIAL_CAPACITY];}/*** 入栈** @param e*/public void push(Object e) {ensureCapacity();elements[size++] = e;}private void ensureCapacity() {if (elements.length == size) {elements = Arrays.copyOf(elements, 2 * size + 1);}}/*** 出栈** @return*/public Object pop() {if (size == 0) {throw new EmptyStackException();}return elements[--size];}/*** 出栈** @return*/
// public Object pop() {
// if (size == 0) {
// throw new EmptyStackException();
// }
// Object result = elements[--size];
// elements[size] = null;
// return result;
// }}分析:
上述程序没有明显的错误,但是下面这段程序有一个内存泄露,随着GC活动的增加,或者内存占用的不断增加,程序性能的降低就会表现出来,严重时可能导致内存泄露,但是这种失败情况相对较少。
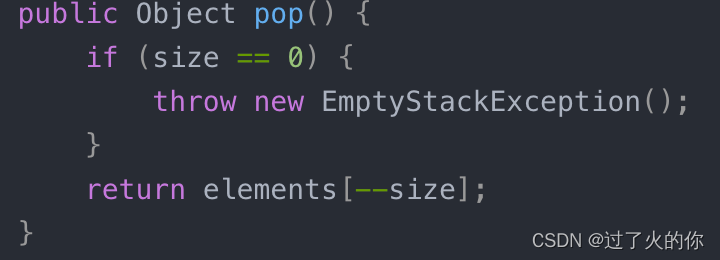
当进行大量的pop操作时,由于引用未进行置空,gc是不会释放的。如果栈先增长,再收缩,那么从栈中弹出的对象将不会被当做垃圾回收,即使程序不再使用栈中的这些对象,他们也不会回收,因为栈中仍然保留着这些对象的引用,俗称过期引用,这个内存泄露很隐蔽。
3.4.6 支持使用OQL语言查询对象信息
MAT支持一种类似SQL的查询语句OQL(Object Query Language)。OQL使用类SQL语法,可以从堆内进行对象的查找和筛选。
- Select 子句
在MAT中,select子句的格式和SQL基本一致,用于指定要显示的列。select子句中可以使用*,查看结果对象的引用实例(相当于outgoing references)。
SELECT * FROM java.util.Vector v
使用 OBJECTS 关键字,可以讲返回结果集中的项以对象的形式显示。
SELECT OBJECTS v.elementData FROM java.util.Vector v
在select子句中,使用 AS RETAINED SET 关键字可以得到所有对象的保留集。
SELECT AS RETAINED SET * FROM java.util.Vector
DISTINCT 关键字用于在结果集中去除重复对象。
SELECT DISTINCT OBJECTS classof(v) FROM java.util.Vector v
- From 子句
From子句用于执行查询范围,可以指定类名、正则表达式或者对象地址。
使用正则表达式,限定搜索范围,输出所有com.test包下的所有类的实例
SELECT * FROM “com \ .test \ …*”
使用类的地址进行搜索,好处是可以区分被不同类加载器加载的同一类型。
SELECT * FROM 0x37a0b4d
- Where子句
Where子句用于指定OQL的查询条件。OQL查询将只返回满足Where子句指定条件的对象。
where子句的格式与传统SQL极为相似。
下例返回长度大于10的char数组。
SELECT * FROM char[] s WHERE s.@length>10
下例返回包含“java”子字符串的所有宇符串,使用“LIKE”操作符,“LIKE”操作符的操作参数为正则表达式。
