hadoop入门--一小时带你搭建hadoop集群
概念
hadoop是什么
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
- 主要解决,海量数据的存储和海量数据的分析计算问题。
- 广义上来说,Hadoop通常是指一 个更广泛的概念 ——Hadoop生态圈。
发展历史
- Hadoop创始 人Doug Cutting, 为了实现与 Google类似 的全 文搜 索功 能, 他在 Lucene框架 基础 上进 行优 化升级,查询引擎和索引引擎。
- 2001年年底Lucene成为 Apache基金会的一个子项目。
- 对 于 海 量 数据 的 场 景,Lucene框架面对与Google同样的困难,存储海量 数据困难 , 检索海量速 度慢。
- 学习和模仿Google解决这些问 题的办法 :微型版Nutch。
- 可以说Google是Hadoop的思想之 源( Google在大数据方面的三篇论文)
- GFS–> HDFS
- Map-Reduce–>MR
- BigTable–>HBase
- 2003-2004年,Google公开了部分GFS和MapReduce思想的细节,以此为基础Doug Cutting等人用 了2年业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。
- 2005 年Hadoop 作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。
- 2006 年 3 月份,Map-Reduce和Nutch Distributed File System (NDFS)分别被纳入到 Hadoop 项目 中,Hadoop就此正式诞生,标志着大数据时代来临。
- 名字来源于Doug Cutting儿子的玩具大象
三大发行版本
Hadoop 三大发行版本:Apache、Cloudera、Hortonworks。
- Apache 版本最原始(最基础)的版本,对于入门学习最好。2006
- Cloudera 内部集成了很多大数据框架,对应产品 CDH。2008
- Hortonworks 文档较好,对应产品 HDP。2011
- Hortonworks 现在已经被 Cloudera 公司收购,推出新的品牌 CDP。
优势
-
高可靠性:Hadoop底层维护多个数据副本 ,所以即使 Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
-
高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
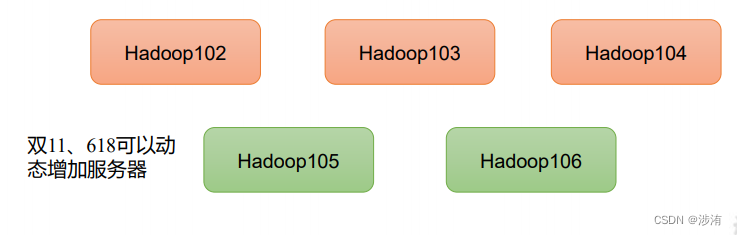
-
高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6sPWclkM-1678794504451)(入门.assets/image-20230226201521861.png)]](/uploadfile/202406/acc2834a0e27947.png)
-
高容错性:能够自动将失败的任务重新分配。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J5mXLAdc-1678794504453)(入门.assets/image-20230226201531254.png)]](/uploadfile/202406/40f68bd31d0078e.png)
组成
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ONhKLuPr-1678794504454)(入门.assets/image-20230226201709359.png)]](https://img-blog.csdnimg.cn/224d16784b58487cb0865f704ebe42e6.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4TjAOjTw-1678794504455)(入门.assets/image-20230226201722514.png)]](/uploadfile/202406/175a44001f30253.png)
- 在 Hadoop1.x 时代,Hadoop中的MapReduce同 时处理业务逻辑运算和资源的调度,耦合性较大。
- 在 Hadoop2.x时代,增加了Yarn .Yarn只负责资源调度MapReduce只负责运算 。
- Hadoop3.x 在组成上没有变化。
HDFS架构概述
Hadoop Distributed File System,简称 HDFS,是一个分布式文件系统。
NameNode(nn):存储文件的元数据,如文件名 ,文件目录结构 ,文件属性(生成时间 、副本数 、 文件权限),以及每个文件的块列表和块所在的DataNode等。
DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和
Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份
YARN 架构概述
Yet Another Resource Negotiator 简称 YARN ,另一种资源协调者,是 Hadoop 的资源管理器。
ResourceManager(RM):整个集群资源(内存、CPU等)的老大
NodeManager(NM):单个节点服务器资源老大
ApplicationMaster(AM):单个任务运行的老大
Container:容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HxNacNR6-1678794504456)(入门.assets/image-20230226202800107.png)]](/uploadfile/202406/172e8b78b960745.png)
说明1:客户端可以有多个
说明2:集群上可以运行多个ApplicationMaster
说明3:每个NodeManager上可以有多个Container
MapReduce 架构概述
MapReduce 将计算过程分为两个阶段:Map 和 Reduce
- Map 阶段并行处理输入数据
- Reduce 阶段对 Map 结果进行汇总
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3G9ii8mf-1678794504457)(入门.assets/image-20230226203025538.png)]](/uploadfile/202406/263fcf35ec8c42f.png)
以康师傅找资源为案例,康师傅需要某个资源,但是并不知道资源在哪个服务器上,这时可以调用所有服务器,并且汇总服务器的结果,得到需要的资源
三者的关系
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hJ82Bfk6-1678794504457)(入门.assets/image-20230226204004791.png)]](/uploadfile/202406/6bb4c92c9f6d53d.png)