SELECT * FROM java.lang.String s WHERE toString(s) LIKE “. * java. *”
下例返回所有value域不为null的字符串,使用“=”操作符。
SELECT * FROM java.lang.String s where s. value != null
Where子句支持多个条件的AND、OR运算。下例返回数组长度大于15,并且深堆大于1000字节的所有Vector对象。
SELECT * FROM java.util.Vector v WHERE v.elementData.@length>15 AND v.@retainedHeapsize>1000
- 内置对象与方法
OQL中可以访问堆内对象的属性,也可以访问堆内代理对象的属性。访问堆内对象的属性时,格式如下:
[< alias >. ] < field >.< field >.< field >
其中alias为对象名称。
访问java.io.File对象的path属性,并进一步访问path的value属性:
SELECT toString(f.path. value ) FROM java.io.File f
下例显示了String对象的内容、objectid和objectAddress。
SELECT s. toString(), s.@objectId, s.@objectAddress FROM java.lang.String s
下例显示java.util.Vector内部数组的长度。
SELECT v.elementData.@length FROM java.util.Vector v
下例显示了所有的java.util.Vector对象及其子类型
SELECT * from INSTANCEOF java.util.Vector
3.5 JProfiler
3.5.1 基本概述
- 介绍
在运行java的时候有时候想测试运行时占用内存情况,这时候就需要使用测试工具查看了。在eclipse里面有 Eclipse Memory Analyzer tool (MAT)插件可以测试。而在IDEA中也有这么一个插件,就是JProfiler。
Jprofiler 是由 ej-technologies 公司开发的一款Java 应用性能诊断工具。功能强大,但是收费。
下载地址:https://www.ej-technologies.com/download/jprofiler/version_100
- 特点
- 使用方便、界面操作友好 (简单目强大)
- 对被分析的应用影响小(提供模板)
- CPU,Thread,Memory分析功能尤其强大
- 支持对jdbc,nosql,jsp,servlet, socket等进行分析
- 支持多种模式(离线,在线)的分析
- 支持监控本地、远程的JVM
- 跨平台,拥有名种操作系统的安装版本
- 主要功能
-
方法调用,对方法调用的分析可以帮助您了解应用程序正在做什么,并找到提高其性能的方法
-
内存分配,通过分析堆上对象、引用链和垃圾收集能帮您修复内存泄漏问题,优化内存使用
-
线程和锁,JProfiler提供多种针对线程和锁的分析视图助您发现多线程问题
-
高级子系统,许多性能问题都发生在更高的语义级别上。例如,对于JDBC调用,您可能希望找出执行最慢的SQL语句。JProfiler支持对这些子系统进行集成分析
3.5.2 安装与配置
安装与配置略,请参照网上教程(不同操作系统、不同安装版本不同)。
3.5.3 具体使用
- 数据采集方式:JProfier 数据采集方式分为两种:Sampling(样本采集)和 Instrumentation(重构模式)
- Instrumentation
这是 JProfiler 全功能模式。在 class 加载之前,JProfier 把相关功能代码写入到需要分析的 class 的 bytecode 中,对正在运行的 jvm 有一定影响。
优点:功能强大。在此设置中,调用堆栈信息是准确的。
缺点:若要分析的 class 较多,则对应用的性能影响较大,CPU 开销可能很高(取决于 Filter 的控制)。因此使用此模式一般配合 Filter 使用,只对特定的类或包进行分析
- Sampling
类似于样本统计,每隔一定时间(5ms)将每个线程栈中方法栈中的信息统计出来。
优点:对 CPU 的开销非常低,对应用影响小(即使你不配置任何 Filter)
缺点:一些数据/特性不能提供(例如:方法的调用次数、执行时间)
注:JProfiler 本身没有指出数据的采集类型,这里的采集类型是针对方法调用的采集类型。因为JProfiler 的绝大多数核心功能都依赖方法调用采集的数据,所以可以直接认为是 JProfiler 的数据采集类型。
-
遥感监测 Telemetries
-
内存视图 Live Memory
- 所有对象 All Objects:显示所有加载的类的列表和在堆上分配的实例数。只有 Java 1.5(JVMTI)才会显示此视图。
- 记录对象 Record Objects:查看特定时间段对象的分配,并记录分配的调用堆栈。
- 分配访问树 Allocation Call Tree:显示一棵请求树或者方法、类、包或对已选择类有带注释的分配信息的 J2EE 组件。
- 分配热点 Allocation Hot Spots:显示一个列表,包括方法、类、包或分配已选类的 J2EE 组件。你可以标注当前值并且显示差异值。对于每个热点都可以显示它的跟踪记录树。
- 类追踪器 Class Tracker:类跟踪视图可以包含任意数量的图表,显示选定的类和包的实例与时间。
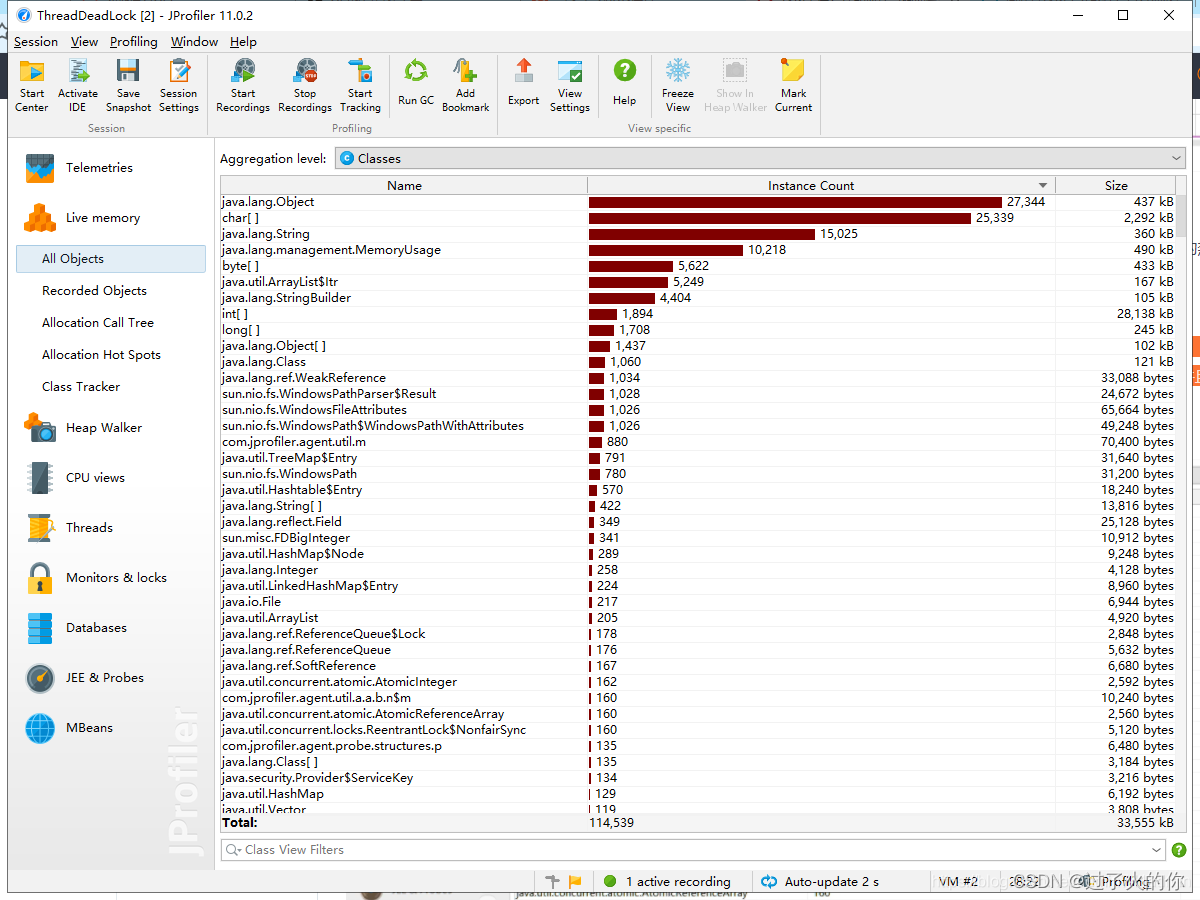
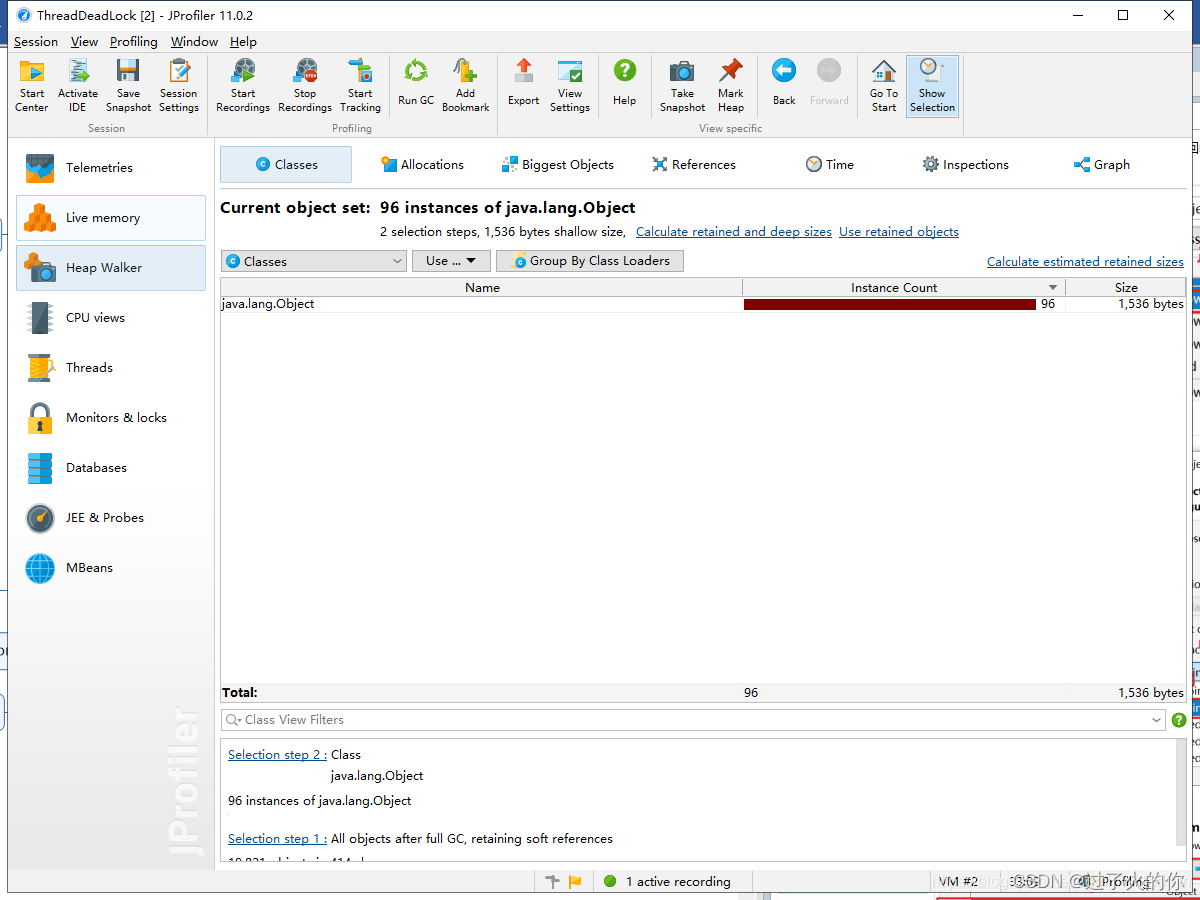
4. 堆遍历 heap walker
- cpu视图 cpu views

- 线程视图 threads

- 监视器&锁 Monitors&locks
- 死锁探测图表 Current Locking Graph:显示 JVM 中的当前死锁图表。
- 目前使用的监测器 Current Monitors:显示目前使用的监测器并且包括它们的关联线程。
- 锁定历史图表 Locking History Graph:显示记录在 JVM 中的锁定历史。
- 历史检测记录 Monitor History:显示重大的等待事件和阻塞事件的历史记录。
- 监控器使用统计 Monitor Usage Statistics:显示分组监测,线程和监测类的统计监测数据
3.6 Arthas
3.6.1 基本使用
官方地址:https://arthas.aliyun.com/doc/quick-start.html
Arthas 是 Alibaba 开源的 Java 诊断工具,深受开发者喜爱。在线排查问题,无需重启;动态跟踪 Java 代码;实时监控 JVM 状态。Arthas 支持 JDK 6 +,支持 Linux/Mac/Windows,采用命令行交互模式,同时提供丰富的 Tab 自动补全功能,进一步方便进行问题的定位和诊断。当你遇到以下类似问题而束手无策时,Arthas 可以帮助你解决:
- 这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
- 我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
- 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
- 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
- 是否有一个全局视角来查看系统的运行状况?
- 有什么办法可以监控到 JVM 的实时运行状态?
- 怎么快速定位应用的热点,生成火焰图?