大数据生态体系
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OzsZLtzN-1678794504458)(入门.assets/image-20230309145032864.png)]](/uploadfile/202406/22b75faf55fd7a7.png)
Sqoop:Sqoop 是一款开源的工具,主要用于在 Hadoop、Hive 与传统的数据库(MySQL) 间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进 到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。Flume:Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据;Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统;Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于 Hadoop 上存储的大数据进行计算。Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。Oozie:Oozie 是一个管理 Hadoop 作业(job)的工作流程调度管理系统。Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库,
它是一个适合于非结构化数据存储的数据库。Hive:Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张 数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运 行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开发专门的 MapReduce 应用,十分适合数据仓库的统计分析。ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
推荐系统案例
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hGg6Dl54-1678794504458)(入门.assets/image-20230309145518754.png)]](/uploadfile/202406/b74c4b55a5e065f.png)
环境配置
模板虚拟机准备
安装一台linux虚拟机
克隆
完全克隆四台虚拟机,并修改hostname以及ip地址
安装jdk,hadoop
Jdk
解压
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
环境变量
打开/etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
读取环境变量
source /etc/profile
检测
Java -version
hadoop
解压
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
配置环境变量
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
读取环境变量
source /etc/profile
测试
hadoop version
hadoop目录结构
[root@hadoop102 bin]# ll
总用量 996
-rwxr-xr-x. 1 fate fate 441936 9月 12 2019 container-executor
-rwxr-xr-x. 1 fate fate 8707 9月 12 2019 hadoop
-rwxr-xr-x. 1 fate fate 11265 9月 12 2019 hadoop.cmd
-rwxr-xr-x. 1 fate fate 11026 9月 12 2019 hdfs
-rwxr-xr-x. 1 fate fate 8081 9月 12 2019 hdfs.cmd
-rwxr-xr-x. 1 fate fate 6237 9月 12 2019 mapred
-rwxr-xr-x. 1 fate fate 6311 9月 12 2019 mapred.cmd
-rwxr-xr-x. 1 fate fate 483728 9月 12 2019 test-container-executor
-rwxr-xr-x. 1 fate fate 11888 9月 12 2019 yarn
-rwxr-xr-x. 1 fate fate 12840 9月 12 2019 yarn.cmd说明:
bin目录:存放对 Hadoop 相关服务(hdfs,yarn,mapred)进行操作的脚本etc目录:Hadoop 的配置文件目录,存放 Hadoop 的配置文件lib目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)sbin目录:存放启动或停止 Hadoop 相关服务的脚本share目录:存放 Hadoop 的依赖 jar 包、文档、和官方案例
生产集群搭建
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nN6i2xaj-1678794504459)(入门.assets/image-20230312115555694.png)]](/uploadfile/202406/c737245f84b491b.png)
本地模式(wordcount案例)
-
在hadoop文件夹下创建wcinput文件夹
mkdir wcinput -
在wcinput下创建word.txt文件
vim word.txt -
编写文件内容
hadoop yarn hadoop mapreduce fate fate -
返回hadoop文件夹
-
执行hadoop案例
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput/ ./wcoutput -
查看输出路径我们会发现两个文件:
_SUCCESS与part-r-00000其中_SUCCESS仅仅只是成功的标志,正在的结果存储在part-r-00000中[root@hadoop102 wcoutput]# cat part-r-00000 fate 2 haaoop 1 hadoop 1 mapreduce 1 yarn 1
完全分布式集群(‼)
集群分发脚本xsync
scp(secure copy)安全拷贝
基本语法
scp -r $pdir/$fname $user@$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
rsync 远程同步工具
rsync 主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync 和 scp 区别:用 rsync 做文件的复制要比 scp 的速度快,rsync 只对差异文件做更新。scp 是把所有文件都复制过去。