3.6.2 安装与启动

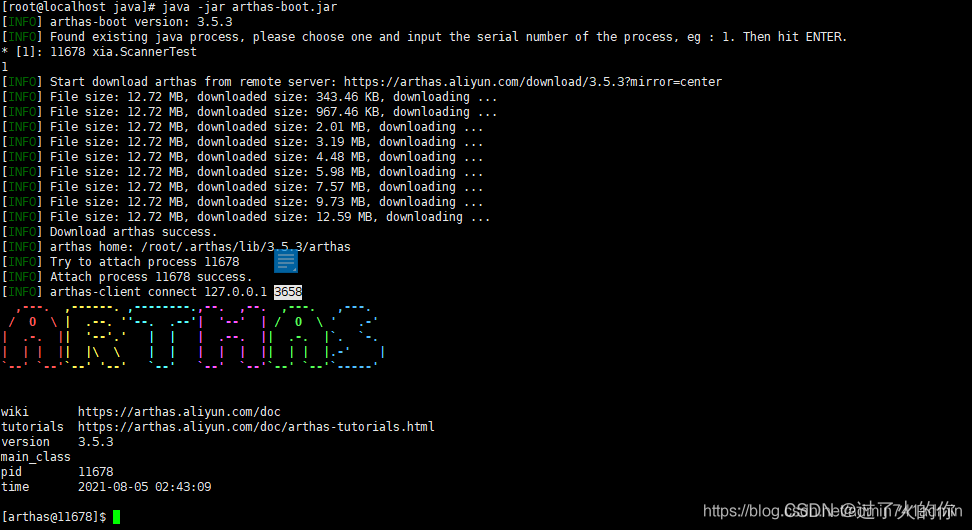
3.6.3 相关诊断指令
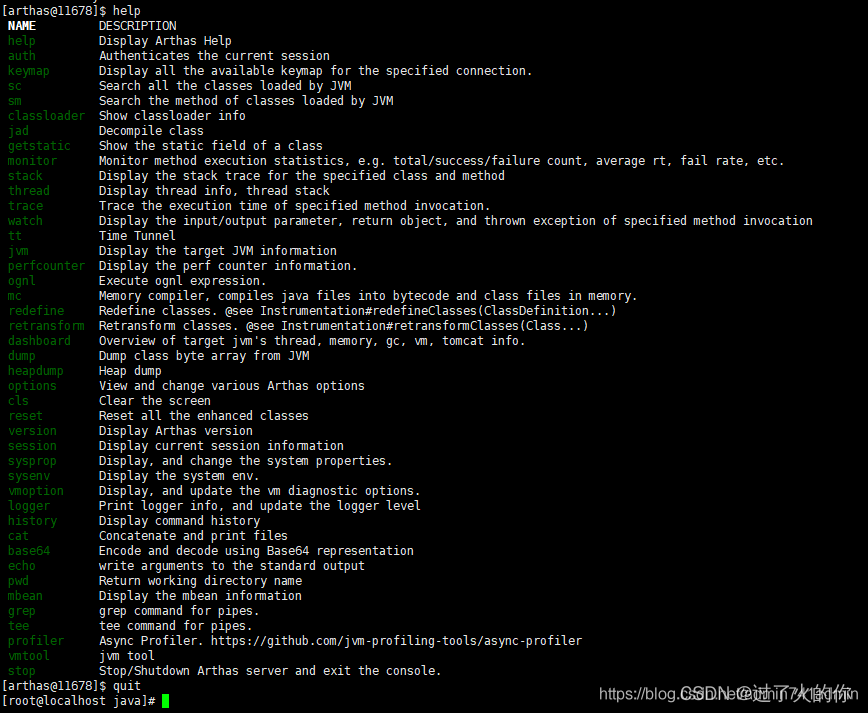
- 基础指令
- quit/exit 退出当前 Arthas客户端,其他 Arthas喜户端不受影响
- stop/shutdown 关闭 Arthas服务端,所有 Arthas客户端全部退出
- help 查看命令帮助信息
- cat 打印文件内容,和linux里的cat命令类似
- echo 打印参数,和linux里的echo命令类似
- grep 匹配查找,和linux里的gep命令类似
- tee 复制标隹输入到标准输出和指定的文件,和linux里的tee命令类似
- pwd 返回当前的工作目录,和linux命令类似
- cs 清空当前屏幕区域
- session 查看当前会话的信息
- reset 重置增强类,将被 Arthas增强过的类全部还原, Arthas服务端关闭时会重置所有增强过的类
- version 输出当前目标Java进程所加载的 Arthas版本号
- history 打印命令历史
- keymap Arthas快捷键列表及自定义快捷键
quit/exit 退出当前 Arthas客户端,其他 Arthas喜户端不受影响
stop/shutdown 关闭 Arthas服务端,所有 Arthas客户端全部退出
help 查看命令帮助信息
cat 打印文件内容,和linux里的cat命令类似
echo 打印参数,和linux里的echo命令类似
grep 匹配查找,和linux里的gep命令类似
tee 复制标隹输入到标准输出和指定的文件,和linux里的tee命令类似
pwd 返回当前的工作目录,和linux命令类似
cs 清空当前屏幕区域
session 查看当前会话的信息
reset 重置增强类,将被 Arthas增强过的类全部还原, Arthas服务端关闭时会重置所有增强过的类
version 输出当前目标Java进程所加载的 Arthas版本号
history 打印命令历史
keymap Arthas快捷键列表及自定义快捷键
- jvm相关
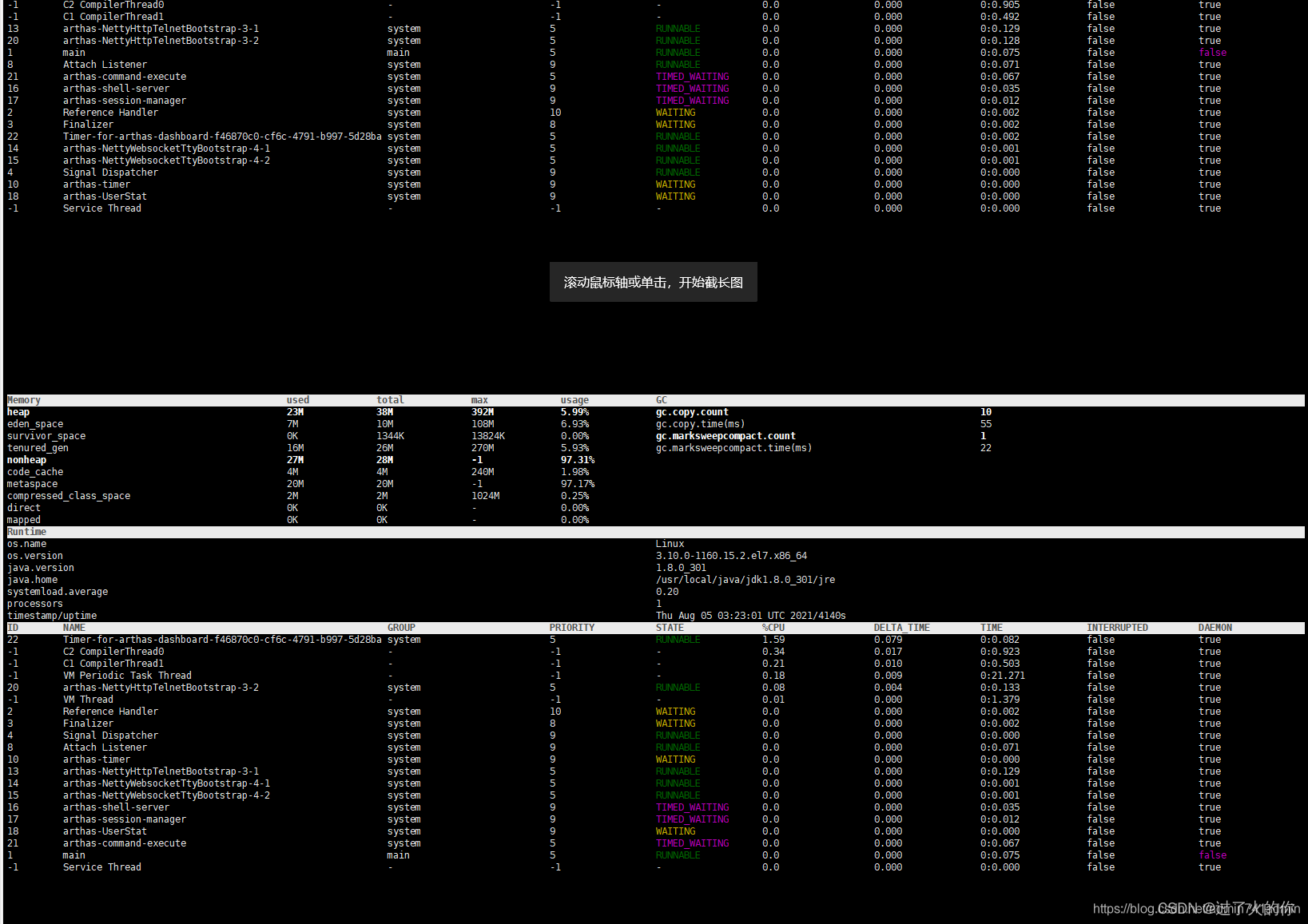
- dashboard 当前系统的实时数据面板
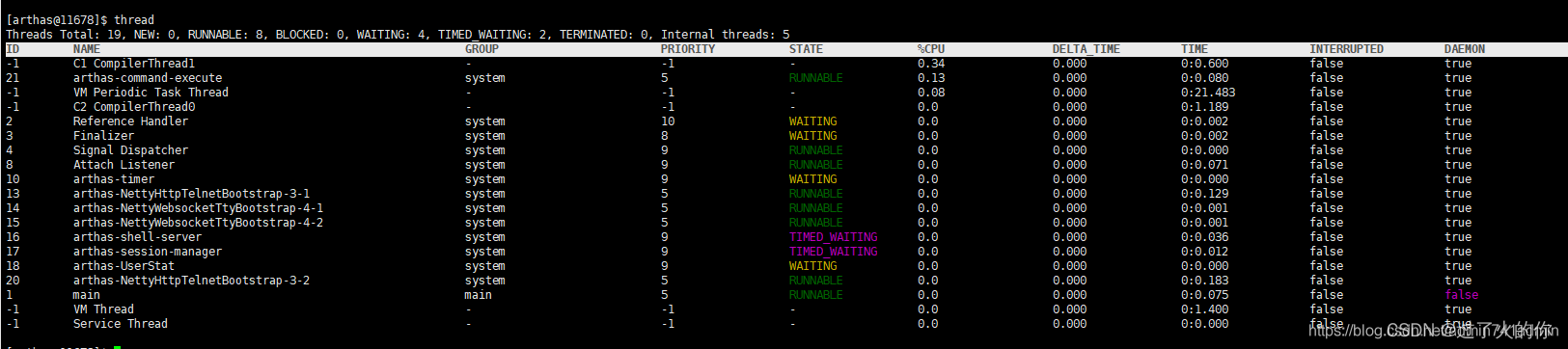
- thread 查看当前JVM的线程堆栈信息
- jvm 查看当前JVM的信息
- sysprop 查看和修改JVM的系统属性
- sysem 查看JVM的环境变量
- vmoption 查看和修改JVM里诊断相关的option
- perfcounter 查看当前JVM的 Perf Counter信息
- logger 查看和修改logger
- getstatic 查看类的静态属性
- ognl 执行ognl表达式
- mbean 查看 Mbean的信息
- heapdump dump java heap,类似jmap命令的 heap dump功能
- class/classloader相关
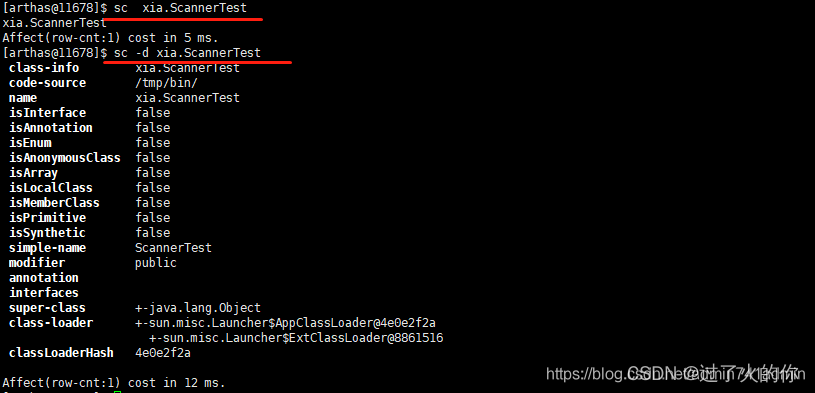
- sc 查看JVM已加载的类信息
- -d 输出当前类的详细信息,包括这个类所加载的原始文件来源、类的声明、加载的Classloader等详细信息。如果一个类被多个Classloader所加载,则会出现多次
- -E 开启正则表达式匹配,默认为通配符匹配
- -f 输出当前类的成员变量信息(需要配合参数-d一起使用)
- -X 指定输出静态变量时属性的遍历深度,默认为0,即直接使用toString输出
- sm 查看已加载类的方法信息
- -d 展示每个方法的详细信息
- -E 开启正则表达式匹配,默认为通配符匹配
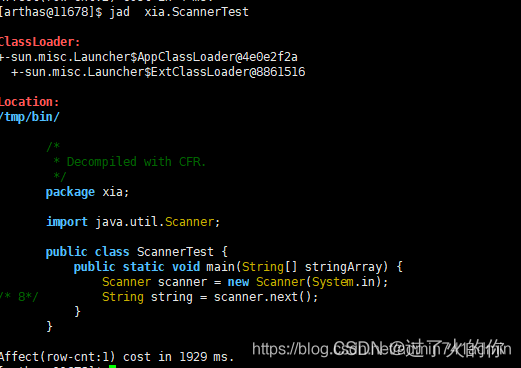
- jad 反编译指定已加载类的源码
- mc 内存编译器,内存编译.java文件为.class文件
- retransform 加载外部的.class文件, retransform到JVM里
- redefine 加载外部的.class文件,redefine到JVM里
- dump dump已加载类的byte code到特定目录
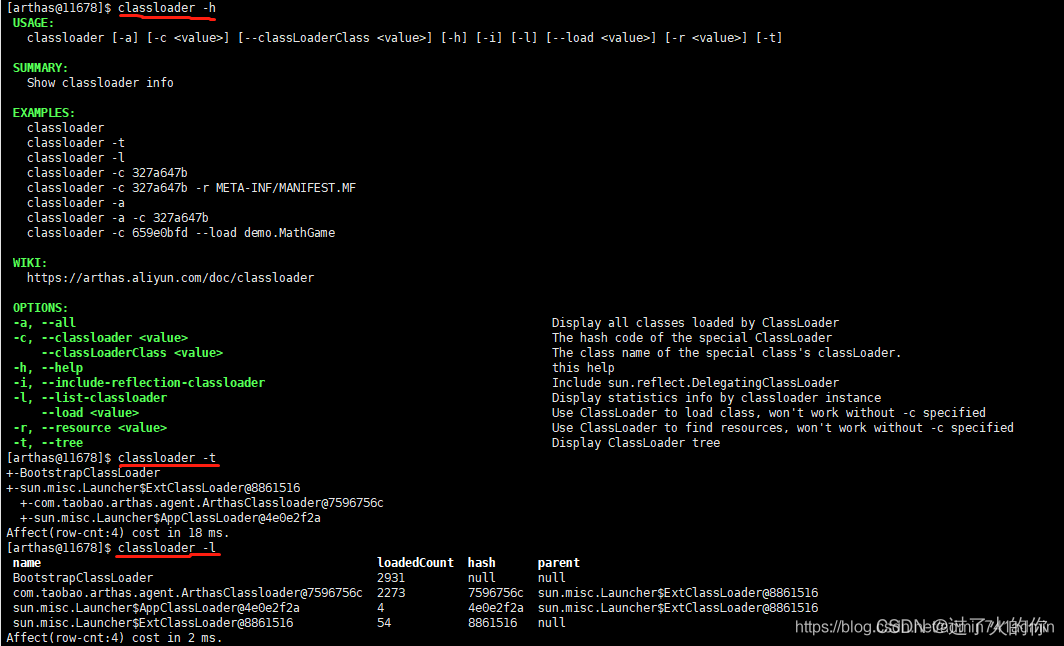
- classloader 查看classloader的继承树,urts,类加载信息,使用classloader去getResource
- -t 查看classloader的继承树
- -l 按类加载实例查看统计信息
- -c 用classloader对应的hashcode来查看对应的 Jar urls

4. monitor/watch/trace相关
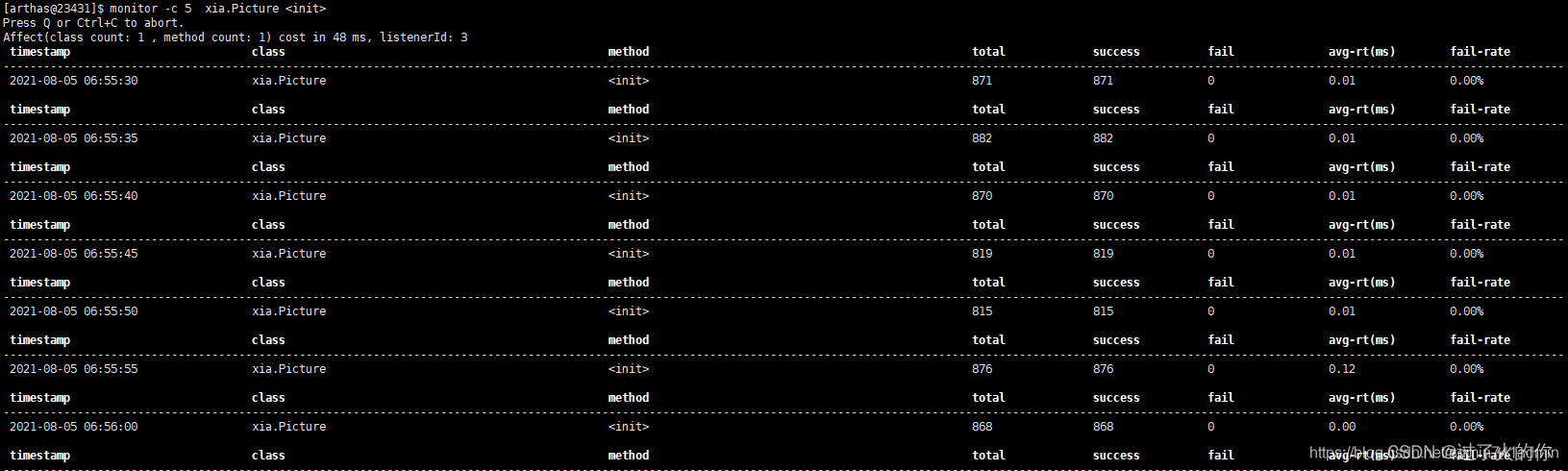