基本语法:
rsync -av $pdir/$fname $user@$host:$pdir/$fname
命令 参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
选项参数说明
| 选项 | 功能 |
|---|---|
| -a | 归档拷贝 |
| -v | 显示复制过程 |
xsync集群脚本分发
-
需求:循环复制文件到所有节点的相同目录下
-
需求分析:
rsync 命令原始拷贝
期望脚本:
xsync 要同步的文件名称
期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径)
-
脚本实现
在/home/atguigu/bin 目录下创建 xsync 文件
#!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ]; thenecho Not Enough Arguement!exit fi #2. 遍历集群所有机器 for host in hadoop102 hadoop103 hadoop104; doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@; do#4. 判断文件是否存在if [ -e $file ]; then#5. 获取父目录pdir=$(cd -P $(dirname $file)pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone done修改脚本xsync具有执行权限
chomd +x xsync测试脚本
xsync /home/atguigu/bin将脚本复制到bin中,方便全局调用
sudo cp xsync /bin/同步环境变量配置
sudo ./bin/xsync /etc/profile.d/my_env.sh重载环境变量
source /etc/profile
ssh免密登陆
基本语法
ssh 另一台电脑的 IP 地址
无密钥配置
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GXhBnDne-1678794504459)(入门.assets/image-20230312142910629.png)]](/uploadfile/202406/26f78b5bdcef54a.png)
-
生成公钥和私钥
ssh-keygen -t rsa -
拷贝公钥
ssh-copy-id ip地址
注意:
还需要在 hadoop103 上采用 atguigu 账号配置一下无密登录到 hadoop102、hadoop103、 hadoop104 服务器上。
还需要在 hadoop102 上采用 root 账号,配置一下无密登录到 hadoop102、hadoop103、 hadoop104;
集群配置
集群规划
NameNode 和 SecondaryNameNode 不要安装在同一台服务器
ResourceManager 也很消耗内存,不要和 NameNode、SecondaryNameNode 配置在同一台服务器
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
配置文件说明
Hadoop 配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
默认配置文件:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pzHs3uAA-1678794504460)(入门.assets/image-20230312152936035.png)]](/uploadfile/202406/ddf1e2119fbae52.png)
自定义配置文件:
core-site.xml 、hdfs-site.xml、 yarn-site.xml 、 mapred-site.xml 四 个 配 置 文 件 存 放 在 $HADOOP_HOME/etc/hadoop 这个路径上,用户可以根据项目需求重新进行修改配置。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iCRJgAbB-1678794504461)(入门.assets/image-20230312153524142.png)]](/uploadfile/202406/ba0f9b5951befba.png)
配置集群
核心配置文件core-site.xml
fs.defaultFS hdfs://hadoop102:8020 hadoop.tmp.dir /opt/module/hadoop-3.1.3/data hadoop.http.staticuser.user fate HDFS配置hdfs-site.xml
dfs.namenode.http-address hadoop102:9870 dfs.namenode.secondary.http-address hadoop104:9868 YARN配置文件yarn-site.xml
yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname hadoop103 yarn.nodemanager.env-whitelist JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME MapReduce配置文件mapred-site.xml
mapreduce.framework.name yarn 分发配置文件
xsync /opt/module/hadoop-3.1.3/etc/hadoop
群起集群
配置works
vim /opt/moduble/hadoop-3.13/etc/hadoop/workers
添加以下内容
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
启动集群
如果集群是第一次启动,需要在 hadoop102 节点格式化 NameNode(注意:格式 化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs目录
然后再进行格式化。)
启动HDFS
sbin/start-dfs.sh
在ResourceManager 的节点(103)启动YARN
sbin/start-yarn.sh
web服务器查看HDFS的NameNode=>http://namenode_ip:9870
Web 端查看 YARN 的 ResourceManager=>http://ResourceManager:8088
集群测试
-
上传文件:
#上传小文件 #在hadoop创建目录 hadoop fs -mkdir /input #上传文件 hadoop fs -put /$HADOOP_HOME/wcinput/word.txt /input #上传大文件 hadoop fs -put /opt/software/jdk*****.tar.gz -
下载