- monitor 方法执行监控,调用次数、执行时间、失败率
- -c 统计周期,默认值为120秒
- watch 方法执行观测,能观察到的范围为:返回值、抛出异常、入参,通过编写groovy表达式进行对应变量的查看
- -b 在方法调用之前观察(默认关闭)
- -e 在方法异常之后观察(默认关闭)
- -s 在方法返回之后观察(默认关闭)
- -f 在方法结束之后(正常返回和异常返回)观察(默认开启)
- -x 指定输岀结果的属性遍历深度,默认为0
- trace 方法内部调用路径,并输出方法路径上的每个节点上耗时
- -n 执行次数限制
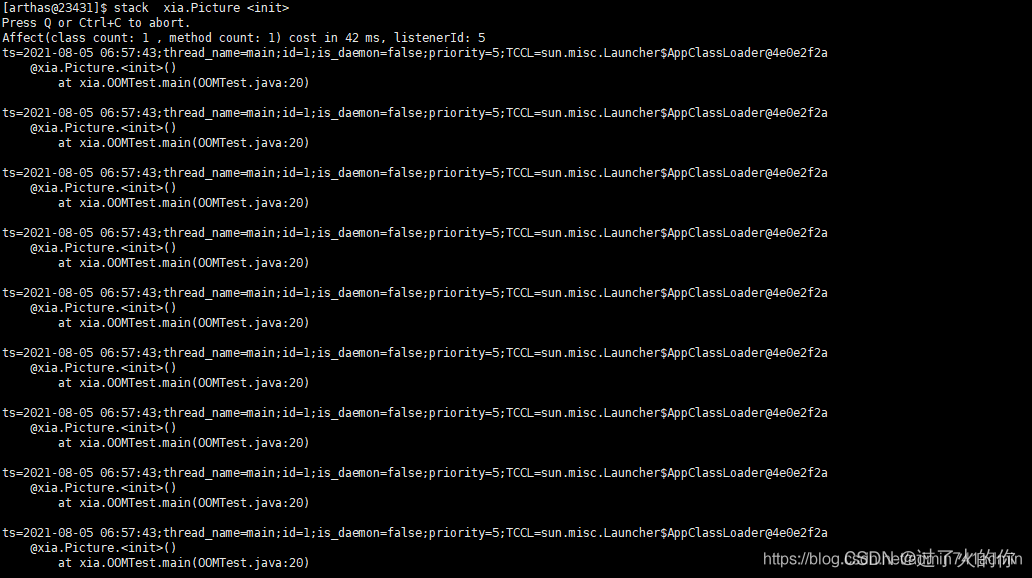
- stack 输出当前方法被调用的调用路径
- tt 方法执行数据的时空隧道,记录下指定方法每次调用的入参和返回信息,并能对这些不同的时间下调用进行观测
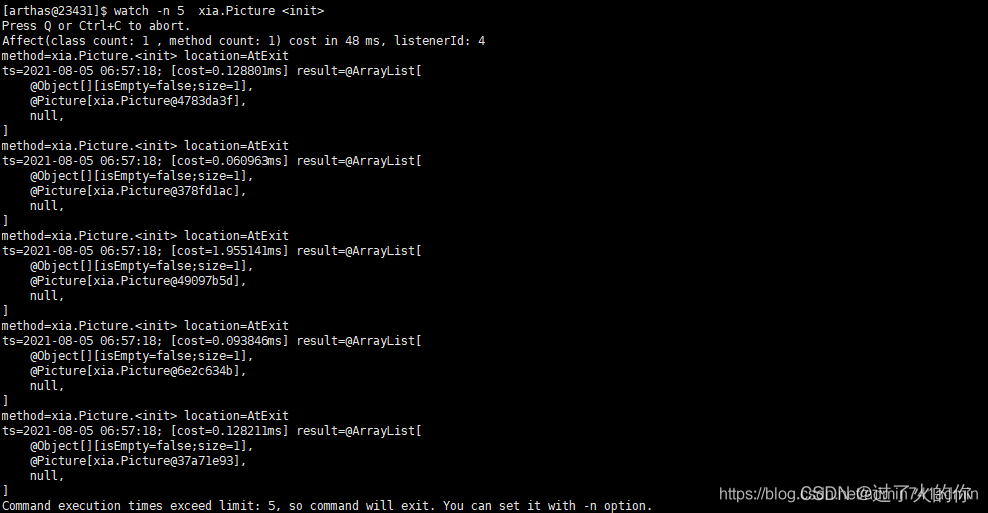
5. 其他
- jobs 列出所有job
- kill 强制终止任务
- fg 将暂停的任务拉到前台执行
- bg 将暂停的任务放到后台执行
- grep 搜索满足条件的结果
- plaintext 将命令的结果去除ANSI颜色
- wc 按行统计输出结果
- options 查看或设置Arthas全局开关
- profiler 使用async-profiler对应用采样,生成火焰图
- 默认情况下,arthas使用3658端口,则可以打开: http://localhost:3658/arthas-output/ 查看到arthas-output目录下面的profiler结果:
3.7 Java Mission Control
在Oracle收购Sun之前,Oracle的JRockit虚拟机提供了一款叫做 JRockit Mission Control 的虚拟机诊断工具。
在Oracle收购sun之后,Oracle公司同时拥有了Hotspot和 JRockit 两款虚拟机。根据Oracle对于Java的战略,在今后的发展中,会将JRokit的优秀特性移植到Hotspot上。其中一个重要的改进就是在Sun的JDK中加入了JRockit的支持。
在Oracle JDK 7u40之后,Mission Control这款工具己经绑定在Oracle JDK中发布。
自Java11开始,本节介绍的JFR己经开源。但在之前的Java版本,JFR属于Commercial Feature通过Java虚拟机参数-XX:+UnlockCommercialFeatures 开启。
Java Mission Control(简称JMC) , Java官方提供的性能强劲的工具,是一个用于对 Java应用程序进行管理、监视、概要分析和故障排除的工具套件。它包含一个GUI客户端以及众多用来收集Java虚拟机性能数据的插件如 JMX Console(能够访问用来存放虚拟机齐个于系统运行数据的MXBeans)以及虚拟机内置的高效 profiling 工具 Java Flight Recorder(JFR)。
JMC的另一个优点就是:采用取样,而不是传统的代码植入技术,对应用性能的影响非常非常小,完全可以开着JMC来做压测(唯一影响可能是 full gc 多了)。
官方地址:https://github.com/JDKMissionControl/jmc
Java Flight Recorder
Java Flight Recorder是JMC的其中一个组件,能够以极低的性能开销收集Java虚拟机的性能数据。与其他工具相比,JFR的性能开销很小,在默认配置下平均低于1%。JFR能够直接访问虚拟机内的敌据并且不会影响虚拟机的优化。因此它非常适用于生产环境下满负荷运行的Java程序。
Java Flight Recorder 和 JDK Mission Control共同创建了一个完整的工具链。JDK Mission Control 可对 Java Flight Recorder 连续收集低水平和详细的运行时信息进行高效、详细的分析。
当启用时 JFR将记录运行过程中发生的一系列事件。其中包括Java层面的事件如线程事件、锁事件,以及Java虚拟机内部的事件,如新建对象,垃圾回收和即时编译事件。按照发生时机以及持续时间来划分,JFR的事件共有四种类型,它们分别为以下四种:
- 瞬时事件(Instant Event) ,用户关心的是它们发生与否,例如异常、线程启动事件。
- 持续事件(Duration Event) ,用户关心的是它们的持续时间,例如垃圾回收事件。
- 计时事件(Timed Event) ,是时长超出指定阈值的持续事件。
- 取样事件(Sample Event),是周期性取样的事件。
取样事件的其中一个常见例子便是方法抽样(Method Sampling),即每隔一段时问统计各个线程的栈轨迹。如果在这些抽样取得的栈轨迹中存在一个反复出现的方法,那么我们可以推测该方法是热点方法


3.8 其他工具