hadoop fs -get /jdk****.tar.gz ./ -
测试wordcount程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
-
配置
mapred-site.xmlmapreduce.jobhistory.address hadoop102:10020 mapreduce.jobhistory.webapp.address hadoop102:19888 -
分发配置
-
在namenode(102)启动历史服务器
mapred --daemon start historyserver -
查看服务是否启动
jps -
访问
http://hadoop102:19888/jobhistory![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h6uuhTbq-1678794504461)(入门.assets/image-20230312213219133.png)]](/uploadfile/202406/d82812d9855775e.png)
配置日志聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-56K9vAtD-1678794504461)(入门.assets/image-20230312211404349.png)]](/uploadfile/202406/bc4369acd4e6f6f.png)
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意: 开 启 日 志 聚 集 功 能 , 需要重 新 启 动 NodeManager 、ResourceManager 和 HistoryServer。
开启日志聚集功能具体步骤如下:
-
配置
yarn-site.xmlyarn.log-aggregation-enable true yarn.log.server.url http://hadoop102:19888/jobhistory/logs yarn.log-aggregation.retain-seconds 604800 -
分发配置
-
关闭
NodeManager、ResourceManager和HistoryServersbin/stop-yarn.sh mapred --daemon stop historyserver -
启动 NodeManager 、ResourceManage 和 HistoryServer
start-yarn.sh mapred --daemon start historyserver -
移除输出文件,并执行测试程序
-
查看日志
http://hadoop102:19888/jobhistory
集群启动停止方式总结
各个模块分开启动
各个模块分开启动/停止HDFS
start-dfs.sh/stop-dfs.sh
整天启动/停止YARN
start-yarn.sh/stop-yarn.sh
各个服务组件逐一启动/停止
分别启动/停止 HDFS 组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
启动/停止 YARN
yarn --daemon start/stop resourcemanager/nodemanager
编写 Hadoop 集群常用脚本
Hadoop 集群启停脚本myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]; thenecho "No Args Input..."exit
fi
case $1 in
"start")echo " =================== 启动 hadoop 集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start
historyserver";;
"stop")echo " =================== 关闭 hadoop 集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop
historyserver"echo " --------------- 关闭 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh";;
*)echo "Input Args Error...";;
esac
查看进程脚本jpsall
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104; doecho =============== $host ===============ssh $host jps
done
常用端口号说明
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tkemwl6s-1678794504462)(入门.assets/image-20230312212459141.png)]](/uploadfile/202406/57f28e145698afe.png)
常见错误处理方案
-
防火墙没关闭、或者没有启动 YARN
INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032 -
主机名称配置错误
-
IP 地址配置错误
-
ssh 没有配置好
-
root 用户和 atguigu 两个用户启动集群不统一
-
配置文件修改不细心
-
不识别主机名称
java.net.UnknownHostException: hadoop102: hadoop102 at java.net.InetAddress.getLocalHost(InetAddress.java:1475) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(Job Submitter.java:146) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415)解决办法:
- 在/etc/hosts 文件中添加 192.168.10.102 hadoop102
- 主机名称不要起 hadoop hadoop000 等特殊名称
-
DataNode 和 NameNode 进程同时只能工作一个。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ajbj6SlZ-1678794504463)(入门.assets/image-20230312212702584.png)]](/uploadfile/202406/b37372c5b314ec0.png)
-
执行命令不生效,粘贴 Word 中命令时,遇到-和长–没区分开。导致命令失效
-
jps 发现进程已经没有,但是重新启动集群,提示进程已经开启。
原因是在 Linux 的根目录下/tmp 目录中存在启动的进程临时文件,将集群相关进程删除掉,再重新启动集群。
-
jps 不生效
原因:全局变量 hadoop java 没有生效。解决办法:需要 source /etc/profile 文件