3.8.1 Flame Graphs(火焰图)
在追求极致性能的场景下,了解你的程序运行过程中cpu在干什么很重要,火焰图就是一种非常直观的展示CPU在程序整个生命周期过程中时间分配的工具。火焰图对于现代的程序员不应该陌生,这个工具可以非常直观的显示出调用找中的CPU消耗瓶颈。

火焰图,简单通过x轴横条宽度来度量时间指标,y轴代表线程栈的层次。
3.8.2 Tprofiler
案例: 使用JDK自身提供的工具进行JVM调优可以将下 TPS 由2.5提升到20(提升了7倍),并准确 定位系统瓶颈。
系统瓶颈有:应用里释态对象不是太多、有大量的业务线程在频繁创建一些生命周期很长的临时对象,代码里有问题。
那么,如何在海量业务代码里边准确定位这些性能代码?这里使用阿里开源工具 Tprofiler 来定位 这些性能代码,成功解决掉了GC 过于频繁的性能瓶预,并最终在上次优化的基础上将 TPS 再提升了4倍,即提升到100。
Tprofiler配置部署、远程操作、 日志阅谈都不太复杂,操作还是很简单的。但是其却是能够 起到一针见血、立竿见影的效果,帮我们解决了GC过于频繁的性能瓶预。
Tprofiler最重要的特性就是能够统汁出你指定时间段内 JVM 的 top method 这些 top method 极有可能就是造成你 JVM 性能瓶颈的元凶。这是其他大多数 JVM 调优工具所不具备的,包括 JRockit Mission Control。JRokit 首席开发者 Marcus Hirt 在其私人博客《 Lom Overhead Method Profiling cith Java Mission Control》下的评论中曾明确指出 JRMC 井不支持 TOP 方法的 统计。
官方地址:http://github.com/alibaba/Tprofiler
3.8.3 Btrace
常见的动态追踪工具有BTrace、HouseHD(该项目己经停止开发)、Greys-Anatomy(国人开发 个人开发者)、Byteman(JBoss出品),注意Java运行时追踪工具井不限干这几种,但是这几个是相对比较常用的。
BTrace是SUN Kenai 云计算开发平台下的一个开源项目,旨在为java提供安全可靠的动态跟踪分析工具。先看一卜日Trace的官方定义:

大概意思是一个 Java 平台的安全的动态追踪工具,可以用来动态地追踪一个运行的 Java 程序。BTrace动态调整目标应用程序的类以注入跟踪代码(“字节码跟踪“)。